Recommend 1_Intro
24 Jul 2020 ML1. 추천 알고리즘 종류
1) Contents Based Filtering : 유저 및 아이템의 정보를 기반해 추천해주는 방식으로, 유저(또는 아이템)의 나이, 성별 등을 토대로 유사한 유저를 찾고 해당 유저의 관람 이력을 추천해준다. 이때 유사도를 확인하기 위해 코사인 유사도, 자카드 유사도등을 활용할 수 있다.
2) Collaborative Filtering : 실제 행동을 기반으로 추천하는 모델로, 컨텐츠 베이스보다 높은 성능을 보인다. 그러나 행동 데이터가 축적되기전에는 정확도가 떨어진다는 “cold-start” 문제를 갖고 있다.
- 최근접 이웃 기반(nearest neighbor based collaborative filtering)
- 잠재요인 협업 필터링 (latent factor based collaborative filtering) - SVD
※ Deep Learning을 활용한 방식이 최근 핫하지만, 여기선 기초적인 추천시스템 내용의 정리를 위해 배제하였다.
<데이터 종류>
Explict Data
- 평점등 선호와 비선호가 명확하게 구분
- 아직 평점을 매기지 않은 데이터는 활용불가
Impolicit Data
- 선호와 비선호 구분없이 행동의 빈도수만 기록
- 모든 데이터를 사용하여 분석 가능 —
2. Contents Based Filtering
