03 Feb 2022
: 데이터 분석을 하다보면, 연간/분기/특정기간내 서비스 전체 또는 주요 지표들에 대해서 리포팅을 해야하는 상황이 생겨난다. 이에 데이터 분석 리포팅 작성시, 절차 및 이슈들을 정리해보자.
이때 각자의 문제 상황에 따라서 리포팅 작성 방식은 다를 수 밖에 없기에, 특정 문제를 해결하기 위한 FrameWork라고 보면 좋을 것 같다. 또한 본글은 개인적 경험과 일부 리서치에 기반하였기에, 지속적인 수정 & 보완이 필요하다.
아래 작성한 개인 경헙에 기반한 분석 방법론 외, 체계화 되어있는 방법론들은 아래 링크를 참고하자
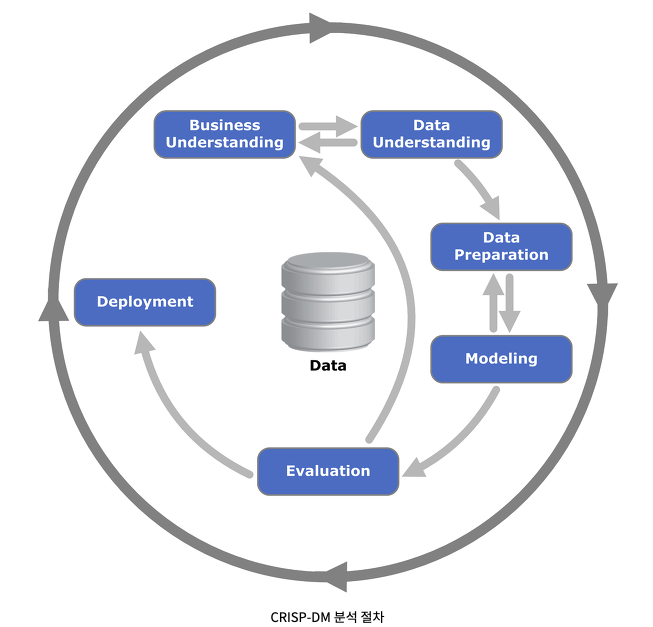 [데이터_분석계획_빅데이터_분석기획 by noti-note님 블로그](https://noti-note.tistory.com/12)
[데이터_분석계획_빅데이터_분석기획 by noti-note님 블로그](https://noti-note.tistory.com/12)
1. 문제정의 $\star\star\star$
1) Why : 리포팅을 왜 하는 것일까? $\star$
: 리포트를 보는 대상에 따라서, 문제정의 작성 및 리포팅의 이유가 크게 달라진다.
특정 문제에 국한된 리포트 또는 Daily리포트는 주로 실무자나 중간급에서 빠른 의사결정 및 진행상황을 체크하기 위함이기에 문제정의가 명확하다.
반면, 리포트 작성의 이유가, 전반적인 서비스 평가 및 서비스 지속 인사이트 추출이라는 모호한 경우가 있다. 주로 중장기간의 서비스 전체 또는 KPI 2,3개 이상의 리포트를 작성하여 상급자에게 리포트를 하는 경우이거나, 아직 데이터로 구체적인 KPI를 잡지 못하여 모니터링 조차 하지 못하는 팀에서 “전체적인 탐색적 분석을 하며 인사이트를 찾고 싶어요”라는 막연한 요청을 하는 경우가 주로 이러하다.
이런 막연함 속에도 “우리의 서비스가 얼마나 효율적으로 또는 어떤 방향으로 운영되고 있으며”, “어떤 문제가 있는지”, “분기별로 얼만큼의 성과를 이루었는지” 등의 목표가 존재한다. 추상적인 목표를 아래 분석 항목별로 나눠, 구체화 시키는 작업이 필요하다.
2) What : 무엇을 분석할 것인가? $\star$
: 커머스 서비스 가정하에 탐색적 분석을 진행하기 위하여, 고객 여정별 분석 항목을 정리해보자.

(1) 유입 (Acqusition)
- 앱설치자수 (total / daily)
(2) 유입 채널 (Attribution)
- 채널별 앱설치자수(유입자수) (total / daily)
- 채널별 유입자 *KPI 전환율 (KPI : 회원가입 / 구매 / ETC)
- 채널별 Fraud / Bounce 유저수 (total / daily)
(3) 활성화 (Activation)
- 회원가입자수 (total / monthly / weekly / daily)
- 회원가입 전환율 (total / monthly / weekly / daily)
(4) 유지 (Retention)
- 접속 빈도 : DAU / WAU / MAU
- 접속 빈도 : 평균 접속주기
- 사용 시간 : 세션당 평균 사용 시간 (집단별 / daily)
- 퍼널 분석 : 설치 > 가입 > 상품 조회 > 상품 구매 > 재구매
(기간별 / 집단별 비교)
(5) 참여 & 커머스 (Engagement & Commerce)
- 참여 : 특정 이벤트 유입자 및 회원가입 등 KPI 지표
- 참여 : 공유 조회 활성 유저수 (total / monthly / weekly / daily)
- 커머스 : 상세페이지 조회 & 조회자수
- 커머스 : 구매 & 구매자수 (total / monthly / weekly / daily)
- 커머스 : 재구매 & 재구매율
- 커머스 : 조회 & 구매 상품 Top 10
- 커머스 : 구매 전환율 (사용자 그룹별 / 기간별 / 상품별)
- 커머스 : 구매 금액 / 인당 평균 구매액
- 커머스 : Pair 분석
(6) 이탈 (Churn)
- 최근 7/14/28일 이탈율 (동기간 대비 / 집단별 / 일별)
- Bounce / Farud 유저수 / 비율
(7) 도달 (Reachability)
- 메시지 퍼널 : 발송자 > 오픈자수 > 오픈자 중 구매자
- 메시지 성과 분석 : 시간대별 접속자수 / 구매자수 추이 + 메시지 발송 시간 표기
+ 인구통계 (Demographic)
- 전체 유저 : 성별 / 연령 분포
- 사용자 그룹별(일반 / VIP 등등) : 성별 & 연령 분포
- 사용자 속성 정보(등급 / 설문 결과 등등)
위 목록에서 필요한 항목을 골라, 1차 문제 정의를 작성하고 탐색적 리포팅을 작성한다. 이 과정에서 시간과 여유가 있다면, 탐색적 분석 과정에서 도출한 인사이트를 토대로 원인을 파악하기 위한 2차 문제 정의를 작성 할 수 있을 것이다.
