YouTube Recommendations Paper_review
27 Sep 2020 MLDeep Neural Networks for YouTube Recommendations
0. Abstract
: 이 글은 딥러닝을 활용한 드라마틱한 성능의 추천 시스템에 대한 논문이다. 해당 방식은 2가지로 나뉘게 되는데, 첫번째는 ‘후보생성 모델(deep candidate generation model)’이며, 두번째는 ‘랭킹 모델(deep ranking model)’이다. (필자는 현재 주어진 컨텐츠에 대해서 누가 높은 레이팅을 줄 것인지만 다루고 있기에 두가지 모델중 랭킹 모델에 관련된 컨텐츠만을 읽었다…)
1. Introduction
: youtube는 세계에서 가장 큰 영상 플렛폼으로, 개인화된 영상을 제공해 주는데 있어 아래와 같은 3가지 주요 쟁점을 갖고 있다.
-
- (1) Scale
- 적당히 적은 규모에서 잘 작동하던 증명된 추천 알고리즘들도, youtube의 거대한 스케일의 데이터에서는 성능이 나오지 못했다. 이 때문에 매우 특별하게 분산된 학습 알고리즘 및 효율적인 서비스 시스템은 필수적이었다.
-
- (2) Freshness
- YouTube는 매초 수십시간의 영상이 새롭게 업데이트되기에, 각 유저의 최근 행동에 따라 새로운 컨텐츠도 벨런스 맞게 추천해줄 수 있어야 했다.
-
- (3) Noise
- 사용자의 행동을 예측하는 것은 관측되지 않은 외부 요인들에 대한 sparsity와 variety 때문에 근본적인 어려움을 갖고 있다. 때문에
2. System Overview
: 전반적인 시스템은 두가지 neural Networks으로 구성된다.
- candidate generation
- input : events from the user’s YouTube activity history
- output : samll subset(hundreds) of videos from a large corpus
: 후보 생성 모델은 CF(Collaborative Filtering)를 통해 제공된 넓은 의미의 개인화된 목록을 제공 이때 유저간 유사도는 시청된 영상의 ID값, 검색 토큰, 인구통계 등의 굵직한 특징을 활용해 생성된다.
-
- ranking
- 주어진 리스트내에서 ‘best’ 추천을 위해서는 적당한 수준에서 각 후보들의 중요성을 ‘recall’값을 기반으로 구별할 수 있어야 한다. ‘랭킹 모델’은 영상과 유저를 표현하는 특징(ex. latent facor)과 목적함수를 사용해 각 영상에 점수를 부여함으로써 이를 수행한다. 위 두가지 단계는 방대한 영상속에서 아주 적은 개인화된 영상을 추천해야하는 문제를 가능하게끔 만들어주었다. 개발단계에서 다양한 metrics(precision, recall, ranking loss, etc)을 사용했으나 최종 결정단계에 있어서는 live 실험을 통한 A|B testing을 진행했다. 실제 테스팅 과정에서 클릭 전환율, 시청 시간, 유저 개입도, 기타 평가 방법등의 미묘한 차이를 측정할 수 있었다. 실제 test와 offline 실험은 굉장히 다르기에, 위의 미묘한 차이들은 굉장히 중요한 시사점을 지닌다.
4. Ranking
: ranking 모델의 주요 목표는 데이터를 specialize & calibrate(눈금을 매기다) 시키는 것입니다. 랭킹 모델을 통해서 우리는 후보 생성 모델을 통해 걸러진 몇백개의 영상에 대해서 유저와 사용자간 더 많은 특징들에 주목했습니다. 랭킹 모델은 또한 서로 다른 후보의 출처들은 각 점수를 직접 비교할 수 없기에 이를 앙상블하는 것에도 중요하게 생각했습니다.
