01 Jun 2023
1. SELECT문에서 많이 사용되는 키워드
1) DISTINCT
: DISTINCT 뒤에 오는 열을 중복 없이 출력하며,
뒤에 2개 이상의 컬럼이 올 땐, 이를 그룹으로 묶어서 중복을 제외함.
-- 1) DISTINCT 뒤에 하나의 열이 올떄
SELECT DISTINCT POSITION FROM EMP;
-- 2) DISTINCT 뒤에 2개 이상의 열이 올떄
SELECT DISTINCT POSITION, GRADE FROM EMP;
+ DISTINCT는 집계 함수와 하부 쿼리에서 많이 사용된다. (nunique)
-- 1) 단순히 행의 갯수를 셀 때.
SELECT COUNT(POSITION) FROM EMP;
-- 2) 유니크한 행의 갯수를 셀 때. COUNT(DISTINCT {컬럼명}})
SELECT COUNT(DISTINCT POSITION) FROM EMP;
2) ALIAS (별칭)
: 컬럼명이 길 때, 별칭으로 바꿔서 사용하기 위한 방법
-- 1) 특정 컬럼의 출력명을 변경
SELECT POSITION AS POS FROM EMP;
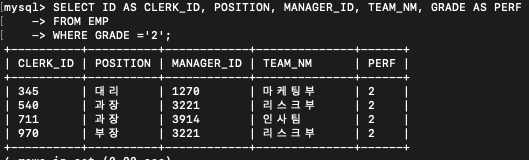
-- 2) 특정 조건의 행만 선택하되, 특정 컬럼의 출력명을 변경
SELECT ID AS CLERK_ID, POSITION, MANAGER_ID, TEAM_NM, GRADE AS PERF
FROM EMP
WHERE GRADE ='2'
-- 3) 집계한 값의 출력명 변경
SELECT COUNT(DISTINCT MANAGER_ID) AS n_manager
FROM EMP;
WHERER절에서는 별칭인 PERF가아니라 GRADE를 사용해야한다!*
Reference
- 칼퇴족 김대리는 알고 나만 모르는 SQL - 책밥
27 May 2023
SQL 사용을 위한 데이터 베이스 용어
- 데이터 베이스 : 여러 사람에게 공유되어, 사용될 목적으로 관리되는 데이터 집합
- 테이블(table) : 특정 종류의 데이터를 구조적 목록으로 구분한 것
- 스키마(schema) : 테이블에 어떤 데이터를 어떤 ‘형식’으로 저장할 것인가를 정의한 것
- 열 (schema) : 테이블을 구성하는 각각의 정보 (= field)
- 행 (recod) : 데이터가 한 줄에 저장된 것
1. 기본 구조 및 Basic 문법
1) 데이터 베이스 선택
SHOW DATABASE -- 데이터 베이스 조회
1) basic 문법
SELECT '컬럼 이름'
FROM '테이블 이름'
WHERE '조건'
GROUP BY '그룹화할 컬럼'
HAVING '그룹화한 뒤 조건'
LIMIT '제한할 개수'
1) SELECT / FROM
- SELECT
[불러오고자 하는 대상 (Columns)]
- FROM [찾을 대상이 있는 공간(Table)]
-- HR 테이블에서, 'ID','GENDER','AGE' 변수를 불러와라.
SELECT ID, GENDER, AGE
FROM HR
2) ORDER BY
: 컬럼들을 특정 규칙에 맞춰서 정렬 (default : asc - 오름차순)
-- grade 오름차순 & ID 기준 내림차순 정렬
SELECT *
FROM EMP
ORDER BY GARADE ASC, ID DESC;
3) WHERE
: 조건문 추가
-- HR 테이블에서, 'ID','GENDER','AGE' 변수를 불러오며,
-- 이때, 성별은 남성이며 'AGE'는 60세 이상
SELECT ID, GENDER, AGE
FROM HR
WHERE 'GENDER' == 'male' & 'AGE' >= 60
4) GROUP BY
: 컬럼들을 특정 규칙에 맞춰서 그룹화함(Aggregate)
- 1) “1”번 유저의 모든 이벤트 로그를 확인.