3) How : 어떻게 분석할 것인가?
: 위 에서 어떤 항목을 분석할지 선택하더라도, 단일 지표만을 가지고 해당 지표를 긍정적으로 해석해야할지 부정적으로 해석해야할지 판단하기 쉽지 않다. 때문에 타겟 지표를 비교 할 수 있는 비교 집단을 함께 설계하는 것이 중요하다.
ex) 메시지 성과 분석
- 분석 집단 : 메시지 발신 후 전환율
- 비교 집단 : 메시지 발신 전 전환율
2. 데이터 수집
: 분석에 필요한 데이터를 수집하는 과정으로, 사전에 협의된 분석 기간의 데이터를 추출한다. 이 단계에서는 데이터의 수집 뿐아니라, 적합성, 커스텀 변수등을 확인한다.
(1) 데이터 퀄리티
- 데이터 누락 확인
(2) 데이터 기간
- 분석 데이터 기간 확인
(3) 분석 기준
- 사용자 기준 데이터
- 기기 기준 데이터
(4) Key, Value, Param 정의
- 매출, 카테고리 KPI 변수명 등을 사전에 정의
3. 데이터 전처리
: 수집된 데이터의 결측치, 중복값, 타입오류 등의 이슈를 사전에 체크해준다. 다만 로그데이터를 분석하는 경우, 이상치 제거는 평균의 왜곡 등을 방지하기 위해서 필요하지만, 경우에 따라서 DB값과 차이를 생성하므로, 제거 여부 논의 후 판단해야하는 상황이 생긴다. 주요 전처리 이슈들은 아래와 같다.
(1) 데이터셋 확인 단일
- 상품의 중복 카테고리 이슈 [ex. 상품 1개, 카테고리 2개]
- 데이터 타입 이슈 [ex. 금액 Value : str type으로 수집됨]
(2) 결측값 처리
- 삭제
- 대체 (평균, 최빈값, 중간값)
- 예측값 대체 (Regression, Logistic)
(3) 이상치 처리
- 단순 삭제
: 리포트 경우 삭제가 어렵기에, Scaling으로 편향된 이상치를 조정
- 평균, 중위값 등으로
(4) Feature Engineering
- Scaling
: 변수의 단위가 너무 크거나 편향 될 경우, 변수간 관계가 잘 드러나지 않기에, Log 또는 SqureRoot등을 취해 스케일 조정
- Binning
: 연령, 금액 등 연속형 변수를 범주형 변수로 변경
- Transfrom
: 자주 사용하는 예로, 단순 weekday를 주중과 주말로 변환하는 것 처럼, 분석 목표에 맞는 변수생성
4. 데이터 분석 or 모델링
: ML/DL 모델을 구축하는 과정은 이단계에서 정제된 데이터를 모델에 넣어 최적화 작업을 진행한다.
반면 리포트를 위한 분석에서는 데이터를 토대로, 인사이틀 발굴하기 위한 차이점과 원인을 찾는 실험설계의 과정이 반복된다.
1. 가설 설정
2. 실험군 비교군 설정
3. 분석 지표 생성
4. 결과 해석 리포트를 쓰다보면, 수많은 가설들을 세우고, 이에 따른 실험군과 비교군의 사용자집단들이 무수히 많아지기도 한다. 때문에 아래 2가지 모듈을 사전에 생성하고 작업한다면 비교적 정리된 상태로 분석을 진행할 수 있다.
1. Module_1 : 사용자 그룹 생성
2. Module_2 : 지표 분석
5. 데이터 분석 시각화
: 시각화는 앞선 분석항목들을 최종적인 형태로 만들어 분석 결과를 해석하거나, 또는 리포트를 받는 사람입장에서 직관적으로 결과를 인지하기 위해 필요하다.
때로는 너무 많은 변수들을 하나의 차트에 담으려고 하다보면, 시각화된 자료를 보고 해석하는데 많은 시간이 소요될 수 있으니, 시각화도 결국 어떤 분석 결과를 보여주기 위함인지 목적에 맞추어 필요한 정보만을 비교하는 것이 좋을 것 같다.
- 적절한 시각화 방법 활용
- 항목간 비교시 파이 그래프(비율)는 지양하고 막대(양) 그래프 위주
- 시계열은 라인으로(실선)
- 분포는 히스토그램이나 박스플롯
- 변수간 관계는 산점도
6. 리포팅 및 피드백 반영
: 열심히 ‘기획 정의’를 작성하고 코드를 짜며 ‘분석’을 완료하고, ‘시각화’까지 마쳤다면, 이제 자료를 리포팅 형식으로 정리고 결과를 해석하기 위한 글을 작성하는 마지막 단계가 남아있다. 여기까지 오느라 이미 많이 지쳤겠지만, 이단계가 잘 이뤄지지 않으면 그동안의 노력이 물거품이 되어버릴 수 있을 만큼 중요한 단계이다.
1) 리포팅 포맷
: 최종 리포트 작성을 위해 먼저 고민하는 것은 리포트의 포맷이다. 가장 쉽게는 ‘엑셀’ 또는 ‘PPT’가 있을 것이며, ‘GA Data Studio’, ‘Tableau’와 같은 툴을 사용하고 있다면 해당 분석툴의 기능을 사용하는 것도 좋을 것 같다.
