16 Jan 2023
#python, #docker, virtual_envrioment
이 글은 zini님의 GitBlog "Docker(도커) 시작하기, 설치부터 배포까지" 컨텐츠를 정리한 글입니다.
3. 나만의 이미지 생성하기(ft. Dockerfile)
Reference
[1] Docker(도커) 시작하기, 설치부터 배포까지 - zini님의 git blog
[2] Docker : 이미지와 레이어(layer) 구조
16 Jan 2023
#python, #docker, virtual_envrioment
이 글은 zini님의 GitBlog "Docker(도커) 시작하기, 설치부터 배포까지" 컨텐츠를 정리한 글입니다.
배경 상황
: 통상 사용하려는 패키지의 버전이 서로 다를 경우, 각 분석 환경을 독립적인 가상 환경으로 구축하여 사용한다.
그런데 이때 패키지의 버전이 아닌, 파이썬 자체의 버전이 낮아 패키지 사용이 불가능한 케이스가 발생했다. 서버에 설치된 파이썬을 업데이트하려했으나, 기존의 파이썬 버전도 유지해야하는 이슈가 존재했다.
이에 서버내에 복수의 파이썬을 설치하여, 버전별로 바라보는 경로를 다르게 잡는 방법도 존재하나, 독립적인 경로 설정의 어려움 및 서로 다른 파이썬 버젼에 따른 패키지간 충돌이 우려되었다. 때문에 이보다는 docker를 사용하여 독립적인 컨텐이너를 구축하여, 별도의 환경을 만들어 분석을 진행하고자 하였다.
Docker Intro
1) Docker : Image & Container
: 도커에서 가장 중요한 개념은 컨테이너와 이미지 !!
- 이미지 : 도커 컨테이너를 구성하는 파일 시스템과 실행할 어플리케이션 설정을 하나로 합친 것으로, 컨테이너를 생성하는 템플릿 역할을 하며, 불변함.
- 컨테이너 : 도커 이미지를 기반으로 생성되며, 파일 시스템과 어플리케이션이 구체화되어 실행되는 상태.
따라서, 동일한 이미지로 다수의 컨테이너를 생성할 수 있고 컨테이너에 변화가 생겨도 이미지에는 영향을 주지 않는다.
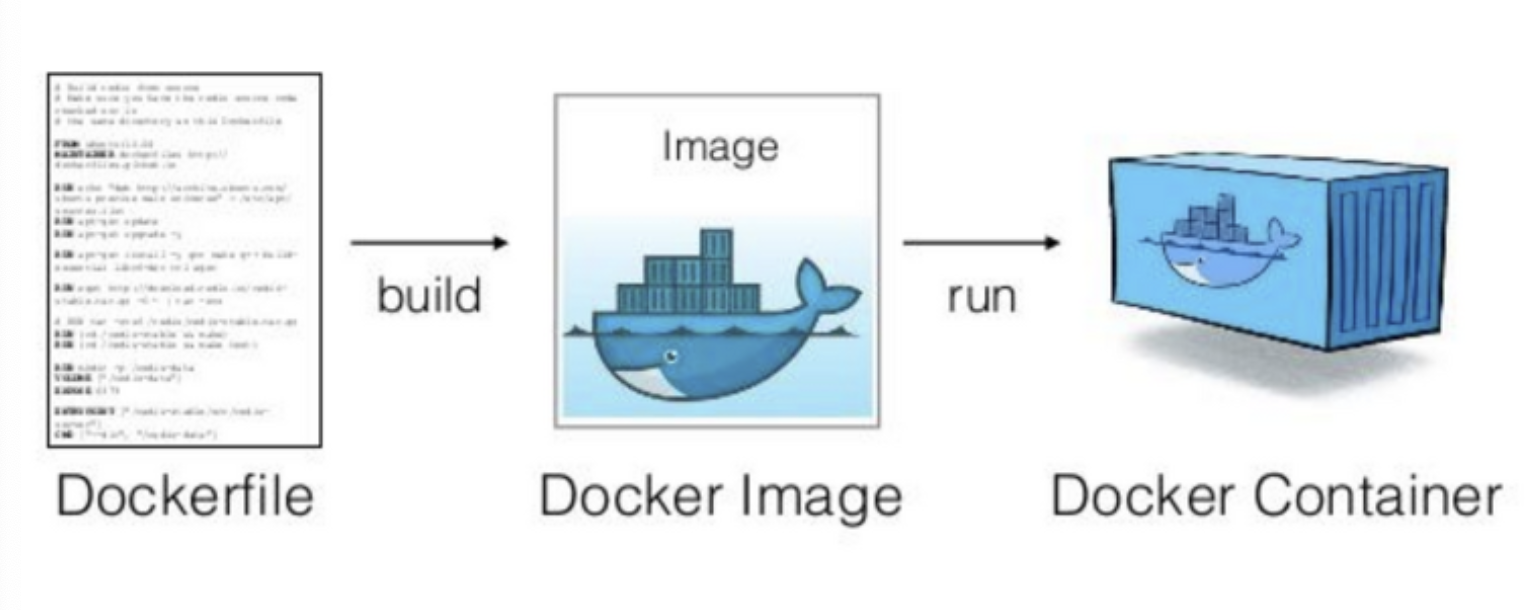
2) Docker : Layer
: 도커 이미지는 컨테이너를 실행하기 위한 모든 정보를 갖고 있기에 용량이 수백 MB이다. 처음 컨테이너를 만들기 위해서 이미지를 다운로드하는 건 필요하지만, 이미지의 불변성 때문에 현재 이미지에 작은 수정사항이 생길 시 새롭게 이미지를 다운로드 받기위해 수백MB를 다시 다운로드 받는 다면 매우 비효율적일 것이다.
