Word2vec
28 Sep 2020 DLWord2vec
: 본 포스팅은, 쉽게 씌어진 word2vec 블로그를 공부하며 정리하기 위해 작성되었습니다.
1. 단어 -> 숫자
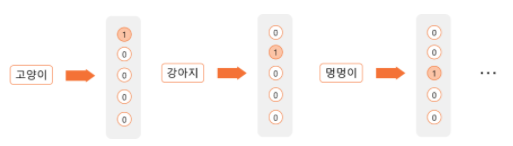
1) one hot encoding
: 각 단어를 하나의 Feature로 활용해, 해당 단어가 속하는 Feature에만 1을 매기며, 나머지는 0으로 채우는 방법
- 장점 : 표현이 쉬움.
- 단점 : 단어와 단어간 관계가 전혀 드러나지 않음
- e.g. ‘강아지’ & ‘멍멍이’ 두 단어는 사실상 유사한 단어이나, 서로 다른 독립적인 feature로 인식됨
=> 단어와 단어간 관계를 벡터 공간상 위치로 표현하기 위한 시도 등장 => *‘word embedding model
2) Embedding test
단어를 벡터간 위치값으로 변환시, 덧셈 & 뺄셈이 가능해짐. 위 사이트에서 단어와 단어를 빼거나 더했을 때 벡터간 위치의 변화로 인해 어떻게 의미가 변화하는지 경험해 볼 수 있음(e.g. “한국 - 서울 + 도쿄 = 일본”)
2. Sparse vs Dense Representatios
- feature representation : 대상을 표현 하는 방식으로, 자연어 처리의 경우 특정 ‘텍스트’를 판단하기 위해 해당 단어와 함께 등장하는 단어, 단어의 길이, 단어의 위치, 함께 쓰인 품사 등이 특정 ‘텍스트’를 표현하고 있는 언어적 정보가 될 수 있다. 이같은 속성에는 크게 Sparse representation과 dense representation으로 존재.
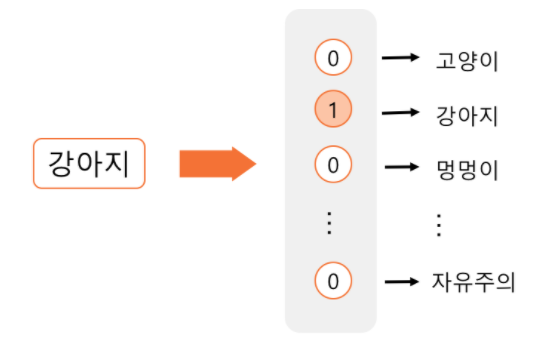