‘Excel’과 ‘PPT’도 물론 사용자의 능력에 따라 다르겠지만, 개인적인 경험에 따르면 아래와 같은 상황에서 각각의 툴을 선택하는 것이 좋은 것 같다.
- Excel
: 탐색적 데이터 분석 과정에서 획득한 데이터들을 보며 실무진에게 리포팅하는 경우
- PPT
: 탐색적 분석을 마치고, 인사이트를 정리하여, 최종 의사결정자에게 중요한 분석 결과만 전달하는 경우
2) 리포팅 정리시 주안점
(1) 독자 중심 정리
- 상대가 이해할 수 있는 언어 사용
- 목적을 수시로 상기하고 재확인
- 분석 과정 보다는 ‘결과’중심 전달
(2) 간결 & 명확
- 짧은 문장
- Bullet point 방식
- 선 핵심내용, 후 근거
(3) 피드백 & 수정
- 피드백 후 수정 & 보완은 당연한 과정
- 분석입장에서 공을 들인 결과물도, 고객사 입장에서 중요도가 낮을 수 있음을 명시.
여기까지 분석 리포트를 작성하기 위한 각 단계별 작업들을 정리해보았다. 개인적으로 리포트라는 업무가 주어지면, 가이드라인 없이 망망대해에서 작업하던 경험이 많았기에, 그동안 작업했던 경험과 자료들을 취합하여 내가 사용하기 위한 글을 정리해보았다.
더불어 개인적으로 향상된 리포트 작성을 위해선, 복잡하고 각기 다른 형태의 산출물 데이터를 시각화 시키는 능력이 더 필요할 것 같다.
Reference
[1] 데이터 분석 절차 - @osk3856
[2] 데이터 분석을 위한 5단계 절차 - 마경근
[3] 분석 프로세스 - 위키독스
[4] 데이터 분석 계획
25 Jan 2022
[KEY WORD]
#설문조사, #확률, #통계, #신뢰구간, #표본오차
설문 표본이 실제 모집단의 특성을 왜곡하지 않고 무작위 또는 층화 표집으로 추출되었더라도, 너무 적은 표본은 편향 및 오차를 포함할 수 있다.
따라서 통상 95% 신뢰수준하에서, 표본의 크기에 따른 표본 오차가 얼마나 발생하는지 측정하여야 설문 결과로 얻은 값이 우연의 일치인지, 아니면 통계적으로 유의미한 차이인지 확인할 수 있다.
1. 일반 관점, 신뢰수준과 표본오차
: 아래와 같은 여론조사가 있다고 할때, ‘신뢰수준’과 ‘표본오차’는 무엇일까.
1000명을 대상으로 조사한 결과, 38%는 A후보, 26%는 B후보, 24%는 C후보를 지지한다고 응답하였다. (95% 신뢰수준에 표본오차 ±3%)
1) 신뢰수준 95%
: 동일 조사 100번 수행시, 오차범위내 동일한 결과가 나올 횟수가 95번.
2) 표본오차 (신뢰수준 95%일 때)
: 동일 조사 100번 수행시, 95번은 오차가 ±3% 포인트 안에 있음.
- (1) 모집단 또는 표본의 표준편차를 알 때 : $\epsilon$ = $z \times \sqrt{\sigma^2\over n}$
- (2) 모집단 또는 표본의 표준편차를 모를 때 : $\epsilon$ = $z \times \sqrt{p(1-p)\over n}$
- (3) 모집단 또는 표본의 표준편차를 모르며, 모집단이 충분히 크지 않을 경우 : $\epsilon$ = $z \times \sqrt{p(1-p)(N-n)\over n((N-1))}$
- p : 특정 결과 발생 확률 (0.5가 가장 불확실성이 높기에, 표본 오차를 극대화 하기 위해선 0.5로 통상 설정)
- n : 표본 크기(Sample Size)
- N : 모집단(Population)
3) 해석
- A후보는 B,C 오차범위 밖에서 큰 차이로 앞선다.
→ 95% 신뢰수준으로, A가 B,C보다 높다고 할 수 있다.
- B와 C 후보는 오차범위 내에 있다.
→ 95% 신뢰수준으로, B가 C보다 높다고 할 수 없다.
2. 통계 관점, 신뢰수준과 표본오차
- https://kuduz.tistory.com/1220 게시글 ‘오차범위(표본오차)란 무엇인가를 공부한 글입니다.’