도커는 이 문제를 해결하기 위해, 레이어(Layer)라는 개념을 사용하여, 여러개의 레이어를 하나의 파일 시스템으로 사용할 수 있게 해준다.
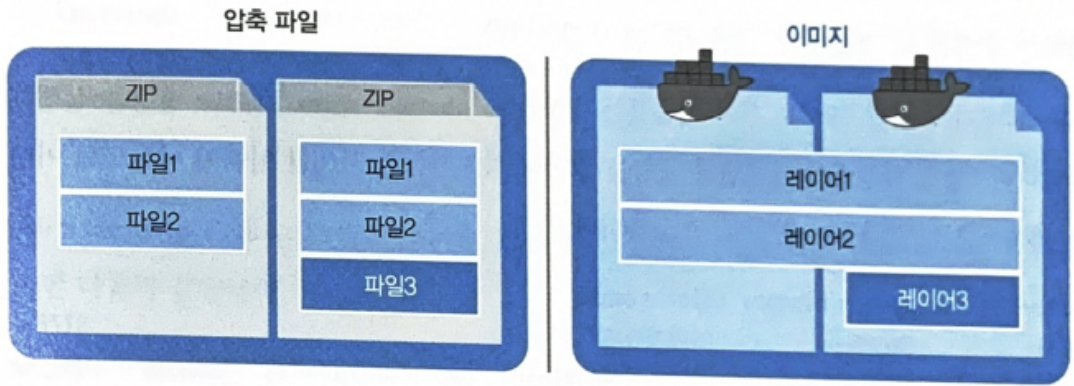 도커의 이미지는 압축파일과 유사한 구조를 갖지만,
도커의 이미지는 압축파일과 유사한 구조를 갖지만,
레이어를 공유한다는 점에서는 차이점을 지닌다.
2. Docker Setup
도커 설치는 자동 설치 스크립트를 사용하는 방법과 패키지를 직접 설치하는 방식 2가지로 나뉜다.
1) Docker 설치
(1) 자동 설치 스크립트
sudo wget -qO- https://get.docker.com/ | sh
## hello-world 이미지도 같이 설치되는데, 사용하지 않을시 삭제
sudo docker rm 'sudo docker ps -aq'
sudo docker rmi hello-world
(2) 패키지 직접 설치
# 도커 설치 완료 확인
sudo docker version
(3) +Tip. 패키지 직접 설치
: docker는 명령을 root 권한으로 실행해야 하기 때문에
명령어를 쓰기 위해서는 항상 sudo를 붙여줘야 한다.
이때, 일반적으로 root로 작업하는 경우는 많지 않기에, 일반 계정을 docker group에 추가하여 sudo를 입력하지 않고 사용 할 수 있다.
sudo usermod -aG docker ${USER}
sudo service docker restart
2) 도커 이미지 다운로드 & 실행
(1) 도커 이미지 다운로드
: 도커 이미지는 1) docker_hub 공식 이미지 다운 , 2) 직접 생성, 3) 다른 사용자가 만들어둔 이미지 다운 받는 방법이 있다.
- Docker Hub에서 이미지 받기 :
docker pull <이미지 이름>:<태그>
- 사용자 이미지 받기 :
docker pull <username/imagename>:<tagname>
docker pull ubuntu:latest # 우분투 최신 버젼 다운로드
docker pull ubuntu:18.04 # 우분투 특정 버젼(18.04) 다운로드
docker pull python # python
(2) 도커 이미지 실행 (= 컨테이너 생성)
: docker run <옵션> <이미지 이름> <실행할 파일>
# 1) 다운로드한 이미지 목록 확인
docker image
# 2) ubuntu 이미지를 컨테이너로 생성 후 이미지 안의 /bin/bash를 실행
docker run -it --name hello ubuntu /bin/bash
# docker run [-it] [--name 별명] <ubuntu> /bin/bash
### -it 옵션을 사용하면 실행된 Bash 쉘에 입출력을 가능하게 해줌.
### --name 옵션을 사용하면 컨테이너 이름을 지정 (미지정시 자동으로 이름 부여)
#
(3) 도커 컨테이너에서 나오기
: 위 명령어에서는 bash(terminal)을 실행하는 명령어까지 입력했기에, exit으로 빠져나오면, 컨테이너가 정지 상태로 변경된다.