SELECT *
FROM user_log
WHERE user_id = '1';
- 2) “1”번 유저의 이벤트별 로그 ‘횟수’를 계산
SELECT user_id, event, event_id
COUNT (user_id) AS 'event_cnt'
FROM user_log
WHERE user_id = '1'
GROUP BY user_id, event, event_id;
Reference
[1] 비전공자를 위한 SQL
25 May 2023
1. SQL이란? (Structured Query Language)
: 관계형 데이터베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 특수 설계된 특수 목적 프로그래밍 언어.
(SQL종류 : MySQL, PostgreSQL, MariaDB, Oracle)
(1) 데이터베이스 관리 시스템(DBMS)의 특징
- 실시간 접근
- 계속적인 변화
- 동시 공용
- 내용에 의한 참조
"데이터 저장소에서 데이터를 추출하기 위한 도구"
1) SQL 분류
(1) DML(Data Manipulation Language)
- 데이터 조작 목적의 언어
- DML을 사용하기 위해서는 타겟이 되는 ‘테이블’이 반드시 정의되야함.
- SELECT(선택)
- INSERT(삽입)
- UPDATE(수정)
- DELETE(삭제)
(2) DDL(Data Definition Language)
- 데이터 정의 언어
- 데이터 베이스, 테이블, 뷰, 인덱스 등의 데이터 베이스 개체를 생성/삭제/변경 역할
- 실행 즉시 MySQL에 적용되며, ROLLBACK 및 COMMIT 불가
(3) DCL(Data Control Language)
- 데이터 제어 언어
- 사용자에게 특정 권한을 부여/제거시 사용
2. SQL 시작하기 (★★★)
(1) MySQL 설치하기
※ MacOS에 MySQL 설치
(2) MySQL 시작하기 (in Terminal)
- ※ SQL 설치하고 실행하기 by 다임하게
- MySQL 설치가 완료됐다면, 설치된 경로로 이동하여 root 권한으로 MySQL 접속.
1) MySQL이 실행상태라면, root권한으로 MySQL에 접속해보자.
: root 계정으로, 학습용 DB 생성
# 1) MySQL 디렉토리로 이동
cd /usr/local/mysql/bin
# 2) MySQL 실행 (root 권한)
./mysql -u root -p ## -u : 유저명, -p : 인증방식 Password (dbs1)
-- 3) 학습용 DB 생성
CREATE DATABASE {study_db} default CHARACTER SET UTF8;
2) 신규 계정 생성 및 권한 부여
root계정은 위험하니, 학습용 계정을 생성하여 다시 접속해보자.
신규 계정으로 로그인하여 DB를 검색해보면, root계정에서 생성한 학습용 DB가 보이지 않을 것이다.
신규 계정은 해당 DB의 권한이 부재하기 때문이며, root 계정으로 학습용 계정에 학습용 DB의 사용 권한을 부여해주어야 한다.
-- 1) 신규 계정 생성 (root로 접속한 상태에서 진행)
-- local 학습용 계정명 : th_sql_study
CREATE USER '{신규 계정 이름}'@localhost IDENTIFIED BY '{인증 비번}';
-- 2) 신규 계정에 권한 부여
GRANT ALL PRIVILEGES ON study_db.* TO study_user@localhost;
-- GRANT ALL PRIVILEGES ON study_db.* TO study_user@localhost IDENTIFIED BY 'study';
-- 위 커리에서 {IDENTIFIED BY 'study';} 이부분이 문법에러가 발생하나 원인을 파악하지 못하여 IDENTIFIED BY 구문없이 진행하였다.