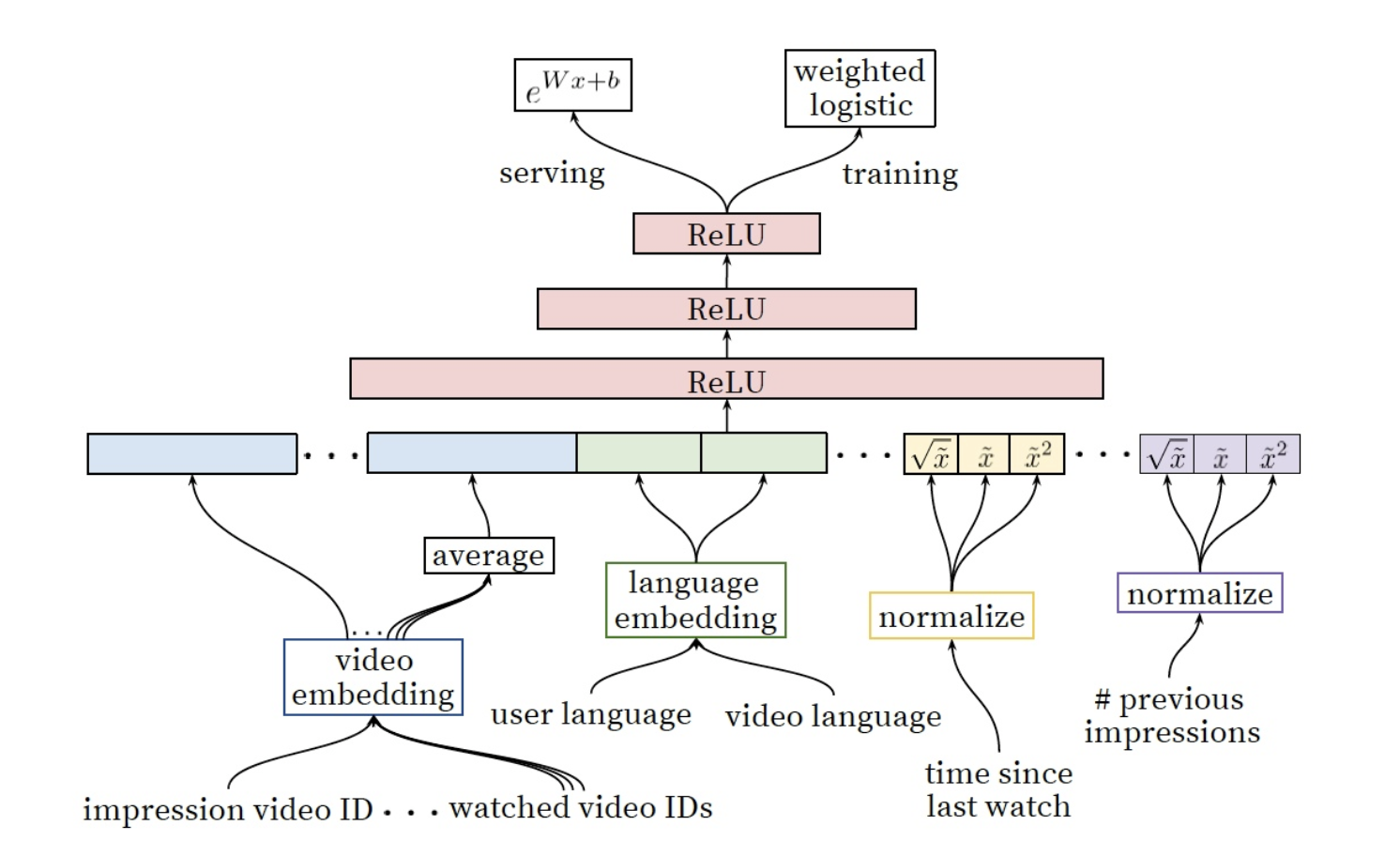
4-1) Feature Representation
: 우리의 Feature들은 전통적인 categorical & continuos/ordinal변수 분류법들과는 차별적인 방식을 지닙니다.