Reference
[1] Docker(도커) 시작하기, 설치부터 배포까지 - zini님의 git blog
[2] Docker : 이미지와 레이어(layer) 구조
10 Jan 2023
#python, #docker, virtual_envrioment
—
1. 도커 컨테이너 접속 & 종료 & 삭제
# 1) 컨테이너 리스트 출력
docker ps -a #모든 컨테이너 출력(정지 컨테이너 포함)
docker ps #실행 중인 컨테이너만 출력
# 2) 컨테이너 시작
docker start hello #hello 이름의 컨테이너 시작
docker restart hello #hello 이름의 컨테이너 재시작(재부팅)
# 3) 컨테이너 접속
docker attach hello #컨테이너에 접속(bash 쉘 접속)
# 4) 컨테이너 종료
docker stop hello #hello 이름의 컨테이너 종료
# 5) 컨테이너 삭제
docker rm hello #hello 이름의 컨테이너 삭제
docker rm -f hello #hello 이름의 컨테이너 강제삭제
Reference
[1] 도커-명령어-모음
[2] Docker : 이미지와 레이어(layer) 구조
02 Jan 2023
해당 내용은 화해의 기술블로그 중 오세창님(데이터팀 리드)의 글 ‘데이터 리터러시(Data Literacy)를 올리는 방법’을 정리한 내용입니다.
1. 데이터 리터러시(Data Literacy)란?
: “데이터를 활용해 문제를 해결할 수 있는 능력”
데이터를 잘 활용한다는 것은,
데이터를 활용해 문제를 잘 정의하고 & 해결할 수 있다는 말이고,
데이터를 잘 활용하도록 만들려면,
데이터/실험 기반 사고방식이 자리잡혀야 하며,
분석 흐름대로 데이터를 탐색할 수 있는 환경이 필요 (supported by 데이터 분석가)
* 기존 문제
: 기존 요구하는 지표 전달를 빠르게 제공하는 것에만 초점을 맞추다보니 아래와 같은 문제 발생
- 문제_1 : 해결하려는 문제와 전혀 상관없거나 효과가 매우 미미한 지표가 요청됨.
- 문제_2 : 특정 문제를 해결하기위해, 관련됐다고 생각된 모든 지표를 살펴보다보니, 되려 의사결정이 어려움.
---[before] 신규 기능 관련 이벤트 성과 측정을 위한 데이터 요청---
- 전면팝업 데이터
- 노출수, 클릭수, 노출(유니크), 클릭(유니크)
- 이벤트 참여 데이터
- 전체조회수, 유니크조회수
- 전체참여수, 옵션별 선택 수
- 일자별 이벤트 참여수
- 신규유저/기존유저 각 참여자수
- 이벤트 기간 내 신규 설치수
- 이벤트 기간 내 신규 가입수
- 신규 기능 관련 데이터
- 이벤트 진행 전/후 신규 기능 경험 수치 변화
- 이벤트 진행 전 1달
- 이벤트 진행 기간
- 이벤트 뷰어 & 참여자의 신규 기능 경험 수치
<center>[after] 신규 기능 관련 이벤트 성과 측정을 위한 데이터 요청</center>
- 해결하려는 문제
- 신규 기능에 대한 인지가 부족한 문제
- 솔루션
- 신규 기능에 대한 브랜딩 활동을 통해 신규 기능 인지 강화
- 측정 지표
- 이벤트 조회자수
- 이벤트 참여자수
** 단 건의 앱 내 이벤트를 통해서는 기능의 사용성을 단기간에 올리기 어려우므로, 장기적으로만 모니터링
1) 해결하려는 문제 (문제정의)
2) 솔루션
3) 측정 지표
2. 데이터/실험 기반 사고 방식 $\star$
* 실험 프로세스 / 실험보드
: 데이터/실험 기반 사고방식이 만들어 지려면, 모든 업무들이 데이터와 실험 기반으로 이뤄지는 환경 구축이 필요했음. 따라서 실제 진행중인 업무들부터, 데이터 기반 사고방식으로 실행되도록 유도함. 이런 방식이 자연스러워지도록,데이터 기반 실험 프로세스 프레임을 도입. 해당 프로세스의 목적은 1) 실험 횟수를 높여 성과 증대의 목표와 함께 2) 데이터 중심 문제 해결능력 배양.