1) 이항분포 (동전던지기)
(1) 2회 시행시, 앞면(H)이 N번 나올 확률 분포
- H, 0회 확률 : 1/4 [T,T]
- H, 1회 확률 : 2/4 [T,H], [H,T]
- H, 2회 확률 : 1/4 [H,H]
(2) 3회 시행시, 앞면(H)이 N번 나올 확률 분포
- H, 0회 확률 : 1/8 [T,T,T]
- H, 1회 확률 : 3/8 [T,T,H], [T,H,T], [H,T,T]
- H, 2회 확률 : 3/8 [T,H,H], [H,T,H], [H,H,T]
- H, 3회 확률 : 1/8 [H,H,H]
(3) 100회 시행시, 앞면(H)이 N번 나올 확률 분포
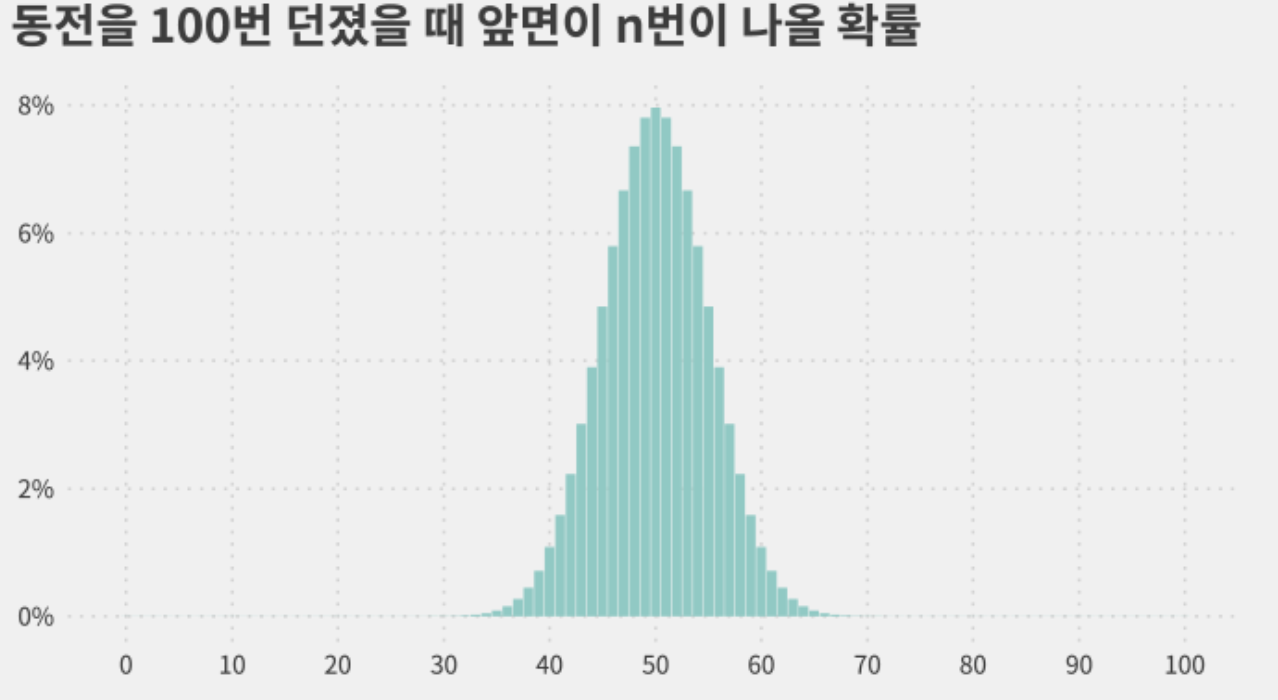
- 100번 던질 때, 앞면이 49~51회 나올 확률 : 23.6% (7.8% + 8% + 7.8%)
- 100번 던질 때, 앞면이 40~60회 나올 확률 : 95.4%
무려 95%의 확률이 가운데 20회의 경우에 발생한다…!?!? 정규분포의 형태를 띄어감!
"이항분포의 정규근사"
시행 횟수가 많을수록 그리고 확률이 1/2에 가까울 수록,
이항분포는 정규분포에 가까워진다.
2) 정규분포
: 앞서 동전던지기를 통해, 이항분포가 정규분포를 띄고 있음을 보았다. 따라서 정규분포의 특징을 정리하면 아래와 같다.
- 평균이 가장 볼록하고, 평균에서 멀어질 수록 높이가 낮아지는 분포
- 평균($\mu$) & 표준편차($\sigma$)에 따라 모양이 변함
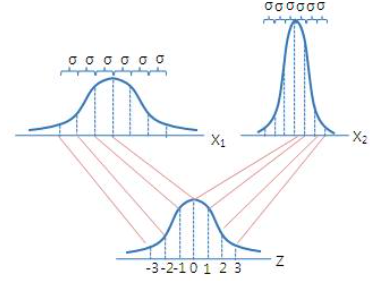
3) “표준”정규분포
: 위 정규분포는 평균과 표준편차에 따라서, 모두 모양이 제각각이다보니, 특정 확률(ex.95%)를 규정하려면 정규분포마다 서로 다른 표준편차값이 설정될 것이다.
→ 때문에 정규분포에서 평균을 빼고, 표준편차로 나눠 ($Z$ = $(X - \mu)\over\sigma$) 평균이 0이고, 표준편차가 1인 ‘표준’정규분포로 변환하여 규격화해보자.
- 평균($\mu$) : 0
- 표준편차($\sigma$) : 1
4) 신뢰구간(confidence_interval)
: 이렇게 ‘표준정규분포’를 얻었고, 우리는 대략 2표준편차, 정확히는 $\pm$1.96$\sigma$ 안에 전체 사례의 95%가 포함됨을 앞서 동전사례를 통해 알고 있습니다.
따라서 95% 신뢰구간이라하면 +1.96$\sigma$ ~ +1.96$\sigma$로 표현 하며, 오차범위 & 표본오차라고도 부릅니다.
5) 신뢰수준(confidence_level)
: 그렇다면 ‘신뢰수준’의 의미는 무엇일까.
- 평균이 0, 표준편차가 1인 (표준)정규분포를 따르는 모집단이 있을 때,
- 샘플(표본) 50개를 뽑고, 이 샘플의 평균과 표준편차를 계산하면,
- 각 샘플의 신뢰구간 100개 가운데, 95개(95%)는 샘플의 신뢰구간안에 모집단의 평균(0)이 위치할 것이라는 것.(물론 정확히 95%는 아니겠지만 95%에 수렴)
- 즉, 신뢰수준 95%는 100번 조사했을 때, 95번은 모집단의 값을 예측할 수 있지만, 5번 정도는 틀릴 수 있다는 뜻이 됩니다.
6) 샘플(표본)로 모집단 유추하기
: 앞서 신뢰수준을 이야기할 때, 우리는 모집단의 평균(모평균)이 0이라고 가정했기에, 표본 95개의 신뢰구간안에 모평균이 위치함을 알 수 있었습니다. 그러나 현실 및 여론조사에서 모집단의 평균을 알 수 없습니다. 이럴 때는 어떻게 신뢰수준 95%를 확인 할 수 있을까요.
샘플을 활용하여, 모집단의 평균을 추정할 수 있는지 확인해 봅시다.