2) 신규 계정, DB 선택 및 테이블 생성
# 1) MySQL 실행 (신규계정)
./mysql -u '{신규 계정 이름}' -p
-- 0) 현재 데이터 베이스 현황 확인
SHOW DATABASES;
-- 1) 학습용 DB 선택
USE study_db;
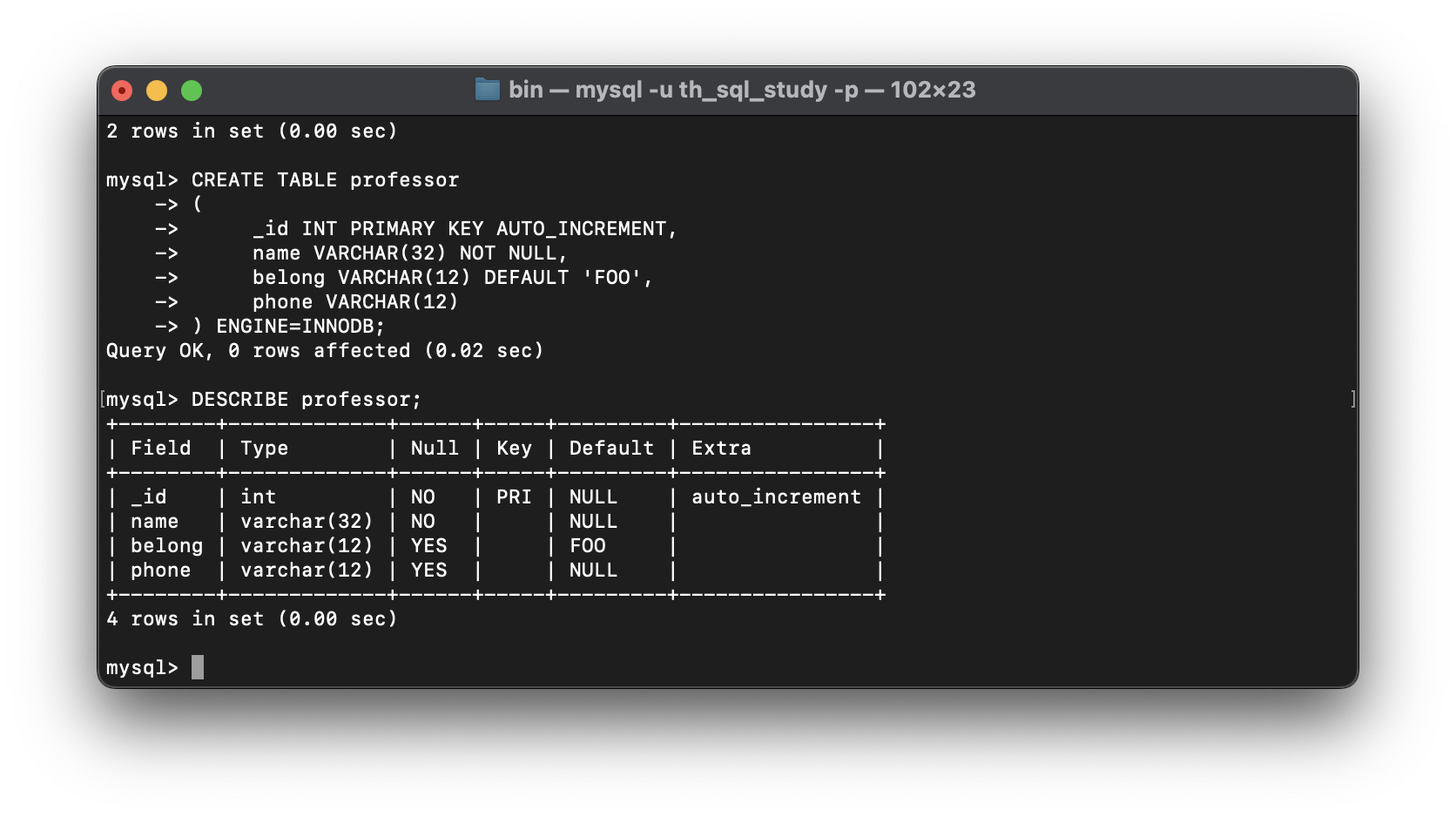
-- 2) 테스트 테이블 생성(삽입)
CREATE TABLE professor
(
_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(32) NOT NULL,
belong VARCHAR(12) DEFAULT 'FOO',
phone VARCHAR(12)
) ENGINE=INNODB;
-- 3) 테스트 테이블 확인
DESC
-- 4) 학습용 테이블 삭제
DROP TABLE professor
3. ERD
- Entity : 개체, 테이블
- Attribute : Entity내 포함된 컬럼
- Realationship : 테이블간 관계
- direction
- one to one
- one to many
- many to many
4. Data Type
1. 숫자
- int
- tinyint: -128 ~ 127
- smallint: -32768 ~ 32767
- mediumint: -8388608 ~ 8388607
- int: -2147483648 ~ 2147483647
- bigint: $-2^{\smash{63}}$ ~ $2^{\smash{63}} - 1$
- float
- decimal(): 정확한 값을 저장하기 때문에 정밀하게 계산해야 할 때 사용
- float(): 지수 표현(예시. 1.2e+3)을 통해 근삿값을 저장하기 때문에 정확성은 떨어지지만 처리 속도가 빠름
- double(): float()보다 정확한 대신 저장공간이 더 많이 필요함
2. 문자
- varchar(): 글자 수가 정해져 있지 않은 문자 (예시. 이름, 주소 등)
- char(): 글자 수가 일정한 문자
3. 날짜 / 시간
- date(): 1000-01-01 ~ 9999-12-31
- datetime(): 1000-01-01 00:00:00.000000 ~ 9999-12-31 23:59:59.999999
- timestamp() = datetime() + timezone 가장 많이 사용
4. JSON(JavaScript Object Notation)
- JSON 포맷의 표현 방식
-
객체(Object): 키-값 쌍의 집합
{"Id":"abc", "value":123, "gender":'f'}
-
배열(Array): 순서가 있는 값의 집합
5. + SQL공부하기
1) 기본 문법 학습하기
(1) 책
2) 온라인 실습 환경 및 연습 TABLE
sqlfiddle.com 이 사이트에, 아래 CREATE 코드 입력 및 Build schema 버튼 실행
CREATE TABLE IF NOT EXISTS `user_log` (
`index` INTEGER NOT NULL AUTO_INCREMENT,