[실험 프로세스]
- 1) 해결하려는 문제 ➡️ 문제정의
- 2) 관련 OKR ➡️ 전사 목표와 align 되어있는지
- 3) 측정 지표 ➡️ 문제와 지표가 align 되어있으며, 측정 가능한 것인지
- 4) 검증 기준 ➡️ 성공 여부를 어떻게 판단할 것인지
- 5) 검증 후 변화될 액션 ➡️ 의미없는 액션을 하는게 아닌지
- 6) 결과 ➡️ 검증 기준으로 결과가 나왔는지
- 7) 학습한 점 ➡️ 어떤 학습을 했고, 다음 실험에는 어떻게 반영될 것인지


3. 분석 흐름대로 데이터를 탐색할 수 있는 환경 $\star$
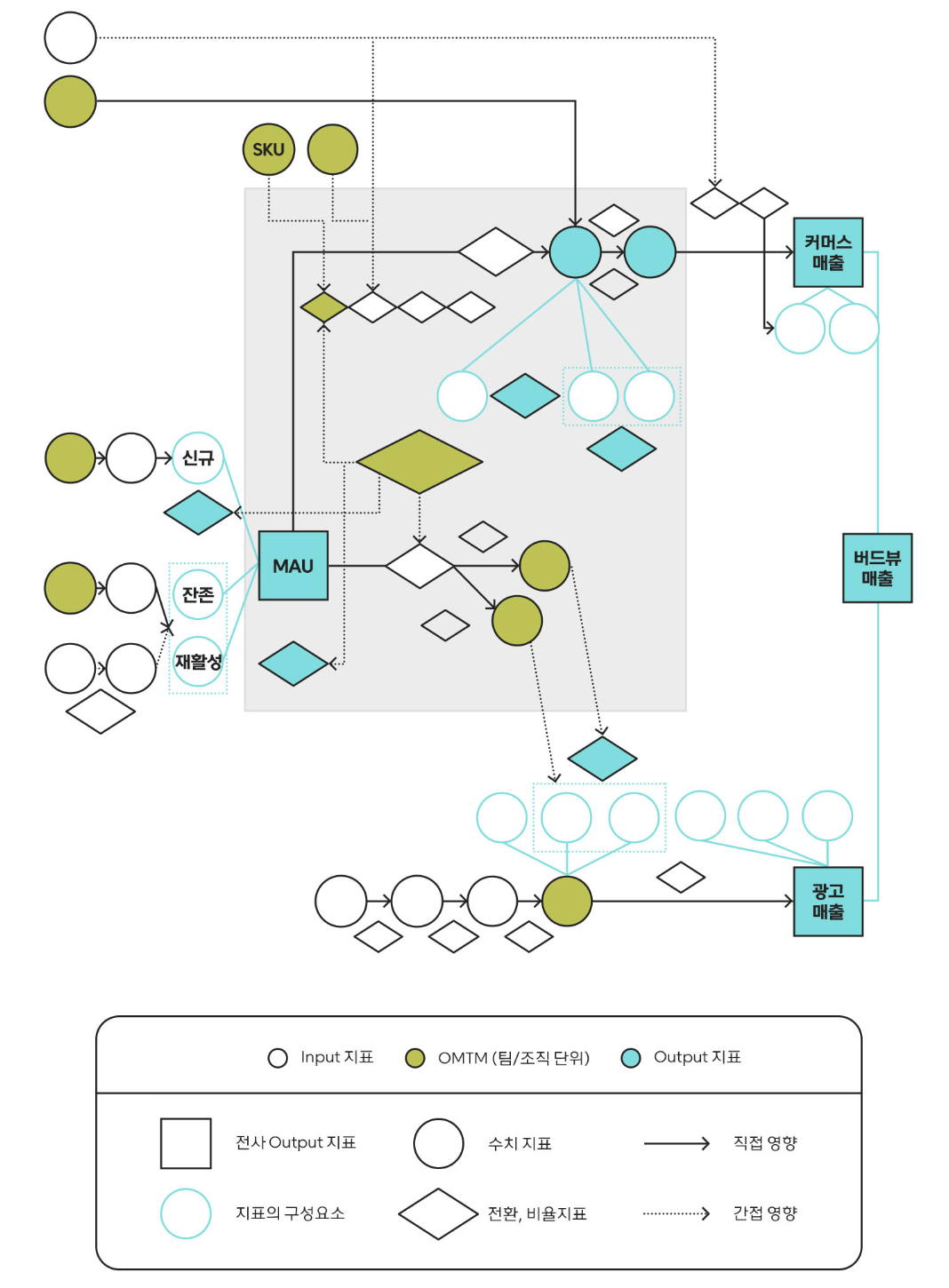
1) 데이터 맵
(a) 데이터 맵 도입 배경
: 그러나 문제를 잘 정의하려면 여전히 분석가와 함께 논의를 해야 하는 어려움이 남아있었음. 때문에 분석가 없이도 가장 중요한 지표에 집중할 수 있도록 전사에서 다루는 중요한 인풋 지표와 아웃풋 지표 간의 관계를 표현한 관계도를 제작·공유함.
(b) 데이터 맵 원칙
: 단순히 모든 지표를 도식화한다고 하면 너무 많은 지표들이 담길 수 있기 때문에 보다 중요한 지표에 집중하기 위해 인풋 지표 설정에 중요한 원칙 두 가지를 설정
- 1) 측정 가능
- 2) 직접적으로 control 가능
- 3) 데이터 관계가 쉽게 이해될 수 있어야함.