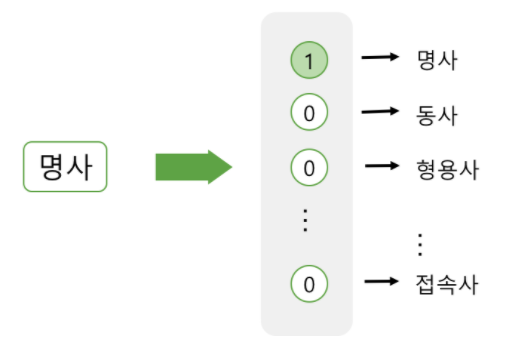
1) Sparse representation
: one hot encoding or dummy variable,
- 단어의 표현 : 표현해야 하는 단어의 수 N개일 때 -> N차원의 벡터 생성 후 해당 단어에만 1표시
- 품사의 표현 : 모든 품사의 개수 만큼의 차원 생성 -> ‘명사’에 해당하는 벡터의 요소값만 1표시
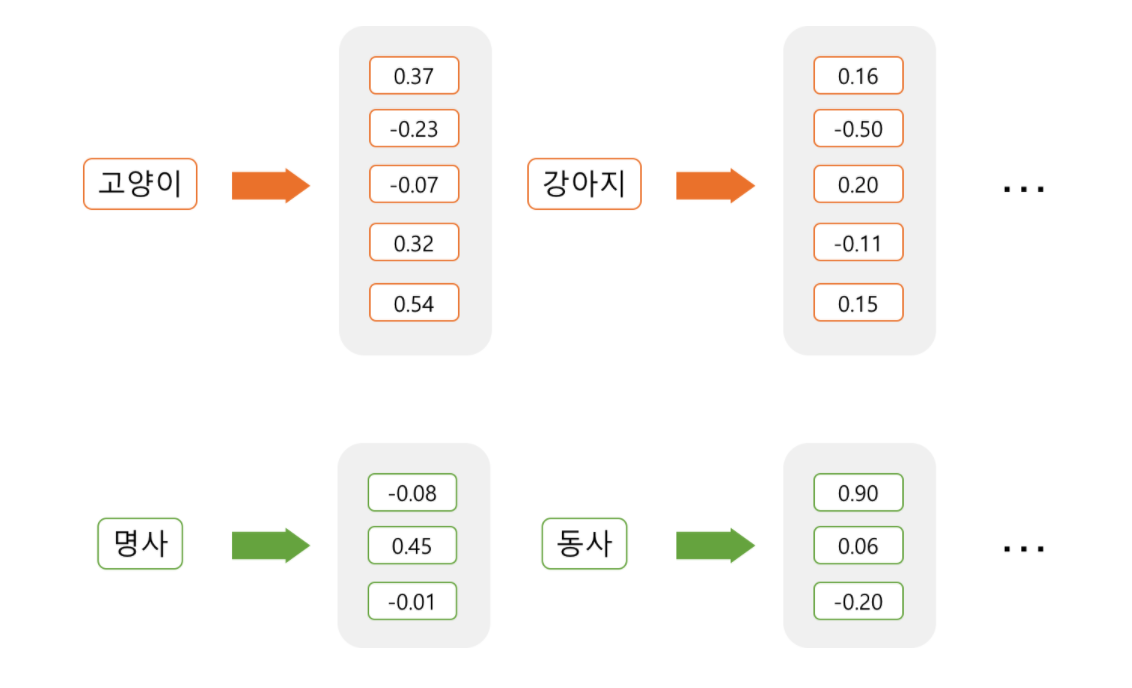
2) Dense representation : Embedding
: 설정한 차원의 개수로 특정 단어를 대응시켜 표현. 이때 각 단어를 주어진 차원에 어떻게 표현할 것인지를 학습. 이렇게 임베딩된 단어는 설정된 각 차원에 값을 갖고 있기에 더이상 sparse하지 않고 모든 열에 값이 채워지며 아래 방식으로 불림.
- 값이 채워져 있음: “Dense”
- 각 차원에 단어의 의미가 분산 됨 : “Distributed”
3. Dense Representation의 장점
(1) 차원이 저주 방지
- 적은 차원으로 대상 표현 가능하며, 0으로만 채워져 있지도 않음.
(2) 일반화 능력 (Generalization power)
ex) ‘강아지’ 자주 등장 / ‘멍멍이’ 적게 등장 시
- [Sparse] ‘강아지’와 ‘멍멍이’간의 관계에 대해서 전혀 표현되지 않기에 ‘강아지’는 학습이 되어도, ‘멍멍이’는 학습되지 않음
- [Dense] ‘강아지’와 ‘멍멍이’ 유사한 맥락하에 등장하기에, 입력값이 유사하고, ‘강아지’로 학습된 모델에 ‘멍멍이’가 입력될 시 서로 동일한 아웃풋을 갖을 수 있음.
