Recommend 2_Latent Factor CF(feat. SVD)
25 Jul 2020 ML: Latent Factor Based Collaborative Filtering은 행렬 분해(Matrix Facotrization)에 기반한 알고리즘으로, 사용자 행렬과 아이템 행렬을 각각 잠재요인 기준으로 생성한 후 이를 다시 내적하여 사용자가 아직 선호를 나타내지 않은 아이템에 대해서도 선호를 예측
Basic Concept
1. 행렬 분해
: 행렬 분해는 주어진 사용자-아이템 행렬을 ‘사용자-잠재요인’행렬 , ‘아이템-잠재요인’ 행렬로 분해. 여기서 우리가 설정하게 되는 ‘잠재요인’이란, ‘영화’를 분류하는데 있어서 액션/로맨스/코미디 등과같이 서로 다른 ‘장르’라고 대략적으로 생각.
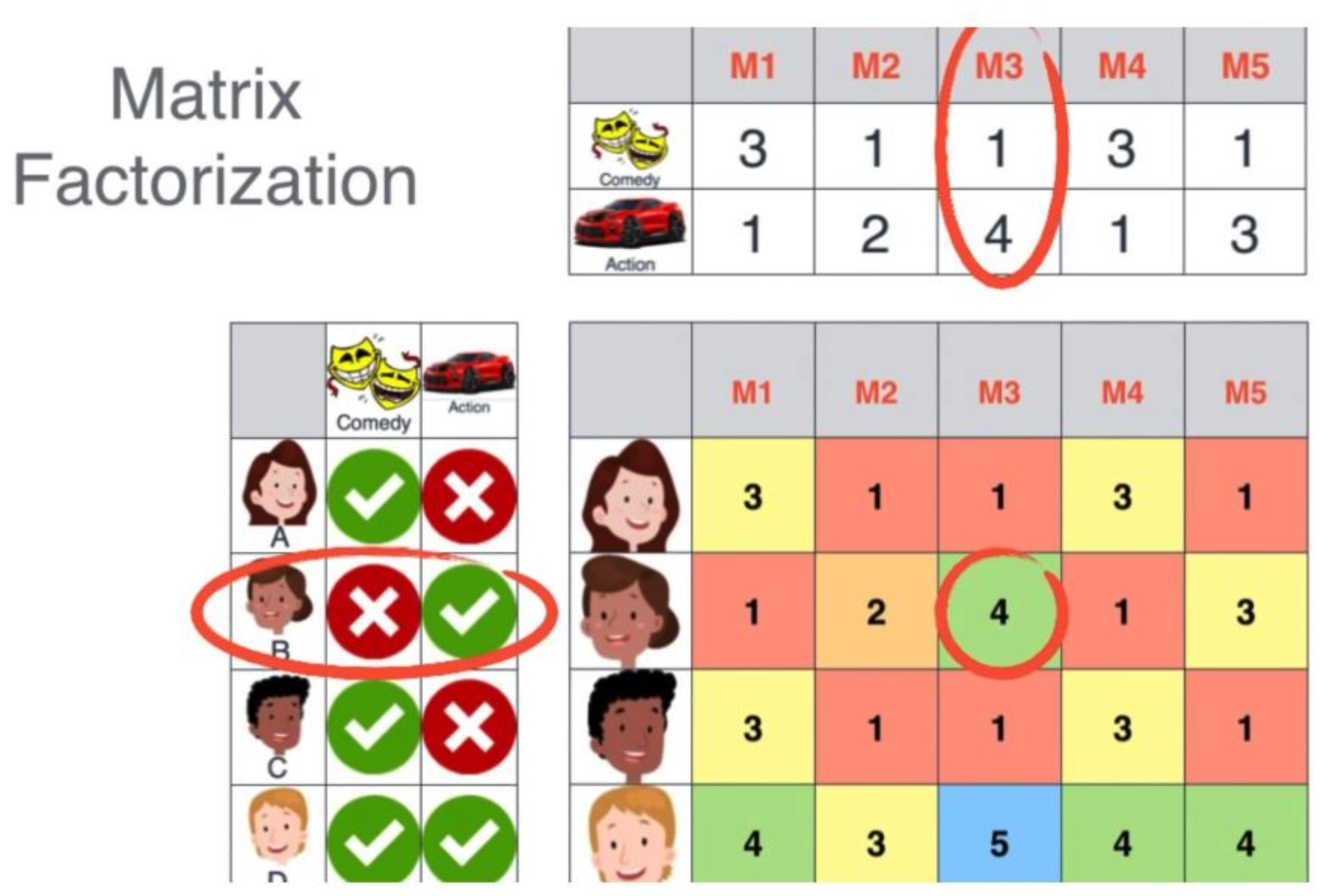
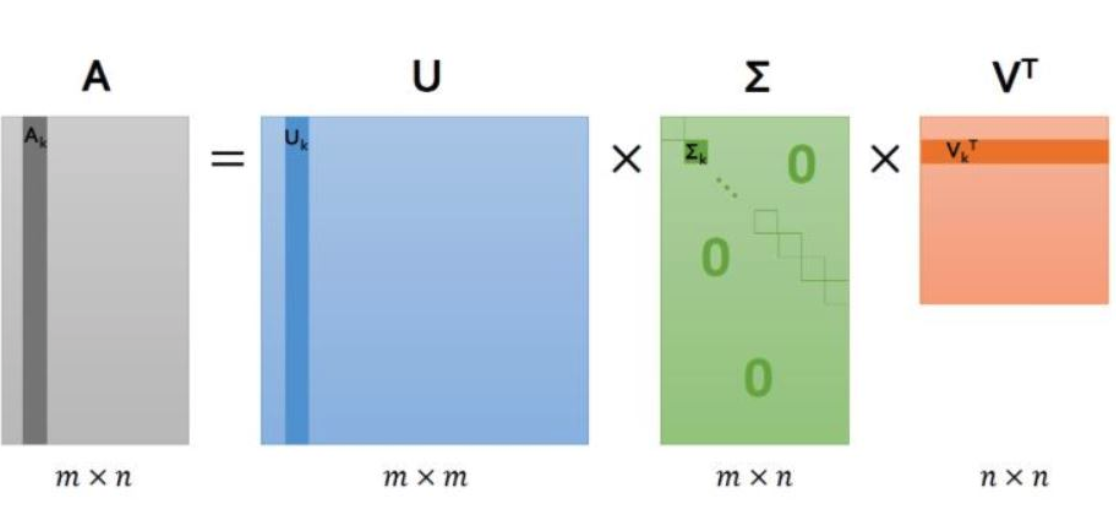
- $U$ (사용자-잠재요인) : 사용자별 어떤 장르(잠재요인) 선호를 갖고 있는지 분해
- $\sum$ (잠재요인)
- $V^T$ (아이템-잠재요인) : 영화별 어떤 장르(잠재요인) 성격을 갖고 있는지 분해
2. 행렬 결합
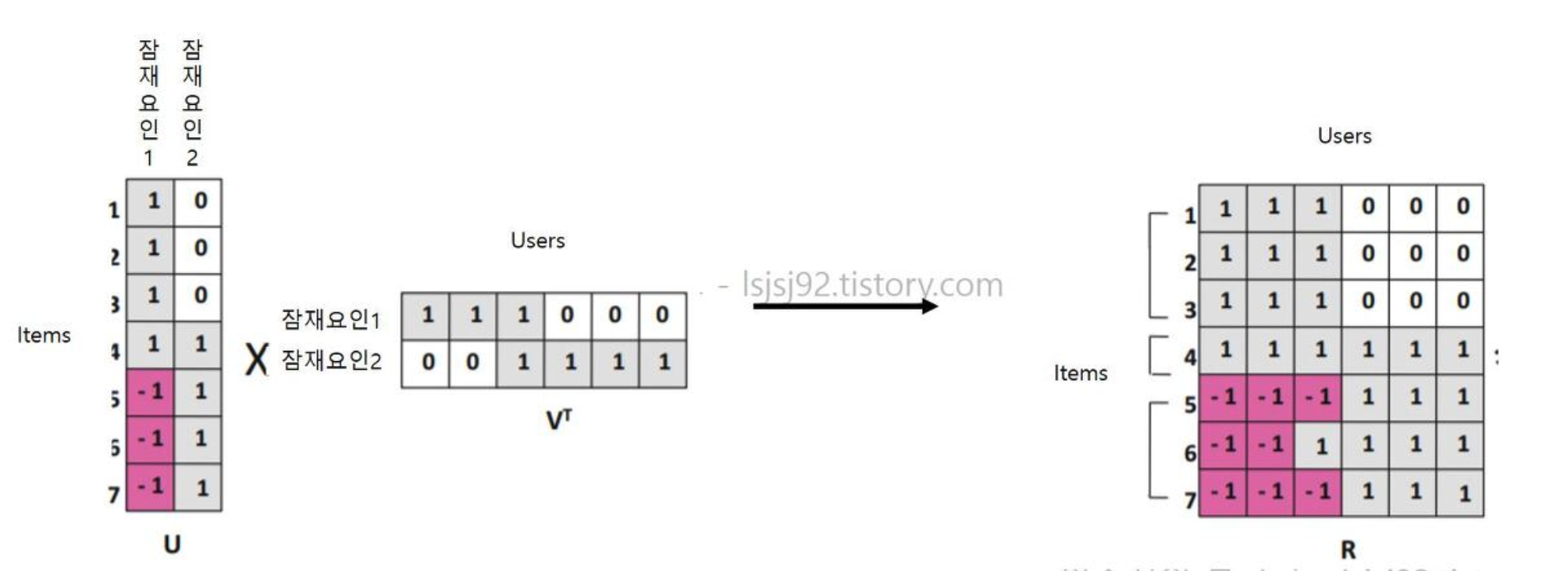 앞선 분해된 행렬을 다시 내적으로 곱해주면,
초기 '사용자-아이템'과 유사한 원본행렬이 생성되면서,