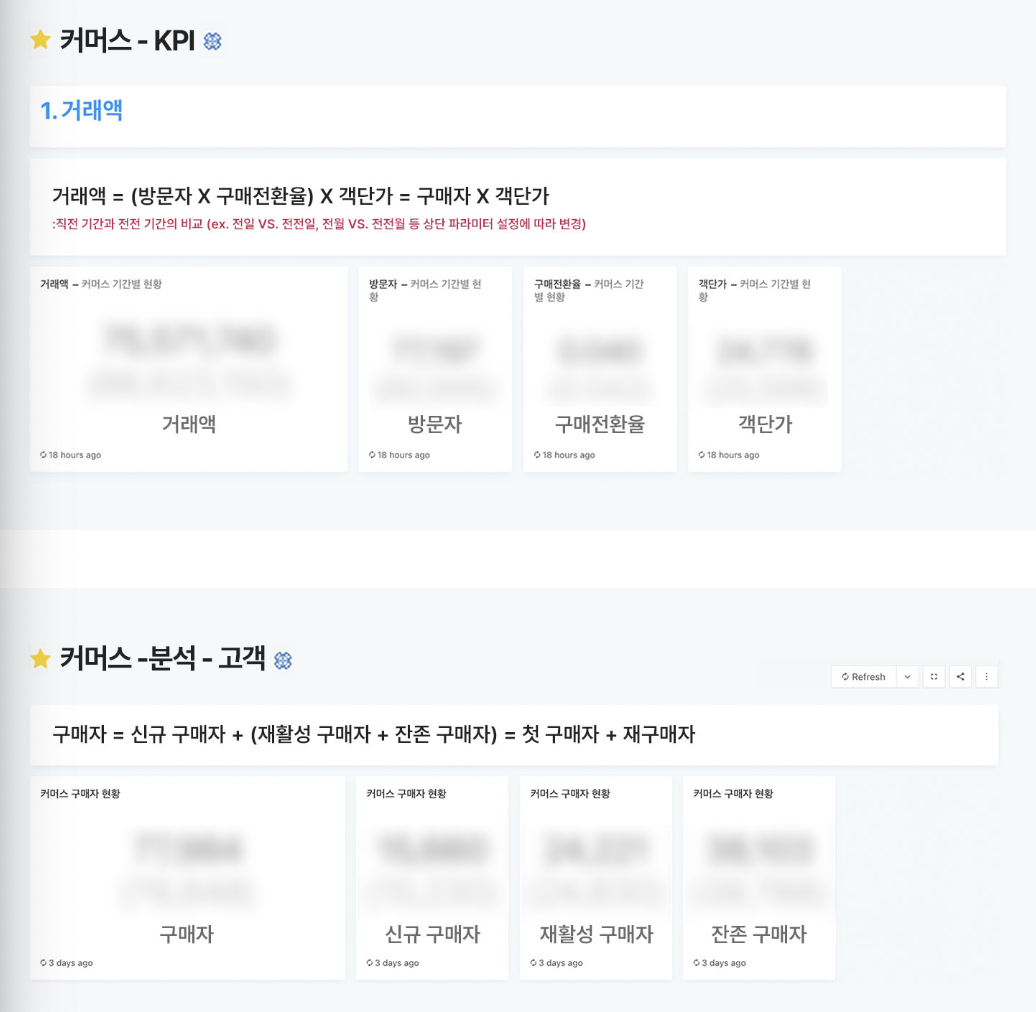
2) 대시보드
(a) 대시보드 도입 배경
: 지표 관계를 잘 이해하게 되었다면, 다음은 그 흐름에 따라 지표의 현재 수준을 확인할 수 있는 환경이 필요하였으며, 분석 흐름을 따라가면서 지표들을 탐색할 수 있도록 대시보드 설계하였음. 대시보드를 활용해 분석가가 아닌 구성원들도 중요한 지표 변동과 원인을 파악하는 분석 정도는 스스로, 그리고 빠르게 할 수 있어야 함.
(b) 대시보드 원칙
- 분석 흐름을 따라가면서 지표들을 탐색.
- 최상위 문제를 발견하면, 각 지표와 관련된 하위 지표들이 구성된 분석 대시보드 내에서 원인을 짐작할 수 있어야함.
4. 이 과정을 도와주는 분석가
데이터 분석가(Data Scientist)
: 우리는 분석가의 역할이 단순히 데이터를 추출하고, 분석 내용을 리포팅하는 것에만 그쳐서는 안된다고 생각합니다. 1)문제를 정의하고 2)원인을 분석한 뒤에는 3)액션 아이템까지 도출해 리포트를 제공받은 4)협업팀이 실행에 옮기도록 만들어야 합니다.
<분석가의 역할을 명확히 할 수 있는 JD(Job Description)>
- 제품/비즈니스 성장을 위한 지표 설계 및 대시보드를 개발
- 제품/비즈니스 문제 해결을 위한 실험을 설계
- 핵심 지표 모니터링 및 지표 변동의 root cause를 분석
- 데이터 분석 결과를 바탕으로 실질적인 액션 아이템을 제안
- 데이터 기반 사고와 실험 활성화를 위한 전사적인 코칭 및 컨설팅 역할을 수행
그리고 매 분기마다 우리가 기대하는 모습을 가장 중요한 OKR로 설정해 모든 분석가의 업무 방향성을 일치 시켰습니다.
KR : 분석가의 산출물로 협업팀/밴드 과제지표 및 전사지표의 성장 또는 중요 의사결정 견인(1인당 월 2회 달성)
데이터 플랫폼
: 분석가뿐만 아니라 많은 구성원들이 빠르게 분석할 수 있으려면 데이터를 빠르게 준비해 사용할 수 있는 구조가 필요합니다.
