Recommend 3_Matrix Factorization step by step
01 Aug 2020 ML추천 시스템 : Matrix Factorization
(1) 개요
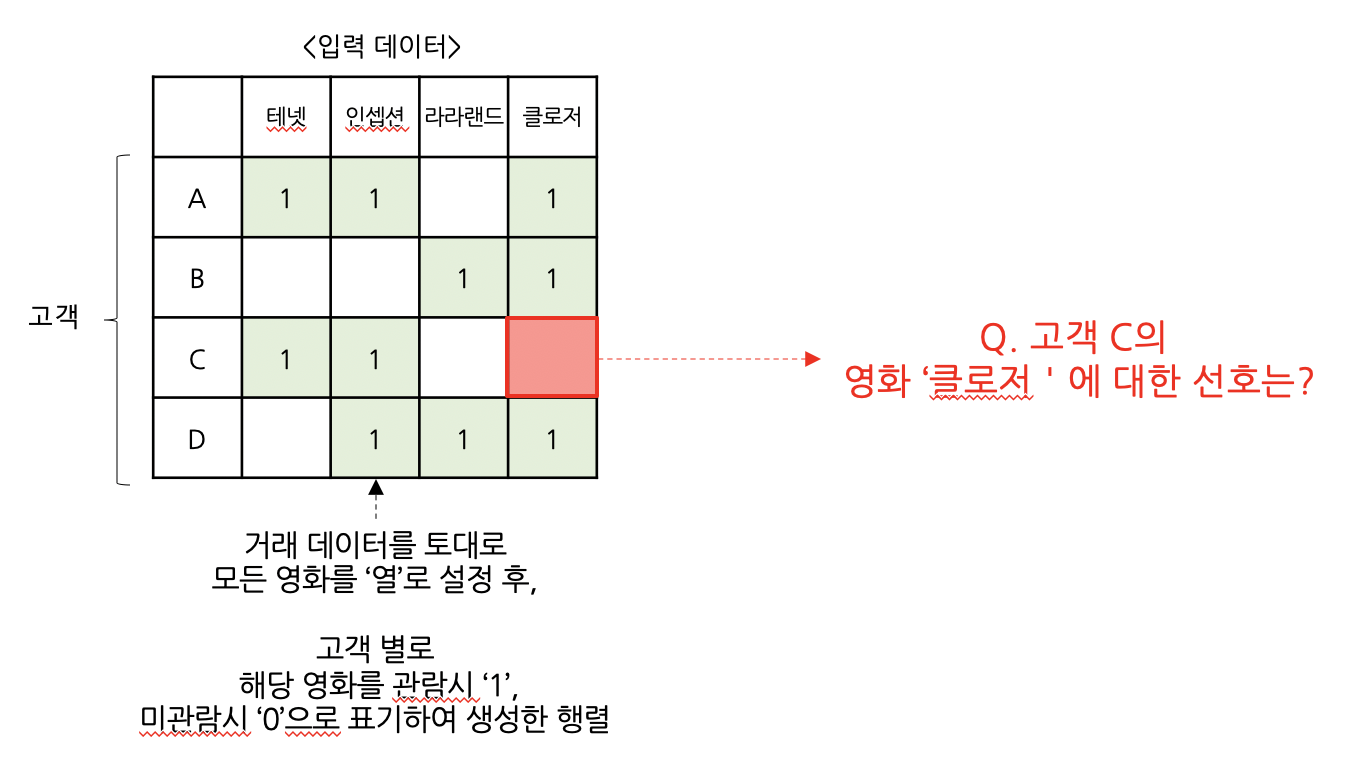
: 유저와 아이템간의 상호작용 데이터(거래 데이터)를 기반으로 ‘잠재요인’을 찾아내고, 찾아낸 잠재요인을 기반으로 유저가 관람하지 않은 아이템에 대해서 평가하는 알고리즘
(2) 목표
: 특정 고객의 과거 관람 이력을 토대로 , 아직 관람하지 않은 신규 영화의 선호 예측
Step ① 유저 잠재 행렬 & 아이템 잠재 행렬 생성
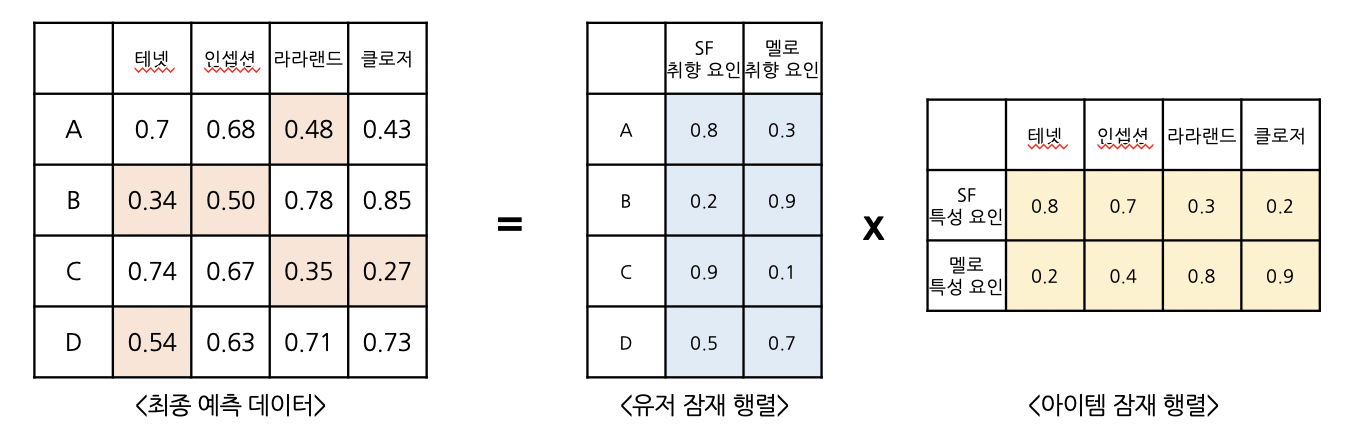
: 주어진 거래데이터(입력 데이터)를 활용해, 유저별로 어떤 장르 취향을 지니고 있는지 & 영화별로는 어떤 장르 특성을 지니고 있는지 학습하고자 합니다.