`user_id` VARCHAR(6) NOT NULL,
`event` VARCHAR(200) NOT NULL,
`event_date` date NOT NULL,
PRIMARY KEY (`index`, `user_id`)
) DEFAULT CHARSET=utf8;
INSERT INTO `user_log` (`user_id`, `event`,`event_date`) VALUES
('1', 'login_facebook', '2018-03-12'),
('1', 'write_posting', '2018-03-12'),
('1', 'write_comment', '2018-03-12'),
('1', 'view_posting', '2018-03-12'),
('1', 'view_posting', '2018-03-12'),
('2', 'login_facebook', '2018-03-12'),
('2', 'view_posting', '2018-03-12'),
('2', 'view_posting', '2018-03-12'),
('2', 'write_comment', '2018-03-12'),
('2', 'logout', '2018-03-12'),
('2', 'login_facebook', '2018-03-13'),
('3', 'login_google', '2018-03-13'),
('3', 'write_posting', '2018-03-13'),
('3', 'view_posting', '2018-03-13'),
('3', 'view_posting', '2018-03-13'),
('3', 'purchase_item', '2018-03-15'),
('3', 'write_comment', '2018-03-14'),
('1', 'view_posting', '2018-03-14'),
('4', 'view_posting', '2018-03-14'),
('5', 'purchase_item', '2018-03-13');
Reference
[1] 비전공자를 위한 SQL
[2] MySQL 데이터베이스 한번에 끝내기 SQL Full Tutorial Course using MySQL Database
24 May 2023
유입된 유저의 경로를 분석하는 것은,
광고로 유입되었다면, 광고 매체는 어떤 광고 매체가 더 효율적이었는지 분석하여, 효율적인 광고매체에 예산을 늘리는 액션을 취할 수 있고,
자연 검색을 통해 유입되었다면, 우리 사이트로 유입되는 가장 큰 키워드가 무엇인지 분석함으로써 서비스의 장점을 극대화 시킬 수 있습니다.
따라서, 유입 경로 분석을 위한 UTM Referral를 구분하는 과정은 서비스 성장을 위해서 굉장히 중요한 분석이기에, 관련하여 주요 개념들을 정리해보려 합니다.
1.획득 (Acquisition)이란
: GA에서 획득(Acquisition)이란, 사용자들이 어떤 경로(채널/캠페인)를 통해 우리 웹사이트를 방문하였는지를 보여주는 개념. 이를 활용하여 마케팅 활동별 성과를 측정합니다.