- categorical : binary(e.g. 로그인 여부) or millions of multi class(e.g. 검색 기록)
- single value => univalent (e.g. 비디오 구분값)
- set of values => multivalent (e.g. 유저가 시청한 N개의 비디오 ID값들의 목록)
우리는 또한 변수가 아이템을 묘사하는 것인지 또는 사용자/context(‘query’)를 묘사하는지에 따라 구분했습니다.
(1) Feature Engineering
: 비록 딥러닝이 수많은 변수를 수동으로 핸들링 하지 않아도 되는 장점을 지니고 있으나, 우리가 갖고 있는 데이터를 그대로 input으로 넣어 feedforward neural network를 진행하기엔 무리가 있었다. 가장 중요한 문제는 Temporal sequence of user actions에 대한 표현과 이를 어떻게 스코어로 연결짓는 것인가였다. [e.g. of Temporal sequence of user action]
- channel : 해당 채널에서 얼마나 많은 영상을 사용자가 시청했는가(like 구독 여부)
- the last time the user watched on this topic : 해당 이슈에 대해서 언제 마지막으로 시청했는가
- candidate generation : 어떤 소스들이 이 영상을 후보군에 포함시키는데 일조하였는지
- frequency of past video impression : 과거 시청 빈도를 통해 이탈(churn)예 => 위의 사항들이 고려된 feature engineering이 필요함
(2) Embedding Categorical Features
: sparse한 categorical feature를 neural network에 적합한 dense형태로 변화하기 위해 Embedding을 활용.
Embedded unique ID space(‘vocabulary’)
- number of Dimension : 각 고유 ID 공간은 별도의 학습된 임베딩 공간을 갖으며, 이때 공간의 차원수는 유니크한 고유 값(number of unique)수의 로그에 대략 비례하여 증가하는 차원수를 갖는다.(e.g. 1000개의 유니크한 단어가 존재할 시, log1000을 차원수로 설정)
- Top N : 매우 큰 ID space를 줄이기 위해, 클릭수를 기준으로 Top N개의 단어 id만 사용
- 사전에서 찾을 수 없는 단어는 0으로 임베딩 처리
- 다중값 범주형 임베딩(multivalent)은 네트워크에 들어가기전에 평균값 처리
- 동일한 ID space 공간내의 카테고리 변수는 동일한 embedding공간에 놓인다.
e.g. 독특한 특징을 지닌 영상의 Id들은 단일 글로벌 임베딩(video ID of the imporessio, last video ID watched by the user, video ID that ‘seeded’ the recommendation)
- 동일한 임베딩을 공유하더라도, 각각의 feature는 네트워크에 들어갈 때 독립적으로 들어가, 레이가 각 feature들에 특화되어 학습할 수 있도록 한다.
- 임베딩을 공유하는 것은 모델의 일반화(generalization)를 위해 중요하며, 학습 속도를 향상시키고 더 많은 메모리를 절약할 수 있다.(32차원에 임베딩된 100만 id고유값은 2048개의 fully connected layer보다 7배 이상 많은 파라미터를 갖는다.)
(3) Normalizing Continuous Features
: 신경망은 input값의 분포와 스케일 문제에 민감하기로 악명이 높은 반면, 대안적 접근법인 의사결정나무(decision trees)는 개별 feature의 스케일 문제에 둔감하다. 우리는 적절한 평준화(Normalization)가 연속변수의 수렴에 있어서 굉장히 중요하다는 걸 알게 되었다. f분포를 갖고 있는 연속변수 $x$는 누적 분포를 활용해 value의 스케일에 따라 0~1사이 동등한 분포를 갖는 $\tilde{x}$로 변환된다. 더불어 원본인 $\tilde{x}$에 $\tilde{x^2}$ or $\sqrt{\tilde{x}}$등을 적용해 더욱 강력한 네트워크를 만들기도 하였으며, 이때 제곱항을 적용하는 것이 오프라인 성능을 향상시키기도 하였다.
Reference
[1] Yifan Hu et al. Collaborative Filtering for Implicit Feedback
[2] 갈아먹는 추 알고리즘 [4] Alternating Least Squares