기존에 관람(평가)하지 않았던 아이템에 대해서도 점주를 매길 수 있게 됩니다.
앞선 분해된 행렬을 다시 내적으로 곱해주면,
초기 '사용자-아이템'과 유사한 원본행렬이 생성되면서,
기존에 관람(평가)하지 않았던 아이템에 대해서도 점주를 매길 수 있게 됩니다.

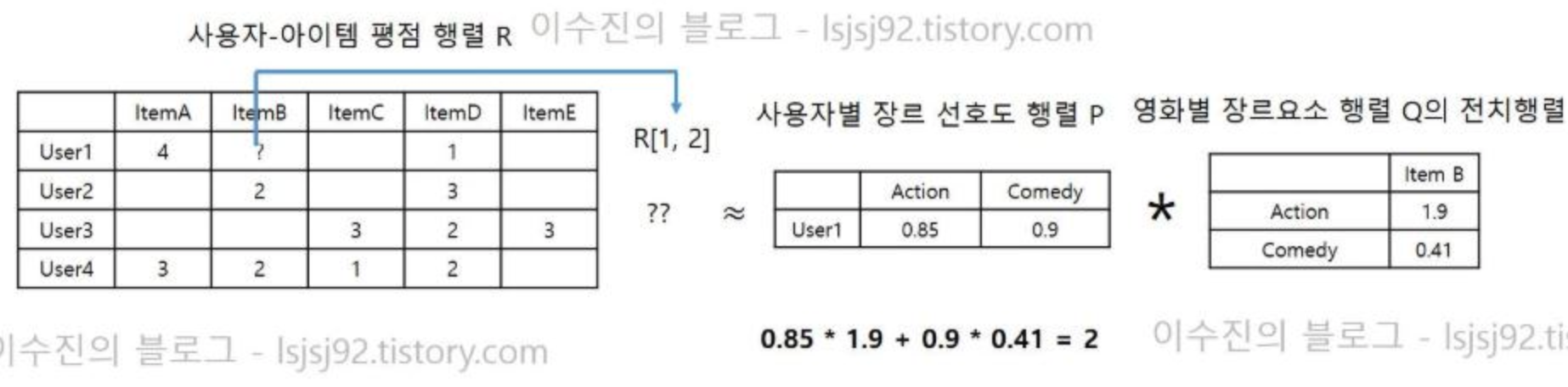
2. 구현하기
from sklearn.decomposition import TruncatedSVD
from scipy.sparse.linalg import svds
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
피봇 테이블을 이용해, 영화명이 컬럼으로 들어가 있는 데이터 프레임 생성한다.