- 데이터 레이크 : 모든 원천데이터가 적재
- 구조화된 데이터 웨어하우스 : 신속하게 정확한 데이터를 추출
- 데이터 카탈로그 : 레이크/웨어하우스 내에 어떤 데이터가 있는지 쉽게 확인
데이터 웨어하우스와 카탈로그는 분석가들이 실질적인 분석 업무를 빠르게 수행할 수 있도록 도와줍니다. 분석가가 아니더라도 SQL을 알고있는 구성원이라면 본인이 필요한 데이터는 SELECT, FROM, WHERE, GROUP BY 정도만 작성하면 쉽게 얻을 수 있습니다.
데이터 웨어하우스를 통해 분석가의 업무 효율은 비약적으로 상승했고, 본질적인 분석 업무에 더 많은 시간을 할애할 수 있게 되었습니다. 분석파트에서 조직이 성장한 점을 리뷰할 때마다 데이터 웨어하우스 구축은 가장 손꼽히는 변화이자, 업무에 가장 큰 도움을 준 요소라고 말할 정도니까요.
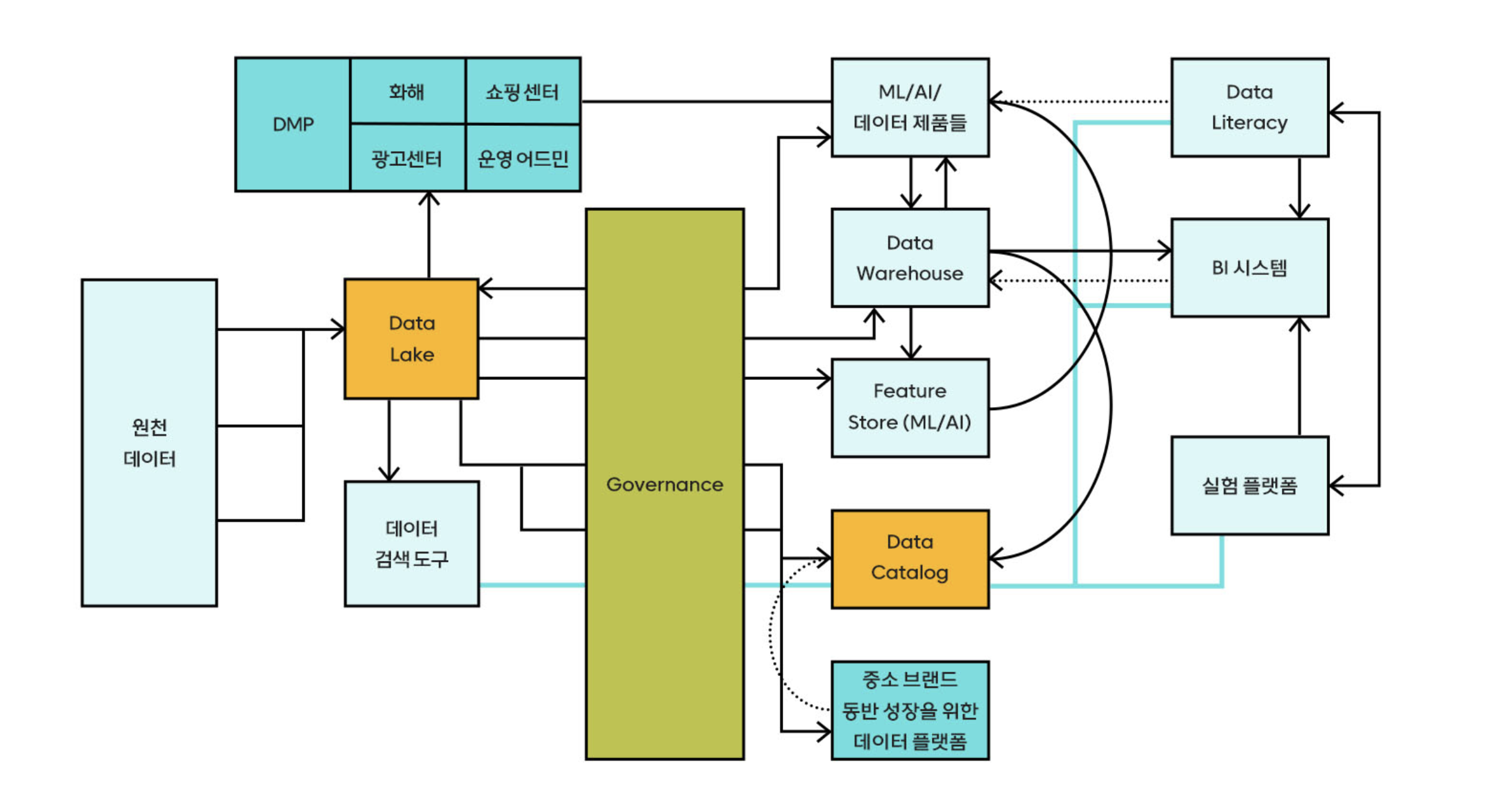
src : 화해의 Data Warehouse를 소개합니다(화해 블로그) - by 최혜림
5. 맺음말
: 앞서 말씀드린 것처럼 저는 데이터 리터러시를 데이터를 활용해 문제를 해결할 수 있는 능력이라고 정의하고 있습니다. 하지만 단순히 구성원들에게 데이터를 보여주는 것만으로 문제 해결력이 좋아지지는 않았습니다. 구성원들이 데이터를 바라보는 올바른 관점을 만드는게 가장 중요했고, 이 관점을 유지·강화 시키기 위한 환경이 필요했습니다.