4. word2vec 핵심 아이디어@
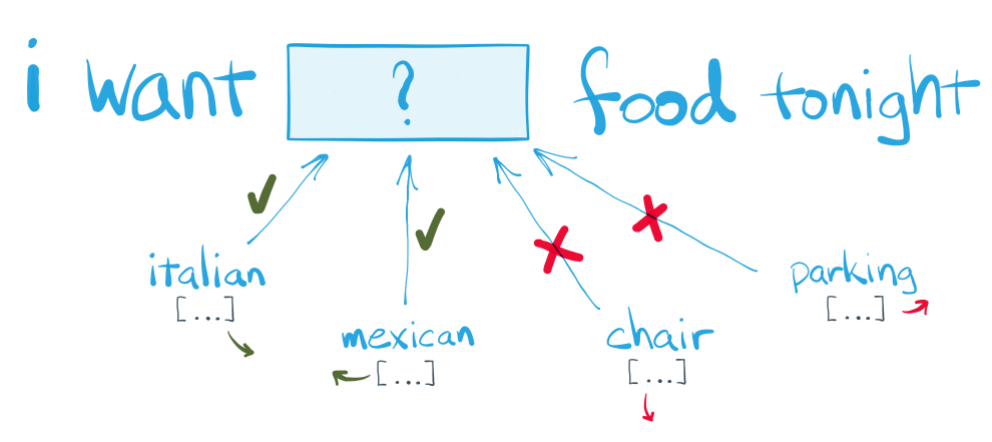
: “단어의 주변을 보면 그 단어를 안다.”
 위 문장에서 food와 어울리는 단어는 빈칸에 들어가도 되지만, chair & parking등은 어색함.
-> 비슷한 맥락을 갖는 단어는 비슷한 벡터를 부여
위 문장에서 food와 어울리는 단어는 빈칸에 들어가도 되지만, chair & parking등은 어색함.
-> 비슷한 맥락을 갖는 단어는 비슷한 벡터를 부여
- word2vec -> predictive method 방식
: 맥락으로 단어를 예측 / 단어로 맥락을 예측
- Unsupuervised learning
: 어떤 단어와 어떤 단어가 비슷한지 주어진 문장을 토대로 스스스로 학습
5. Algorithm of word2Vec
1) CBOW(Continuous Bag of Words): 맥락으로 단어 예측
2) Skip-gram(Continuous Bag of Words): 단어로 맥락을 예측
(1) CBOW
: 주변 단어로 타겟 단어를 예측하는 방법으로, 주변 단어를 인풋(X)으로 넣어가며, 파라미터를 학습해 타겟 단어를 벡터방식으로 표현
(a) 구성
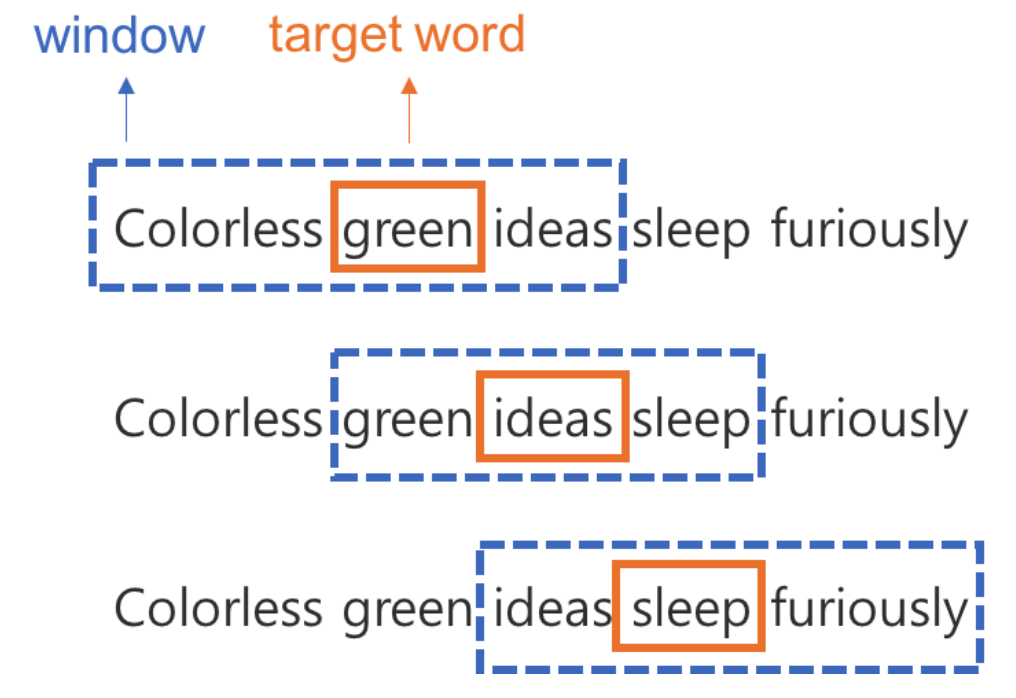
- Window : 주변 단어, 맥락(Context)
- Window Size : 앞 & 뒤 몇개의 단어를 살펴볼 것인가
- Target word : 타겟 단어 <img src = '/assets/DL/word2vec/word2vec_OHE_7.png' width = '50%'>