# Data Import
# src : https://www.kaggle.com/sengzhaotoo/movielens-small
rating_data = pd.read_csv('./datas/movie_lens/ratings.csv')
movie_data = pd.read_csv('./datas/movie_lens/movies.csv')
# preprocess
rating_data.drop('timestamp', axis = 1, inplace = True)
movie_data.drop('genres', axis = 1, inplace = True)
user_movie_data = pd.merge(rating_data, movie_data, on = 'movieId')
user_movie_rating = user_movie_data.pivot_table('rating', index = 'userId', columns='title').fillna(0)
우선, 영화간 유사도를 계산하여 특정 영화를 입력할 때, 해당 영화와 유사한 영화를 추출해내는 모델을 만들어 보자. 영화간 유사도를 계산하기 위해, 사용자 기준이었던 행렬을 영화중심으로 변환해준다.
- input : item
- output : similar item
1) 유사 영화 추천
# 영화-사용자 행렬 생성
movie_user_rating = user_movie_rating.values.T # 영화 - 사용자 행렬
(1) 행렬 분해 & 결합
영화 기준의 행렬을 TruncatedSVD 함수를 행렬분해를 진행하였다. 일반 SVD의 결과는 원본 행렬과 동일한 shape을 갖춰야 하지만, TruncatedSVD는 행렬곱의 결과를 시그마 행렬의 특이값 가운데 상위 n개만으로 압축해서 출력해준다. 이로 인해 정보량의 손실이 발생하기는 하지만, 거의 유사한 행렬을 얻으면서 메모리를 절약할 수 있다. (결과 행렬은 0이 거의 존재하지 않는 Dense Matrix이기에 영화간 유사도만을 계산하기 위한 행렬에 굳이 사용자의 모든 선호를 출력해주는 컬럼을 유지할 필요가 없지 않았을까 한다.)
# 행렬 분해
SVD = TruncatedSVD(n_components=12)
matrix = SVD.fit_transform(movie_user_rating)
matrix.shape # 9064 x 12
(2) 상관계수 계산
# 상관계수 계산
corr = np.corrcoef(matrix)
corr.shape # (9064 * 9064)
# Matrix index에 영화명 연결
movie_title = user_movie_rating.columns
movie_title_list = list(movie_title)
# 유사 영화 출력
movie_name = "Guardians of the Galaxy (2014)"
coffey_hands = movie_title_list.index(movie_name)
corr_coffey_hands = corr[coffey_hands]
list(movie_title[(corr_coffey_hands >= 0.9)])[:50]
2) 사용자 개인 추천
위에서 영화간 유사도 통해 유사한 아이템을 확인해 보았으나, 실제 개인화 추천모델이라면 사용자를 input값으로 넣었을 때, 사용자에게 적합한 아이템 리스트가 output으로 출력되는 형태가 좀더 자연스러울 것이다. 그렇기에 이번엔 사용자 사용자 개인을 기준으로한 matrx 활용해보자.