2. UTM (Urchin Tracking Module)
: 유입 구분값을 살펴보기위해서는 우선 UTM이라는 개념을 알아야한다. UTM은 어느 사이트로 부터 유입되었는지를 알려주는 꼬리표로, 타겟 사이트를 외부에 공유/홍보시 사용하는 url을 의미한다. 이 utm 값을 분석하여 유입 경로를 구분할 수 있습니다.

<이미지 출처 : 그로스클, 김신입_마케팅용어집>
- ex) https://taehwanyoun.git.io?utm_source=kakao&utm_medium=push&utm_campaign=fb_promotion&utm_term=promotionAE&utm_content=202305_contents
- utm_source=kakao : 소스(soruce), 유입 채널 –> e.g. youtube, kakao
- utm_medium=push : 매체(medium) –> e.g. push, CPC, email, video
- utm_campaign=fb_promotion : 캠페인(campagin)
- utm_term=promotionAE : 유입 키워드
- utm_content=202305_contents : 유입 컨텐츠
이렇게 UTM값을 기준으로, 유입된 유저가 어느 소스/매체로부터 유입되었고, 유입 키워드/컨텐츠는 무엇인지 분류할 수 있습니다.
3. 주요 용어 구분 [채널 / 매체 / 소스]
: 다음으로는 유입 경로를 구분해주는 [채널 / 매체 / 소스]에 대해서 살펴봅시다.
1) 채널 / 매체 / 소스
| 구분 |
용어 |
정의 |
예시 |
| 그룹 |
채널(channel) |
각 매체에서 여러 소스를 포함하는 집합이나, 매체와 유사하게 구분됨 |
|
| 범주 |
매체(medium) |
소스의 상위 카테고리 or 사용자를 사이트로 보내는 시스템
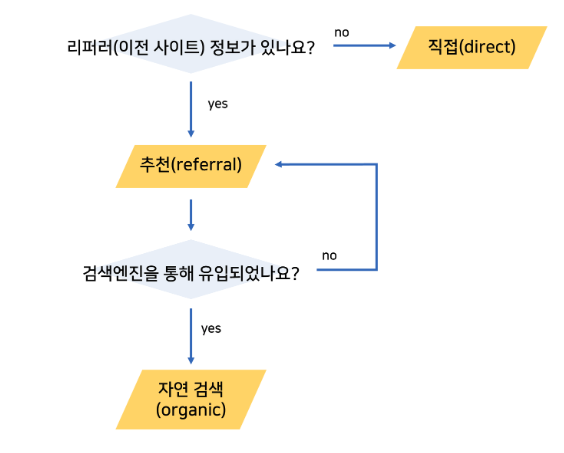
(별도의 추가 설정이 없을 경우 기본값은 none, referral, organic 3가지뿐) |
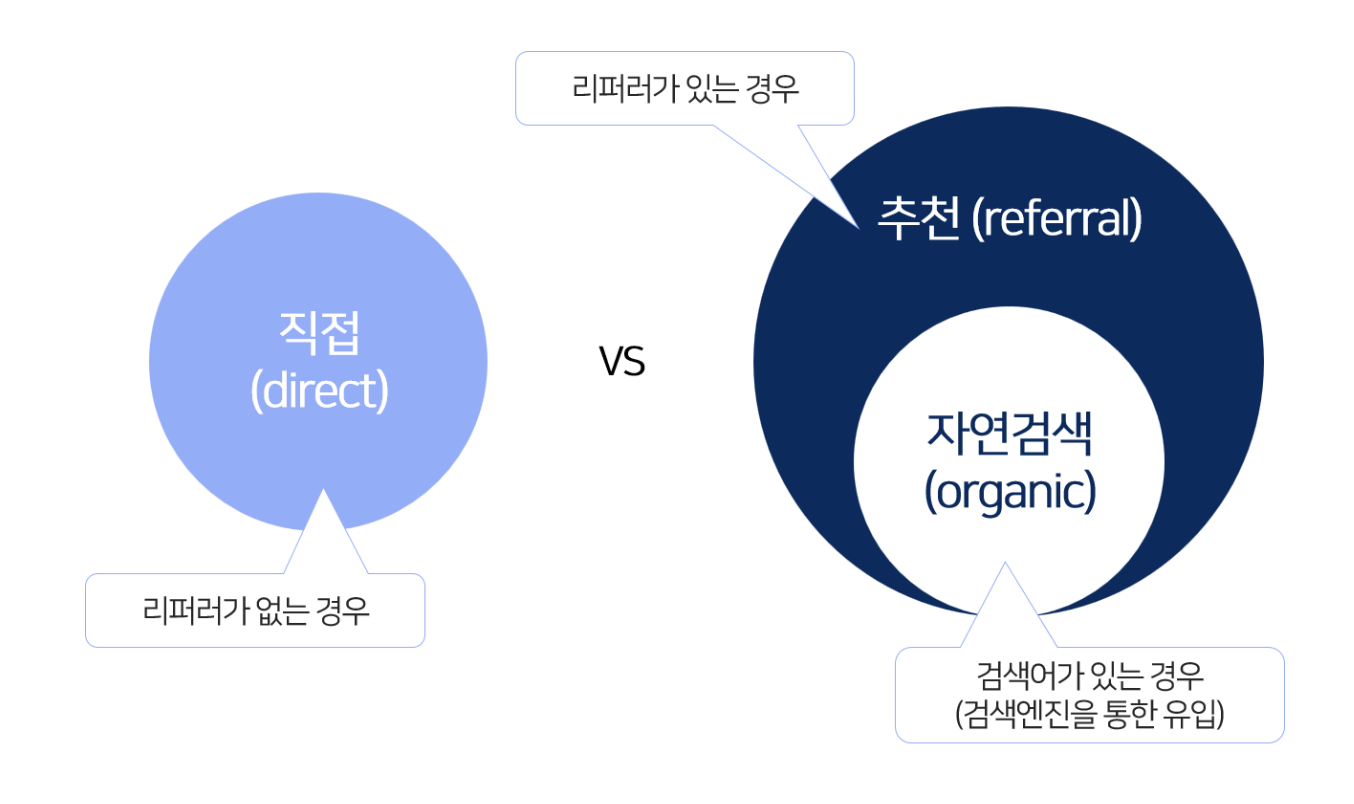
- none(없음)
: 직접(direct) url 입력을 통해 유입되거나, 소스 부재