이때 경영진들의 강한 지지가 환경을 조성하는 데 중요한 역할을 했습니다. 그 뿐만 아니라 화해팀 모두의 노력과 적극적인 참여를 통해 화해팀은 데이터를 활용해 문제를 해결하는데 매우 익숙한 조직으로 변화해왔습니다. 조직 전체의 데이터 리터러시를 높이고 이를 통해 성과들이 만들어지도록, 저희 데이터팀은 더 좋은 환경과 구조들을 만들어나갈 예정입니다.
Reference
[1] 데이터 리터러시(Data Literacy)를 올리는 방법(화해 블로그) - by 오세창
30 Oct 2022
: 일상적인 데이터는 주로 각 피쳐를 column으로 가져가지만, 시각화를 필요로하는 경우엔 각 피쳐값을 하나에 컬럼에 모아, 다시 새로운 변수로 할당해주는 형태인 long-form 형태의 데이터 변환이 필요하다. 이때 주로 사용하는 함수들이 상황에 따라 매번 햇갈려 정리가 필요했다. 해당 자료는 “rfriend” 내용을 정리하였다.
1. Long to Wide (pivoting)
(1) pivot
: pd.pivot함수도 있으나, 기능이 유사하고 더 범용적인 pivot_table함수만 정리

pd.pivot_table(df, index=, columns=, values=)
-
- index
- wide 형태 데이터에서, 인덱스 역할을 할 컬럼
-
- columns
- N개의 Column을 생성하기 위한, 정보를 가져올 Column
(2개 이상의 Column을 지정할 경우, 멀티 컬럼 형태의 WideFormData생성)
-
- values
- Column에서 지정한 필드에 상응하는 값이 존재하는 Column
-
- margins
- True로 설정시, 행과 열을 기준으로 합계(All, row sum, column sum)를 같이 제시
2. Wide to Long (melt)
: 주어진 WideFormData를 아래로 길게 녹여내듯 LongForm으로 변환
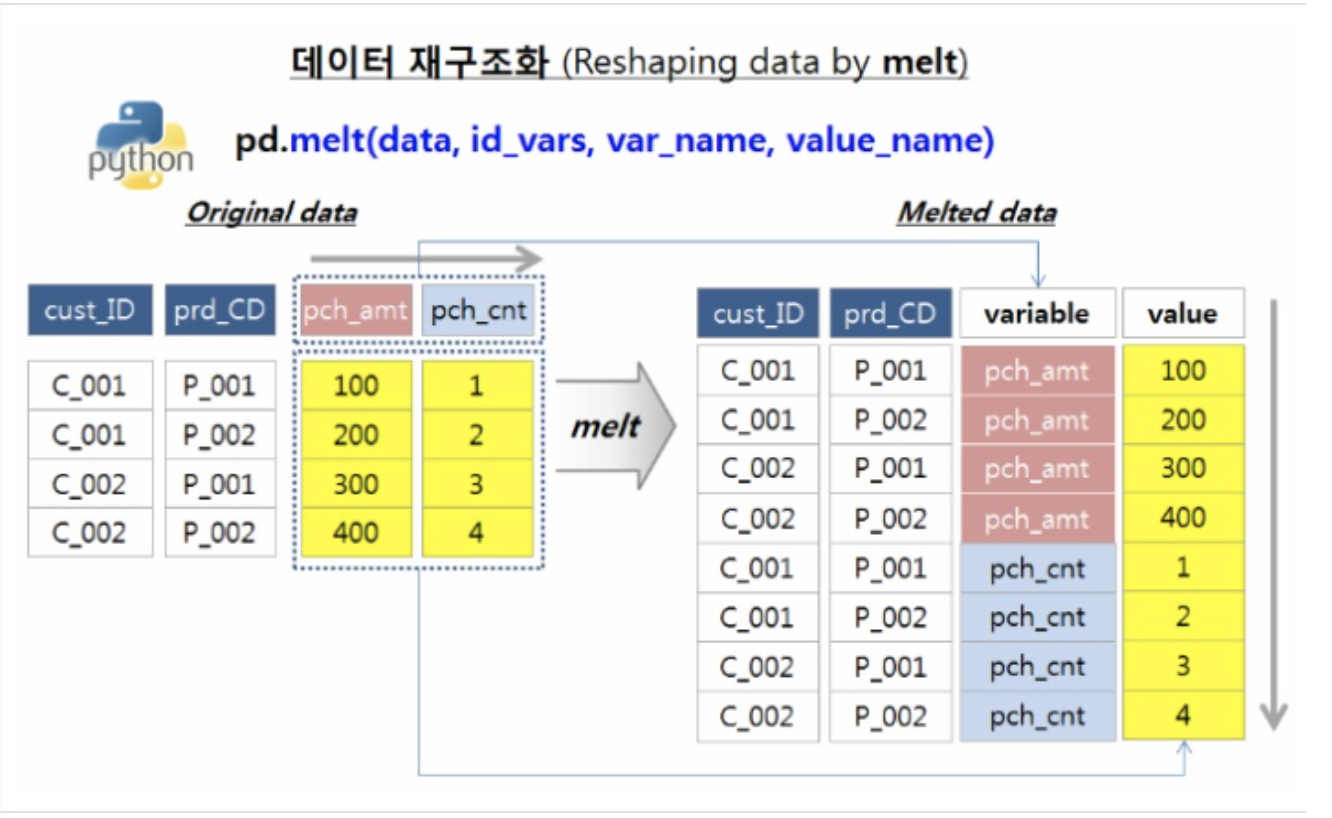
pd.melt(data, id_vars=['id1', 'id2', ...])