- input : user_id
- output : item
# 사용자-영화 행렬
user_movie_rating.head()
이때 각 사용자별 사용자 평점을 빼주는 작업은 사용자 별 평점을 주는 정도가 다름을 반영하기 위함이다. 누군가는 굉장히 재미있게 본 영화도 3점을 주는 반면 누군가는 5점을 주는 등 개인의 선호가 다르기에 이를 개인화 시켜주기 위해 평균을 빼준다.(평점 데이터가 아닌, 단순 관람 데이터인 경우 필요치 않음)
matrix = df_user_movie_ratings.as_matrix() # matrix는 pivot_table 값을 numpy matrix로 만든 것
user_ratings_mean = np.mean(matrix, axis = 1)# user_ratings_mean은 사용자의 평균 평점
matrix_user_mean = matrix - user_ratings_mean.reshape(-1, 1) # R_user_mean : 사용자-영화에 대해 사용자 평균 평점을 뺀 것.
(1) 행렬 분해
TruncatedSVD함수와는 달리, scipy패키지에서 제공해주는 svds함수는 Output으로 분해된 3개의 행렬을 그대로 출력해준다.
#scipy에서 제공해주는 svd.
# U 행렬, sigma 행렬, V 전치 행렬을 반환.
U, sigma, Vt = svds(matrix_user_mean, k = 12)
print(U.shape)
print(sigma.shape)
print(Vt.shape)
#(671, 12)
#(12,)
#(12, 9066)
# 이때 sigma 행렬은 현재 1차원 행렬로 되어있기에, 0을 포함한 대각행렬로 만들어줌
sigma = np.diag(sigma)
sigma.shape
(2) 행렬 결합
위 행렬을 내적하는 과정에서, TruncatedSVD와 달리 모든 컬럼을 그대로 출력해주기에 메모리 이슈에 주의해야 한다.
# U, Sigma, Vt의 내적을 수행하면, 다시 원본 행렬로 복원이 된다.
# 거기에 + 사용자 평균 rating을 적용한다.
svd_user_predicted_ratings = np.dot(np.dot(U, sigma), Vt) + user_ratings_mean.reshape(-1, 1)
# 생성된 matrix를 데이터 프레임 형태로 변환
df_svd_preds = pd.DataFrame(svd_user_predicted_ratings, columns = df_user_movie_ratings.columns)
df_svd_preds.head()
def recommend_movies(df_svd_preds, user_id, ori_movies_df, ori_ratings_df, num_recommendations=5):
#현재는 index로 적용이 되어있으므로 user_id - 1을 해야함.
user_row_number = user_id - 1
# 최종적으로 만든 pred_df에서 사용자 index에 따라 영화 데이터 정렬 -> 영화 평점이 높은 순으로 정렬 됌
sorted_user_predictions = df_svd_preds.iloc[user_row_number].sort_values(ascending=False)
# 원본 평점 데이터에서 user id에 해당하는 데이터를 뽑아낸다.
user_data = ori_ratings_df[ori_ratings_df.userId == user_id]
# 위에서 뽑은 user_data와 원본 영화 데이터를 합친다.
user_history = user_data.merge(ori_movies_df, on = 'movieId').sort_values(['rating'], ascending=False)
# 원본 영화 데이터에서 사용자가 본 영화 데이터를 제외한 데이터를 추출
recommendations = ori_movies_df[~ori_movies_df['movieId'].isin(user_history['movieId'])]
# 사용자의 영화 평점이 높은 순으로 정렬된 데이터와 위 recommendations을 합친다.
recommendations = recommendations.merge( pd.DataFrame(sorted_user_predictions).reset_index(), on = 'movieId')
# 컬럼 이름 바꾸고 정렬해서 return
recommendations = recommendations.rename(columns = {user_row_number: 'Predictions'}).sort_values('Predictions', ascending = False).iloc[:num_recommendations, :]
return user_history, recommendations
already_rated, predictions = recommend_movies(df_svd_preds, 330, df_movies, df_ratings, 10)
Reference
[1] https://dc7303.github.io/python/2019/08/06/python-memory/
[2] https://yeomko.tistory.com/5?category=805638
[3] https://scvgoe.github.io/2017-02-01-%ED%98%91%EC%97%85-%ED%95%84%ED%84%B0%EB%A7%81-%EC%B6%94%EC%B2%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C-(Collaborative-Filtering-Recommendation-System)/
- 본 포스트는 이수진님의 블로그를 참조하며 공부하기 위해 작성하였습니다.