- referral(추천)
: referral url을 클릭하여 유입
- organic(자연검색)
: 구글/네이버 등 무료 “검색 결과” 유입
- cpc(유료검색)
: 키워드 광고등 유료 검색을 통해 유입
- banner/display(디스플레이)
: 디스플레이/배너 광고 클릭
- social(소셜)
: Instagram, Facebook, Kakao 등
|
| 출처 |
소스(source) |
트레픽이 유입된 위치(검색엔진, 도메인 등) |
[google.com, naver.com, blog.naver.com] |
(1) 소스(source)
: 소스는 트레픽이 유입된 위치(검색엔진, 도메인 등)로, 직전 사이트의 도메인 이름을 의미합니다.
따라서, 비록 “네이버 블로그”와 “네이버 검색”처럼 서로 다른 경로라도, 동일하게 ‘네이버’라는 도메인이라면, 소스값은 ‘네이버’가 됩니다.
추가로 레퍼러 값이 없다면, 소스값은 ‘direct’로 표기됩니다.
- Ex)
- blog.naver.com –> source : ‘naver’
- search.naver.com –> source : ‘naver’
- ’’ –> source : direct
(2) 매체 구분
: 매체는 ‘소스의 상위 카테고리’ 개념으로, 별도의 추가설정이 없다면 구글의 GA에서 기본적으로 분류하는 매체는 크게 3가지로 direct/ referral, organic으로 구분됩니다.
여기서 “별도의 추가설정이 없다면”이란, 네이버 검색을 통해 유입되더라도, 키워드 광고를 통한 유료검색과 무료 검색 2가지로 나뉘나 단순 레퍼러 URL만으로는 이를 구분할 수 없습니다. 따라서 별도의 추가설정인,”키워드 광고 UTM의 매체값에 CPC(유료검색)를 설정해 놓아야” 자연 검색을 통한 유입과 광고 유입을 통한 유입을 구분할 수 있습니다. 이같은 설정을 맞춤 캠페인 설정(custom campaign tagging)이라고 부르며, Campaign URL Builder를 활용하여 UTM값을 수동으로 설정해주어야 합니다.(이번 글은 개념을 구분하는데 있기에, URL Builder 세팅에 대한 내용은 다루지 않습니다.)