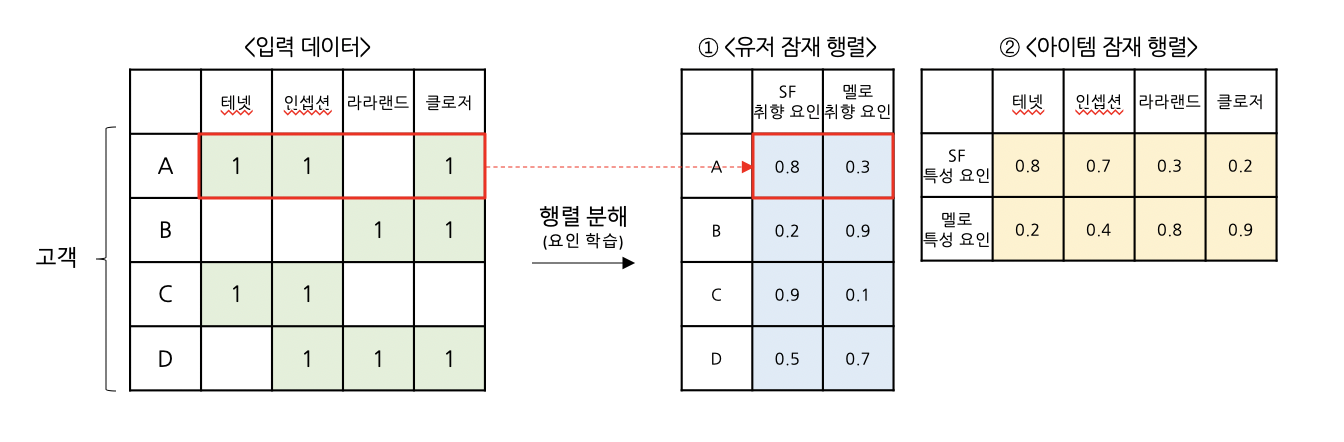
① <유저 잠재="" 행렬="">
: 위 예시에서 ‘SF요인’과 ‘멜로요인’ 두 가지로 학습을 진행해, 고객별로 ‘SF 취향’과 ‘멜로 취향’ 점수를 계산합니다.
e.g. A고객은 [테넷, 인셉션, 클로저] 영화를 관람하였고 그 결과, “A고객은 ‘SF 취향’ 은 0.8로 높으며, '멜로 취향’은 0.3점으로 낮다”고 고객의 선호를 정의할 수 있습니다.
또한, 유저 잠재 행렬을 통해서 고객 A와 고객C가 서로 유사한 취향을 갖고 있다고도 알 수 있습니다.
② <아이템 잠재="" 행렬="">
:영화도 동일한 방식으로, 영화별로 ‘SF 특성’과 ‘멜로 특성’ 점수를 계산하고, 영화의 특성을 정의합니다.