(b) 학습 방식
-
- Sliding Window
- window를 옆으로 밀면서, target 단어를 하나씩 바꿔가는 방식으로, 모든 단어에 대해서 학습해 나감
-
- backpropagation & gradient descent
- 딥러닝 방식과 동일하게, 랜덤하게 초기화(random initialization)된 파라미터로 시작하여, 이 파라미터로 예측한 값이 틀릴 경우, 오차를 수정하는 과정을 반복(backpropagation & gradient descent)
(c) 의의
: 주변 단어가 입력값이 될때, 타겟 단어가 서로 다르더라도 주변 단어의 입력값이 서로 유사하다면, 해당 타겟 단어들은 서로 유사한 벡터값을 지정받게 될 것이며, 이는 벡터간 거리가 짧다는 의미가 된다.
6. Mathmatical meaning of word2Vec
- 문맥(input)을 바로 앞 단어 하나라고 가정(window size = 1)
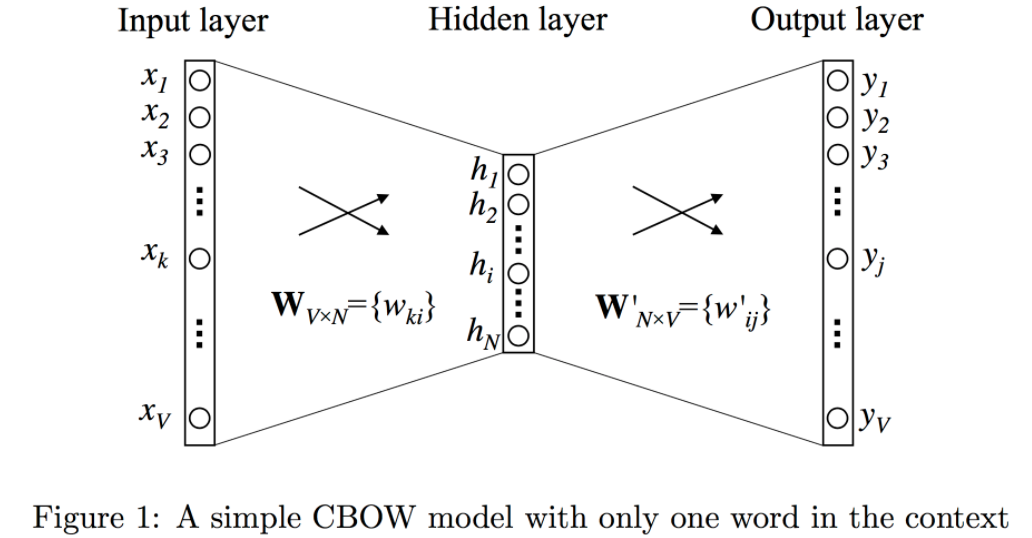
- V : 사전의 크기(vocabulary size) => 단어의 개수
- N : 히든 레이어 크기(hiddn layer size) => 몇차원으로 임베딩할 지의 크기(embedding size)
Step 1 : Input layer x = [1xV]
: OneHotEncoding된 벡터로, 타겟 단어의 앞 단어는 v개의 요소 중 단 하나의 요소만 1, 나머지는 모두 0인 1xV차원의 벡터입니다.