<이미지 출처 : analyticsmarketing.co.kr >
- none(없음) : 직접(direct) url 입력을 통해 유입되거나, 소스 부재
- referral(추천) : referral url을 클릭하여 유입
- organic(자연검색) : 구글/네이버 등 무료 검색 결과 유입
- cpc(유료검색) : 키워드 광고등 유료 검색을 통해 유입
- banner/display(디스플레이) : 디스플레이/배너 광고 클릭
- social(소셜) : Instagram, Facebook, Kakao 등
(3) 채널 구분
: 채널에 대한 정의는 “규칙을 기반으로 트래픽 소스를 그룹화한 것”이라고 합니다. (아직은 제 이해가 부족한 것인지 매체와 채널의 차이가 크지 않아보입니다.)
매체와 채널은 굉장히 유사한 개념으로 보이며, 앞서 utm을 살펴보면 매체(medium)값은 수집되는 값이지만, 채널(channel)값은 따로 utm url을 통해 수집되는 것이 아닌, GA 구분을 통해 생성되는 것 같습니다. (개인 추측)
- 매체 : 소스를 마케팅 수단으로 그룹핑한 카테고리
- 채널 : 수집된 소스/매체값을 그룹핑한 카테고리
<이미지 출처 : 파인데이터랩 >
Reference
[1] [GA기본] 5-2. 구글애널리틱스 표준 보고서 (Standard reports) - 분석마케팅
[2] 2022_디지털마케팅(30) 구글 애널리틱스(38) - 채널 분석
[3] 구글애널리틱스(GA) 사용법 : 획득보고서
10 Apr 2023
배경 상황
앞단계에서, pyenv를 활용하여, 복수의 파이썬 버전을 사용할 수 있게끔 셋업을 끝냈다면,
pipenv를 활용한 가상환경을 구축하고, 원하는 특정 버전의 python 버전으로 프로젝트를 구축해보려합니다.
(pipenv 외에도, virtualenv 등을 활용한 가상환경도 가능합니다.)
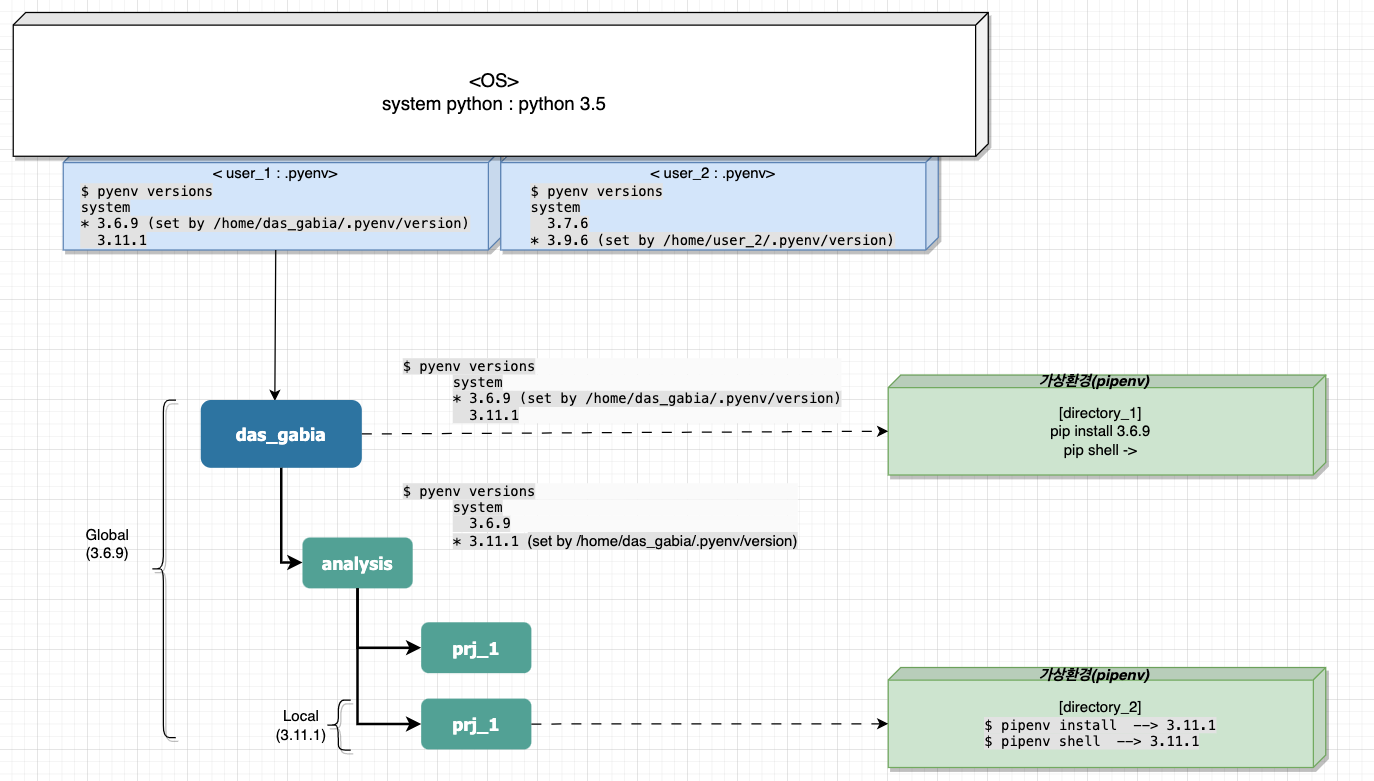
pyenv & pipenv를 활용하여, 디렉토리별로 다른 환경 구축
1. pip 경로 확인
- pyenv로 python을 설치해주었고, 문제가 없다면 pip는 .pyenv에 설치된 python의 경로를 바라봐야합니다.
- 그러나 간혹 기존에 system에 설치되었던 python을 여전히 바라보고 있어, pipenv 가상환경을 설치시 여전히 os에 설치된 system버전의 python으로 가상환경이 생성되는 경우가 있음. 따라서 가상환경 생성 전, 해당 디렉토리가 어떤 파이썬 인터프리터를 바라보고 있는지 확인 합니다.