-
- id_vars
- longform 데이터의 인덱스 개념이 될 컬럼(column 레벨이며, index레벨이 아님.)
-
- var_name
- (default : None) Category or Group과 같이 값의 구분자가 될 필드명
-
- value_name
- (default : value) value값 column명
3. Stack <-> Unstack
: 앞서 pivot과 melt함수는, transpose를 위해 기준이 되는 column들을 인자로 지정해주었던 반면, Stack & Unstack 함수는 어떤 데이터를 주어주던 필요한 형태로 변환하는 목적에 충실한 느낌이다.
- Stack : wide to “long”
- Unstack : long to “wide”
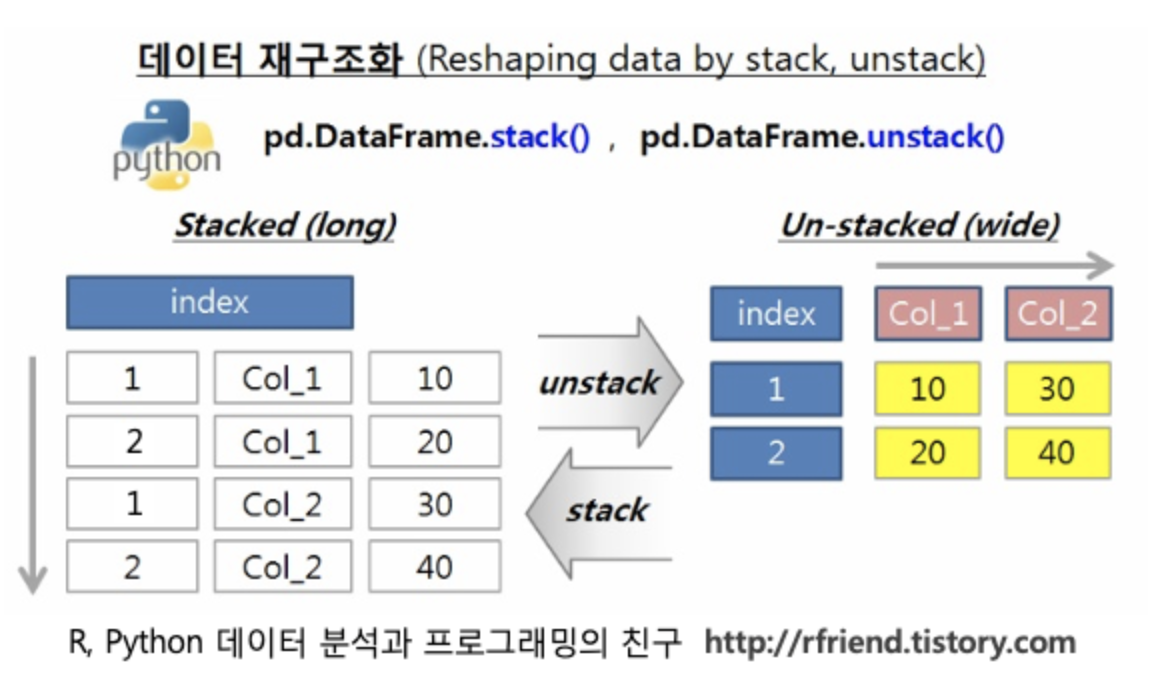
(1) Stack
pd.DataFrame.stack(level=-1, dropna=True)
data_wide
# [output]
# cust_id prod_cd grade pch_amt
# 0 c1 p1 A 30
# 1 c1 p2 A 10
# 2 c1 p3 A 0
# 3 c2 p1 A 40
# 4 c2 p2 A 15
data_wide.set_index(['cust_id', 'prod_cd']).\
stack(level = -1).to_frame().head(10)
# [output]
# 0
# cust_id prod_cd
# c1 p1 grade A
# pch_amt 30
# p2 grade A
# pch_amt 10
# p3 grade A
# pch_amt 0
# c2 p1 grade A
# pch_amt 40
# p2 grade A
# pch_amt 15
(2) UnStack
pd.DataFrame.stack(level=-1, dropna=True)
data_long
# [output]
# 0
# 0 grade A
# pch_amt 30
# 1 grade A
# pch_amt 10
# 2 grade A
# pch_amt 0
# 3 grade A
# pch_amt 40
# 4 grade A
# pch_amt 15
data_long.unstack()
# grade pch_amt
# 0 A 30
# 1 A 10
# 2 A 0
# 3 A 40
# 4 A 15
Reference
[1] 데이터 재구조화_1 : pivot & pivot_table
[2] 데이터 재구조화_2 : melt
[2] 데이터 재구조화_3 : stack & unstack