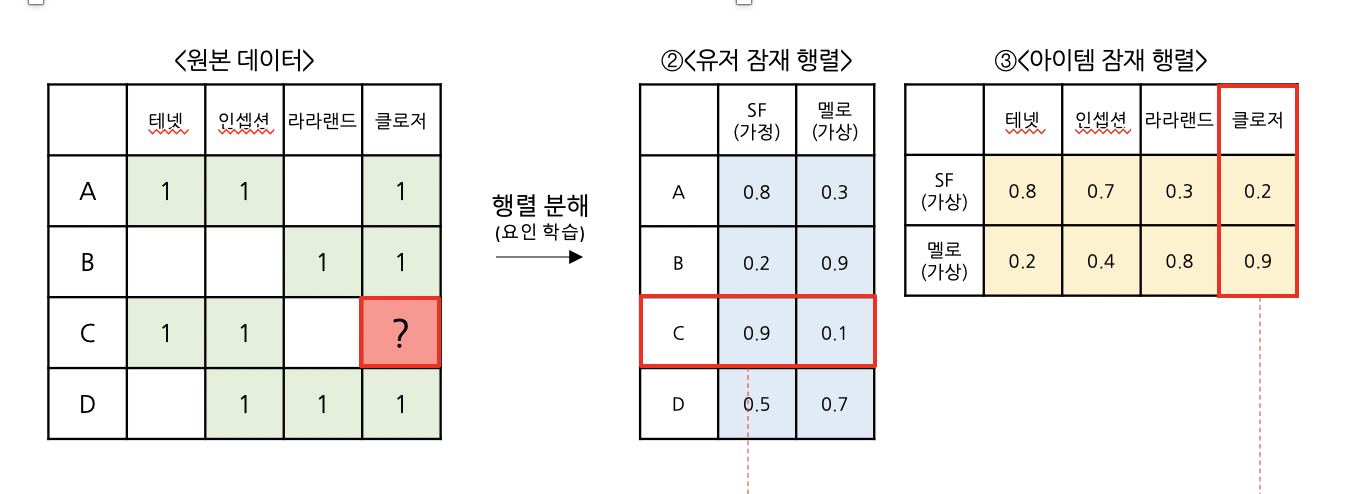
Step ② 예측값 생성
: <유저 잠재="" 행렬=""> & <아이템 잠재="" 행렬="">을 토대로, “고객의 선호”와 ”아이템의 특성”을 2가지 요인(SF & 멜로)으로 정의 했습니다.
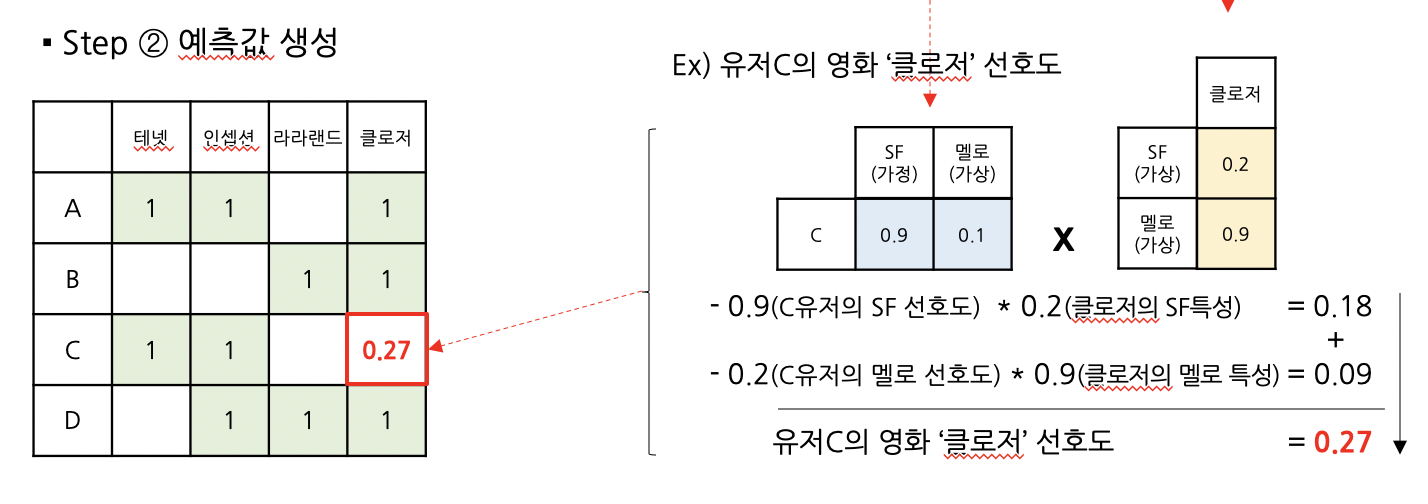 이처럼 고객의 선호값에 영화의 특성값을 곱하면,
고객이 관람하지 않은 영화에 대한 선호를 예측할 수 있습니다.
동일한 방법으로 모든 고객의 취향값에 모든 영화의 특성값을 계산하면,
최종 예측 행렬을 얻을 수 있습니다.
이처럼 고객의 선호값에 영화의 특성값을 곱하면,
고객이 관람하지 않은 영화에 대한 선호를 예측할 수 있습니다.
동일한 방법으로 모든 고객의 취향값에 모든 영화의 특성값을 계산하면,
최종 예측 행렬을 얻을 수 있습니다.
Reference
[1] 추천 시스템 – 잠재 요인 협업 필터링
[2] 갈아먹는 추천 알고리즘 3 Matrix Factorization