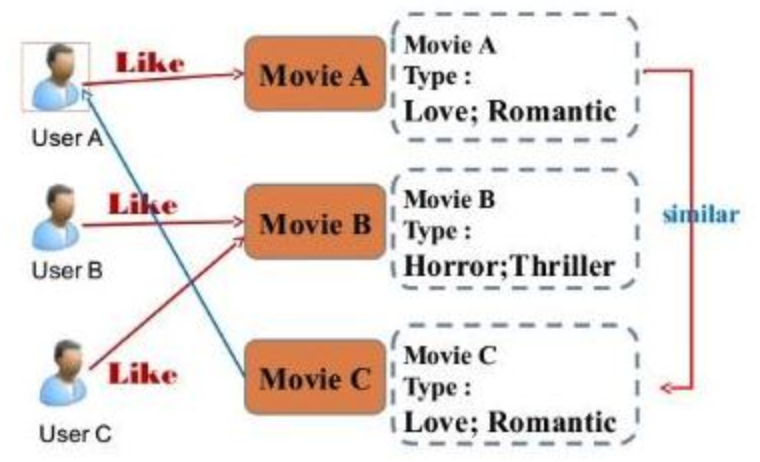
: 위 그림 처럼 예를들어 ‘장르’라는 변수를 활용해 비슷한 영화를 묶고, 동일한 장르내에서 유사한 영화를 추천해줄 수 있다.
3. Collaborative Filtering
3-1. Neighborhood CF Model
: 주어진 평점 데이터를 가지고 서로 비슷한 유저 혹은 아이템 찾기
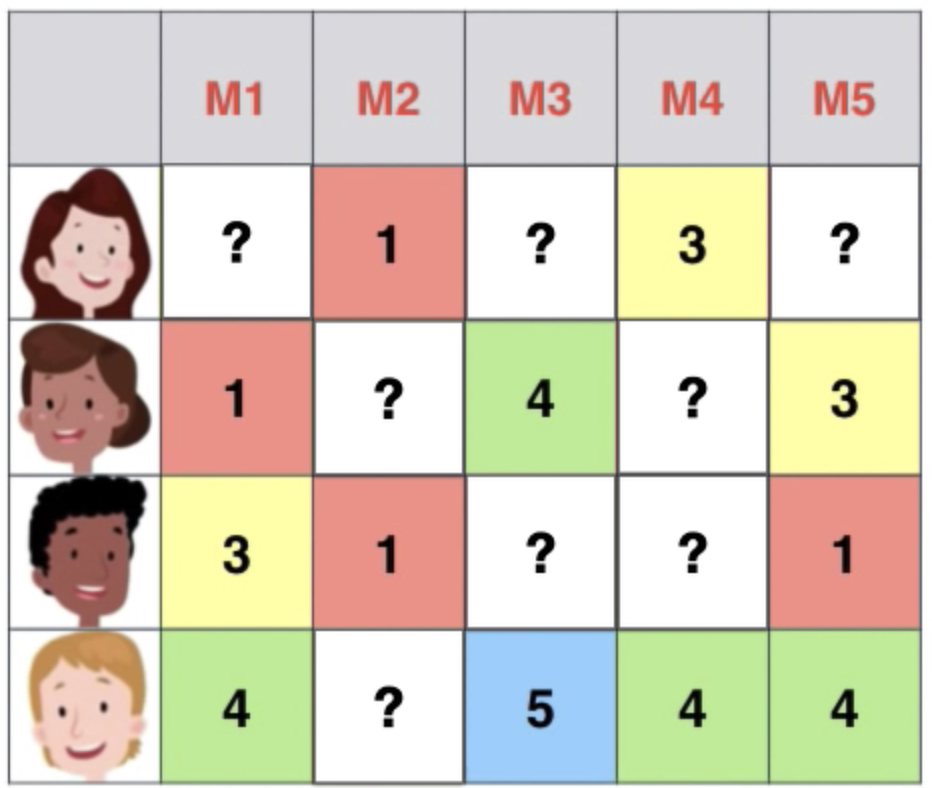
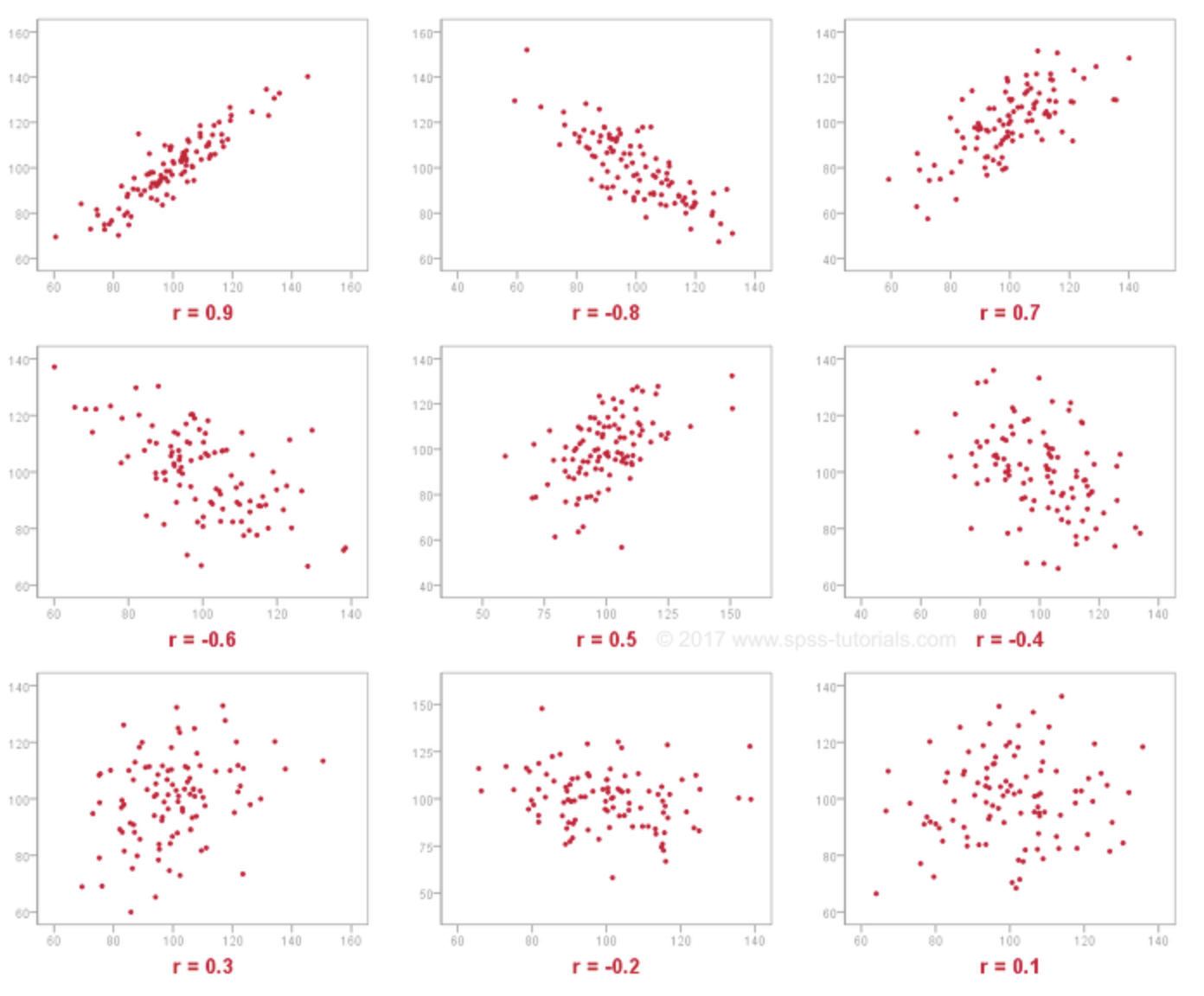
- pearson correlation : 1에 가까울 수록 유사한 선호
- ‘User-oriented Neighborhood’ & ‘Item-oriendted Negiborhood’ - 양/음의 관계를 계산하기에 선호와 비선호가 구분되어 있는 Explicit Dataset에 적합
3-2. latent factor based CF Model(feat.SVD)
잠재요인 협업 필터링
: 주어진 사용자 평점(또는 관람) 데이터를 잠재요인을 기준으로 ‘사용자 정보 행렬’과 ‘아이템 정보 행렬’로 분해하여 각각의 행렬을 사용해 사용자간 유사도와 아이템간 유사도를 계산할 수 있다. 또한 두 행렬을 다시 내적하여 이전에 사용자가 선호를 남기지 않은 항목에 대해서도 예측값을 제공해 줄 수있다.