(a) 모집단
- 모집단 : [1,2,3]
- 모평균($\mu$) : 2
- 모분산($\sigma^2$) : $2\over3$ = ( $(1-2)^2 + (2-2)^2 + (3-2)^2)\over3$ )
- 모표준편차($\sigma$) : $\sqrt{2\over3}$
(b) 표본
: 2개의 샘플을 추출(반복추출 허용)할 때 모든 경우의 수는 아래 테이블과 같음.
| 표집 |
표본 평균 |
오차(표본평균 - 모평균) |
오차 제곱 |
| [1,1] |
1 |
1 |
1 |
| [1,2] |
1.5 |
0.5 |
0.25 |
| [1,3] |
2 |
0 |
0 |
| [2,1] |
1.5 |
0.5 |
0.25 |
| [2,2] |
2 |
0 |
0 |
| [2,3] |
2.5 |
-0.5 |
0.25 |
| [3,1] |
2 |
0 |
0 |
| [3,2] |
2.5 |
-0.5 |
0.25 |
| [3,3] |
3 |
-1 |
1 |
| 평균 |
2 |
0 |
$1\over3$ |
- 표본 평균의 평균($\bar{X}$) : 2
- 표본 분산($S^2$) : $1\over3$
- 표본 표준편차 -> 표준오차($S$) : $\sqrt{1\over3}$
(c) 표본평균과 모집단의 관계
: 우리는 표본평균으로부터 위와 같은 통계치들을 얻을 때, 아래와 같은 사실을 확인 할 수 있습니다.
- 표본평균의 평균은 모평균과 같다. → [$\bar{x} = \mu$]
- 표본평균의 오차 제곱의 평균 즉 분산은, 모분산을 표본의 크기로 나눈값과 같다. → [$S^2$ = $\sigma^2\over n$]
- 표본평균의 표준편차(= 표준오차) → [$S$ = $\sqrt{\sigma^2\over n}$]
"이는 즉 표본의 평균과 분산을 알면,
모집단의 평균과 분산도 알 수 있다는 이야기!"
(d) 모분산을 모른다면?
특정 관측치가 나타날 확률을 p라고 할 때,
기댓값($E(X)$) = 관측값 x 발생확률 = “n X p”라고 표현 할 수 있습니다.
그렇다면 다시 동전으로 돌아가
앞면에 1, 뒷면을 0에 값으로 부여 할때, 각면의 발생 확률(p) = $1\over2$입니다.
1) 따라서 기댓값은 아래와 같이 쓸 수 있고,
기댓값($E(X)$) = $1\over2$ = 0 $\times$ $1\over2$ + 1 $\times$ $1\over2$
2) 분산은 편차의 제곱에 평균이기에, 편차의 제곱값에 각 편차의 발생확률을 곱해준것과 같습니다.
분산($\sigma^2$) = $\left( 0 - \frac{1}{2} \right)^2 \times \frac{1}{2}$ + $\left( 1 - \frac{1}{2} \right)^2 \times \left(1 - \frac{1}{2}\right)$
3) 위 식을 일반화 시키면 아래와 같습니다.
$\begin{matrix}
\sigma^2 &=& (1-p)^2 \times p + (0-p)^2 \times (1-p) \\
&=& p(1-p)
\end{matrix}$
4) 앞서 표본의 표준편차(표준오차)($S$)은 아래 공식과 같았습니다.
$S$ = $\sqrt{\sigma^2\over n}$
5) 위 표준오차의 분산($\sigma^2$)자리에, 위에서 찾은 발생확률 p로 계산한 분산을 대입하면 아래와 같습니다.
$S$ = $\sqrt{p(1-p)\over n}$
6) 자 이제, 모집단의 분산을 모르더라도 표준오차를 계산할 수 있게되었습니다.
1표준오차가 위 공식과 같을 때, 우리는 앞서 95% 신뢰수준하에서 표준오차의 범위(오차범위[$\epsilon$])를 알고 싶습니다.
양측으로 2표준편차(정확히 1.96표준편차)에서 95%의 값을 포함하고 있기에, 표준오차 공식에 1.96이라는 z-score를 곱해줍니다.
(2표준편차라고 이야기할 때 ‘2’가 z-score이며, 95%는 1.96이됩니다.)
$\epsilon$ = $z \times \sqrt{p(1-p)\over n}$
7) 표준오차를 활용하여, 실제 통계치 비교하기
: 이제 설문조사 결과를, 표준오차를 활용한 신뢰구간의 범위로 확장하여 다시 살펴보겠습니다.
- 표본 오차 3.1%포인트일때, 긍정평가 49%의 신뢰구간 = 45.9% ~ 52.1%
- 표본 오차 3.1%포인트일때, 부정평가 45%의 신뢰구간 = 41.9% ~ 48.1%
$\therefore$ 두 응답의 오차범위가 서로 중첩되기에, 긍정평가가 더 높다는 설문결과는 95%신뢰수준을 만족하지 못하고 결과가 뒤집힐 수 있습니다.
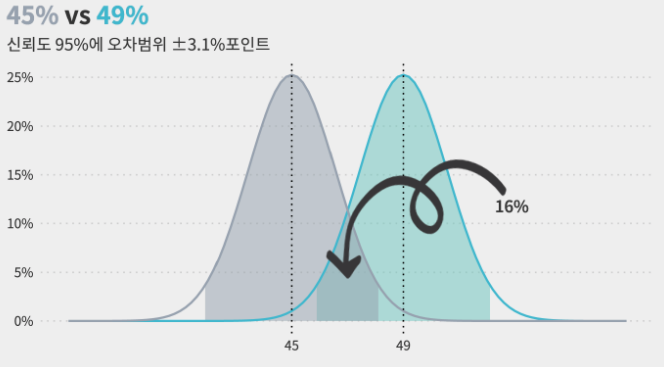
- 표본 오차 3.1%포인트일때, 긍정평가 49%의 신뢰구간 = 45.9% ~ 52.1%
- 표본 오차 3.1%포인트일때, 부정평가 41%의 신뢰구간 = 37.9% ~ 44.1%
$\therefore$ 두 응답의 오차범위가 서로 벗어나 있기에, 긍정평가가 더 높다는 설문결과는 신뢰도 95% 기준으로 차이가 있다고 할 수 있습니다.