Step 2 : $W$ (Weight between input & hidden layer) W = [VxN]
: 위에서 받은 OHE형태의 Input 행렬은 설정된 임의의 크기(N)의 hidden layer로 투영(projection)되기 위해 W행렬($W_{V*N}$)과 곱해집니다.
Step 3 : Hidden layer h = [1xN]
: Input 행렬에 $W_{V*N}$ 곱해져 1xN 차원의 embedding된 행렬입니다.
Step 4 : $W’$(Weight between hidden & output layer) W' = [NxV]
: 임베딩된 행렬을 토대로, 최종 Output값이 무엇인지 출력하기 위한 가중치행렬입니다.(학습대상2)
Step 5 : Output layer y = 1XV
: 출력은 타겟 단어로, 타겟 단어 바로 앞의 단어가 등장했을 때, 다음으로 등장할 수 있는 모든 단어 v개의 점수이며, 여기에 soft-max를 취해 확률값으로 변환됩니다.
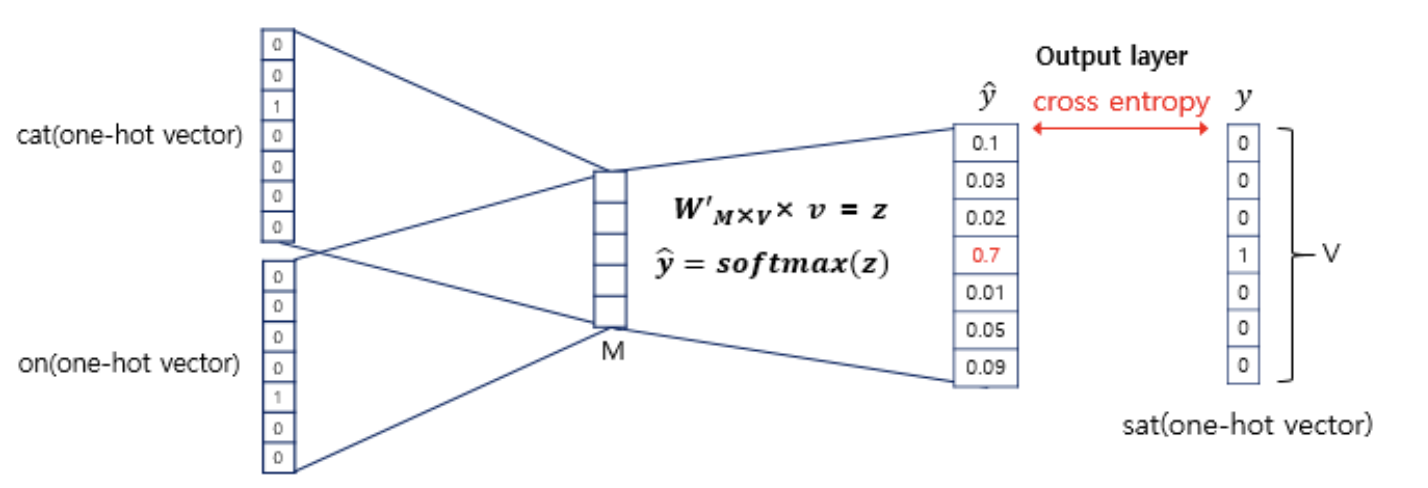 그리고, 계산된 스코어 벡터를 실제 타겟 단어값을 기준으로 OHE된 행렬과 비교하여, 그 차이를 줄이는 방식으로 가중치 행렬($W, W'$)을 학습합니다.
그리고, 계산된 스코어 벡터를 실제 타겟 단어값을 기준으로 OHE된 행렬과 비교하여, 그 차이를 줄이는 방식으로 가중치 행렬($W, W'$)을 학습합니다.
Reference
[1] 쉽게 씌어진 word2vec
[2] 위키독스 : 워드투벡터(Word2Vec)
[3] 한국어 Word2Vec