1) python version 확인
which python
# /usr/bin/python
pyenv versions
# * system (set by /home/th/.pyenv/version)
2) pipenv version 확인
: pip 버전에 맞는 python 버전이 있기에, 바라보고 있는 python 버전과 pip 버전이 서로 맞아야함.
pipenv --version
# pipenv, version 2018.11.26
2. pipenv 가상환경 설치 & 실행
: 가상환경은 계정 상위 폴더에서 전체로 진행하기보다는 하위 디렉토리(프로젝트)별로 생성하기를 추천.
### 1) pipenv 설치
pipenv install --python {버전명} # ex) pipenv install --python 3.6.9
### 2) pipenv 가상환경 실행
pipenv shell
3. Pipfile 패키지 관리
- 앞서
pipenv install을 실행할 때, 해당 디렉토리 내에 .Pipfile이 존재한다면, pipenv는 .Pipfile을 기준으로 패키지들을 함께 설치하게 됩니다.
- 그러나 상황에 따라,
.Pipfile을 뒤늦게 Pull하게 될 수도 있고, 패키지들이 설치되어 있지 않을 수 도 있기에, 수동으로 .Pipfile내의 패키지들을 설치하라고 명령해야 할 수 도 있습니다.
- 이때
.Pipfile과 관련된 파일들은 아래와 같습니다.
- (1)
.Pipfile.sh : .Pipfile.toml을 실행하라는 실행파일 (실행 방법 $ .Pipfile.sh 그대로 입력)
- (2)
.Pipfile.toml : 해당 Pipenv 가상환경이 유지할 패키지들을 작성해둔 파일로, .Pipfile을 생성하는 파일
- (3)
.Pipfile : 현재 가상환경에 설치할 패키지들을 명시한 파일 (.Pipfile.toml을 실행하면, 해당 문서에 작성된 버전들이 명시됨)
4.pipenv 가상환경 삭제
## 1) 해당 가상환경이 설치된 디렉토리로 이동
## 2) 가상환경 삭제
pipenv --rm
Reference
[1] 01) pyenv와 가상환경
[2] pyenv란? pyenv 사용하기
[3] [python] pyenv? virtualenv?