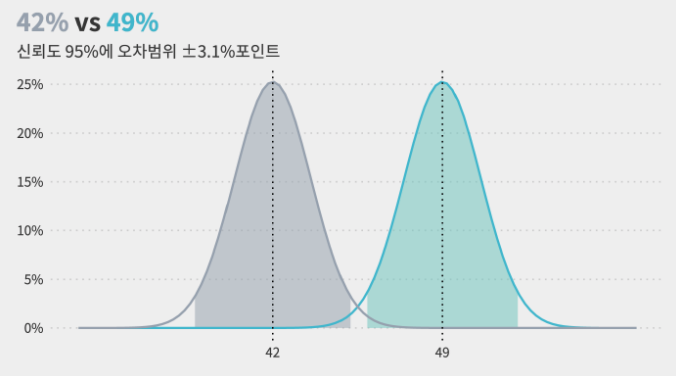 "표본오차보다 작은 변동에 대한 의미 부여는,
"표본오차보다 작은 변동에 대한 의미 부여는,
해설이 아니라 소설이다."
Reference
[1] 오차범위(표본오차)란 무엇인가?
[2] 표준오차, 표본오차, 오차한계 개념 구분
[3] Standard Normal Distribution, Standard Gaussian Distribution
25 Jan 2022
[KEY WORD]
#설문조사, #확률, #통계, #확률적 표본 추출
설문데이터 활용에 앞서서, 해당 설문 자체가 얼만큼 모집단을 대표할 수 있는가를 알기 위해서는 설문 대상이 “확률적 표본 추출”을 따랐는지 확인해보아야한다.
이에 “확률적 표본 추출”이 구체적으로 무엇을 뜻하는지 살펴보자.
확률적 표본추출
: 큰 모집단으로부터 작은 샘플그룹을 랜덤하게 선택하는 통계 방법으로, 샘플의 응답이 모집단의 경향성을 대표. 이때 모집단을 대표하기 위해서는 2가지 중요한 조건이 필요.
1) Non-Zero chance of being selected
: 모든 모집단의 유저가 뽑힐 확률이 있어야 함 (체계적으로 설문을 수행할 수 없는 사용자가 존재해서는 안됨)
- ex) 특정 언어로만 작성되어, 이외 언어사용자는 설문참여가 불가능한 경우
- ex) 설문 진행 시점이, 특정 행동 수행 이후로 한정됨(의도적으로 특정 유저만을 설문하는 경우라면 가능)
2) Know the chance of being selected for each person
: 구체적으로 뽑힐 확률이 각자에게 얼마나 되는지 알아야함. 이때 모집단의 특성을 반영하기 위해 적절한 전략을 선택.
(1) 단순 무작위 표집 (Simple random sampling)
: 추출은 무작위로 진행되며, 모든 유저가 동일한 추출확률을 갖음.
- 장점 : 쉬움.
- 단점 : 표본이 모집단에 비해 작을 시, bias가 발생할 확률이 높아져 신뢰도가 낮아짐.
(2) 층화 표집 (Stratified sampling)
: 모집단을 서로 배타적이며, 모두 합쳤때 전체가 되는 집단으로 나누고, 각 집단별로 추출될 확률을 서로 다르게 부여함. (ex. by gender, age, ethnicity, etc)
- 장점 : 모든 층화에서 설계된 확률만큼 무작위로 표본추출된다면, 모집단을 대표할 수 있음
(3) Cluster sampling
: 서로다른 클러스터(ex. 지역)을 임의로 선택한 다음, 선택한 클러스터의 일부 또는 모든 구성원을 조사함
Reference
[1] 확률적표본추출
15 Dec 2021
#linux, #crontab, #bash, #shell
1. 문제 상황
: crontab을 사용하여 자동 예약을 걸어놓았는데, 위와 같은 에러가 발생함.
/bin/sh: 1: [[: not found
2. 문제 원인
- 조건문
[[]] 는 bash 에서 사용하는 문법이나, 내가 crontab을 설정한 shell은 bash가 아닌, sh이었음.
- error 발생시 날아온 메일을 확인해보면
SHELL=/bin/sh SHELL이 sh로 설정되어있음을 알 수 있음. (메일 위치 : /var/mail)
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
X-Cron-Env: <SHELL=/bin/sh>
X-Cron-Env: <HOME=/srv/dlab>
X-Cron-Env: <PATH=/usr/bin:/bin>
X-Cron-Env: <LOGNAME=dlab>
Message-Id: <20211215033701.8B348A60019@localhost>
Date: Wed, 15 Dec 2021 12:37:01 +0900 (KST)
/bin/sh: 1: [[: not found
3. 해결
- 스택 오버플로우에서 제시한 방법(Add #!/bin/bash at the top of file)이 작동하지 않았음.
- 스크립트 상단에 SHELL 옵션을
/bin/bash로 설정함.
(서버개발자분께 문의드림..)
SHELL=/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
- 고의로 에러를 발생시킨 다음 crontab에서 날아온 메일에 SHELL 옵션이 bin/bash로 바뀌어있는 것을 확인 할 수 있음.