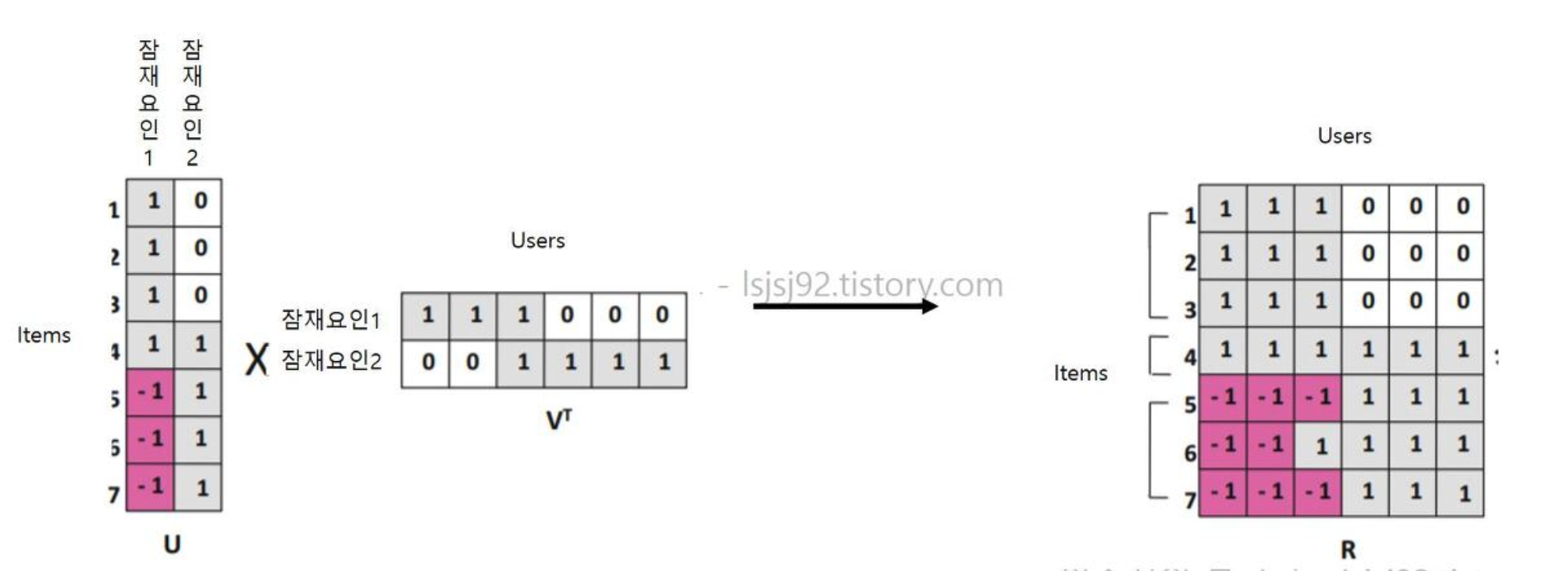
- U(‘사용자-잠재요인’) & Sigma(잠재요인) & vT(‘아이템-잠재요인’)
Reference
[1] https://dc7303.github.io/python/2019/08/06/python-memory/
[2] https://yeomko.tistory.com/6?category=805638