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
X-Cron-Env: <SHELL=/bin/bash>
X-Cron-Env: <PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin>
X-Cron-Env: <HOME=/srv/dlab>
X-Cron-Env: <LOGNAME=dlab>
Reference
[1] 에러 문제 확인한 스택오버플로우
12 Dec 2021
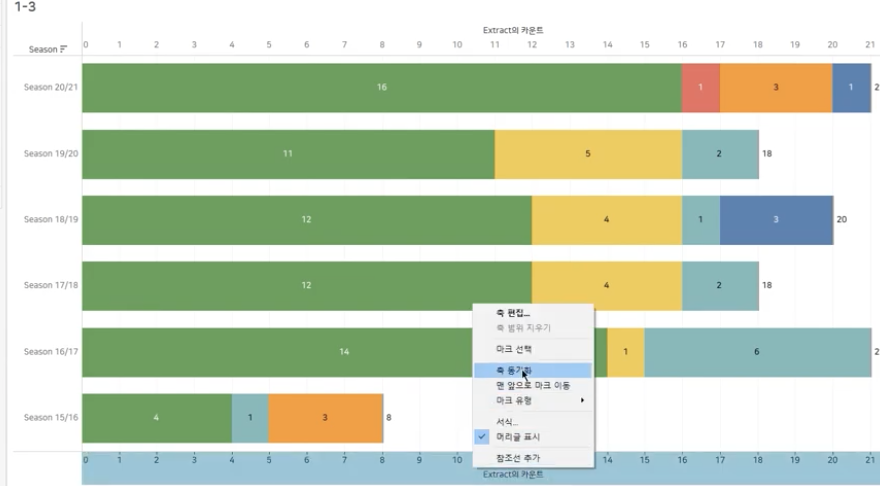
Tableau
#막대차트, #간트차트, #이중축
목표
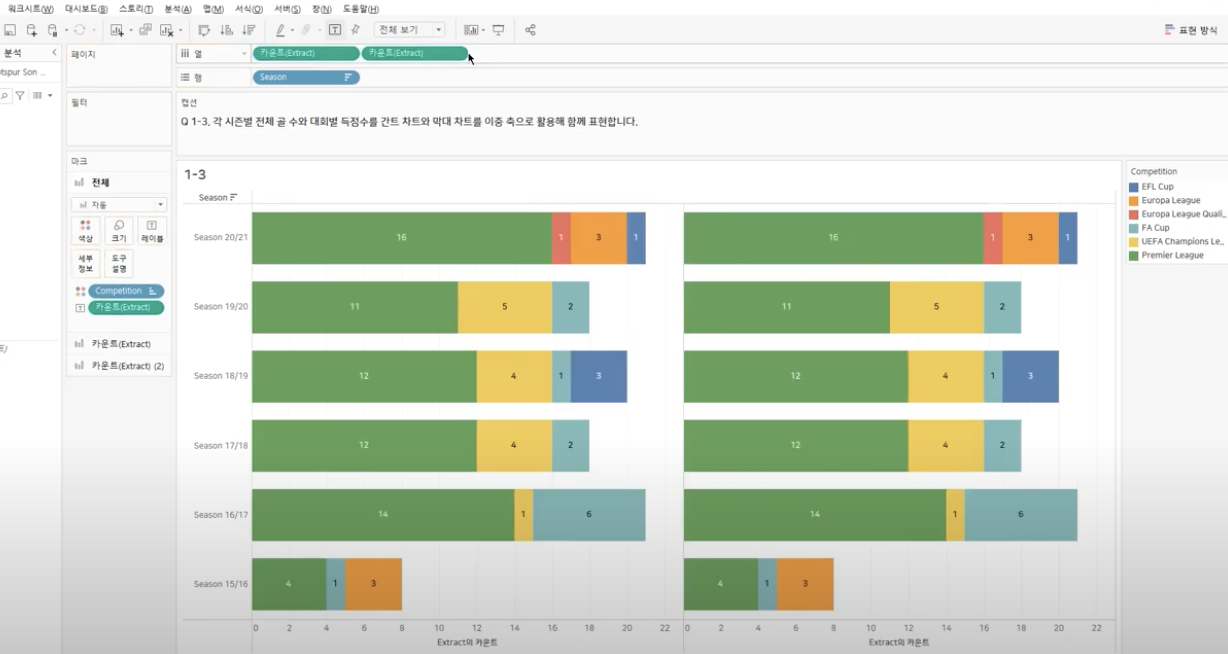
: 개별 bar plot에 레이블을 다는 것은 어렵지 않으나, 아래와 같이 개별 컬럼에 2가지 형태의 서로 다른 레이블을 다는 경우, 간트차트와 이중축을 사용해볼 수 있다.
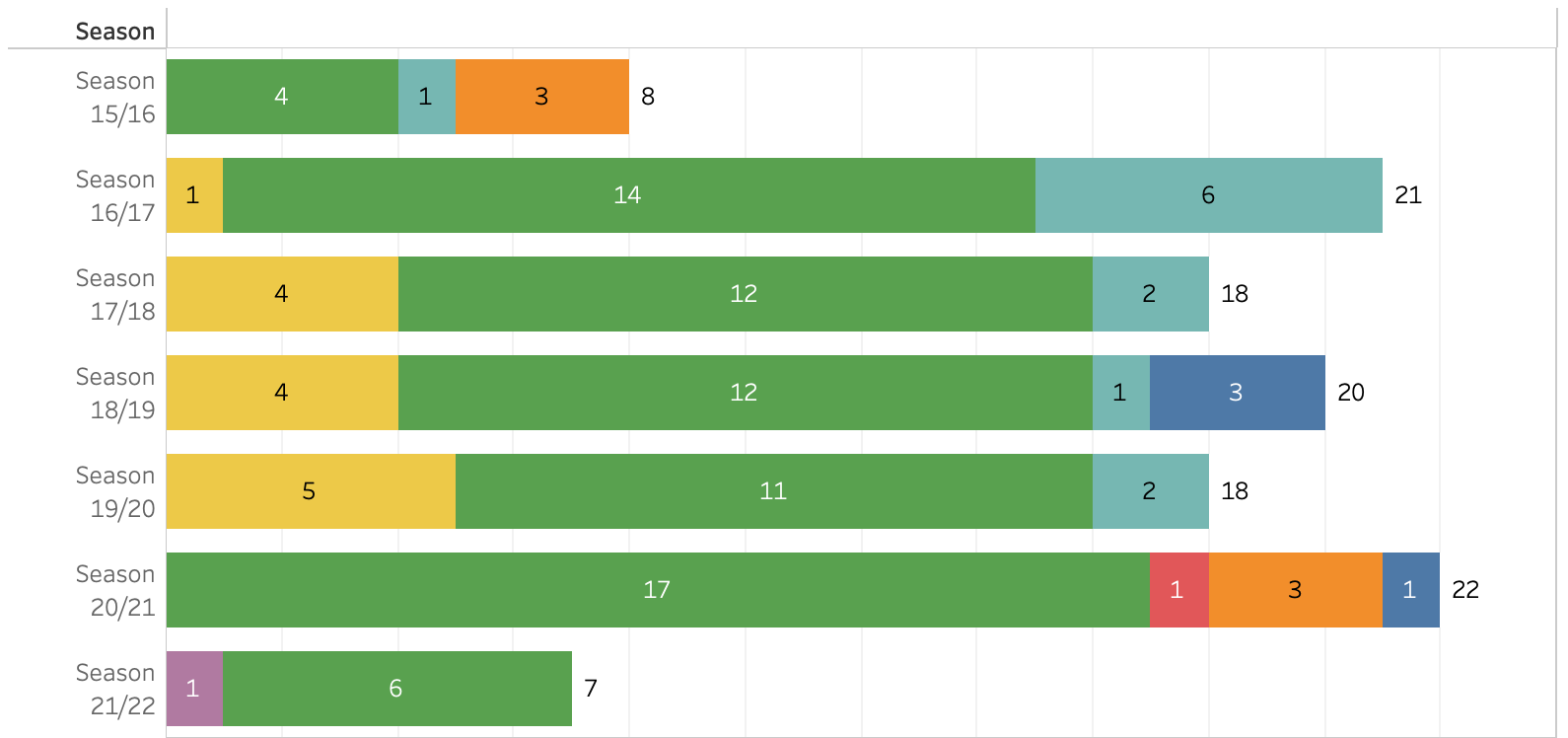
단계별 과정
Step_1
: 2개 이상의 필드 추가(시즌별 & 리그별)
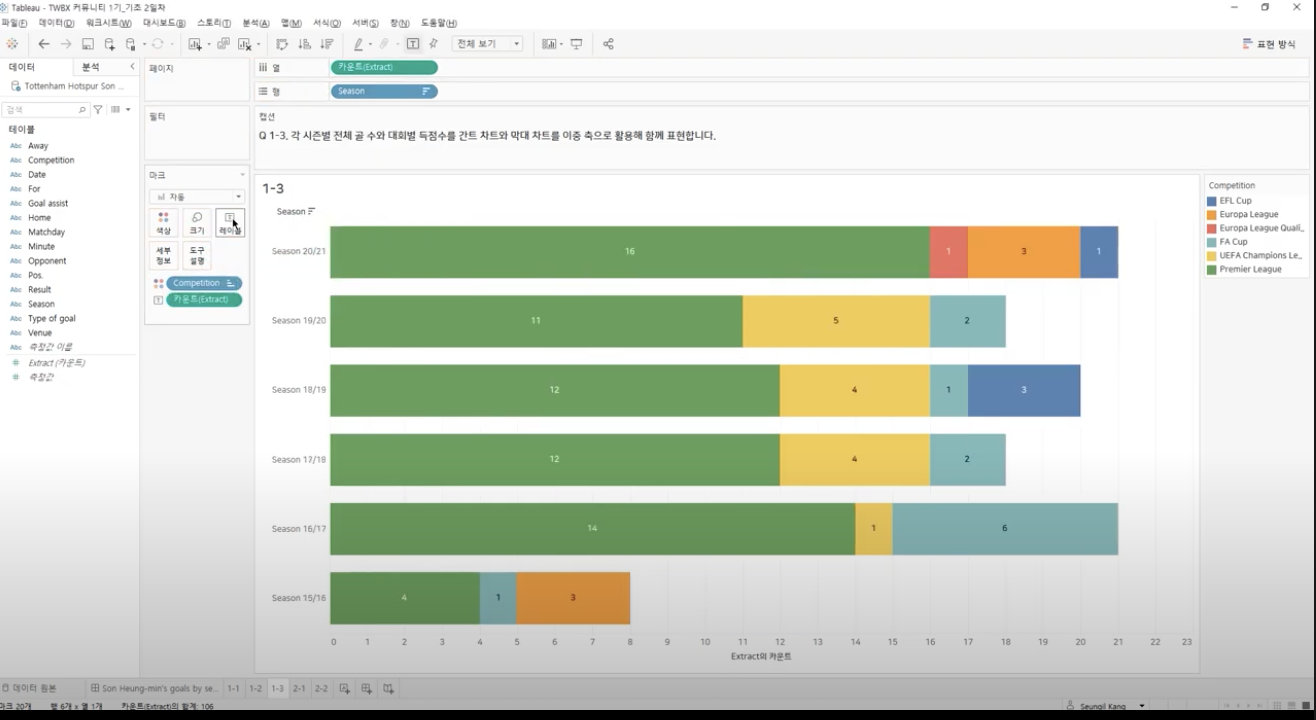
Step_2 : 개별 그래프 & 통합 그래프 만들기
: 열 선반에 있는 카운트를 하나 더 추가 후, 해당 그래프에서 색상에 들어있는 필터를 삭제하고 간트 차트로 변경
Step_3 : 2개 그래프 합치기
: 우측 그래프기준 ‘이중 축’선택, 이때 기존 그래프까지 간트차트로 바뀌기에 기존 차트는 다시 Bar그래프로 변경
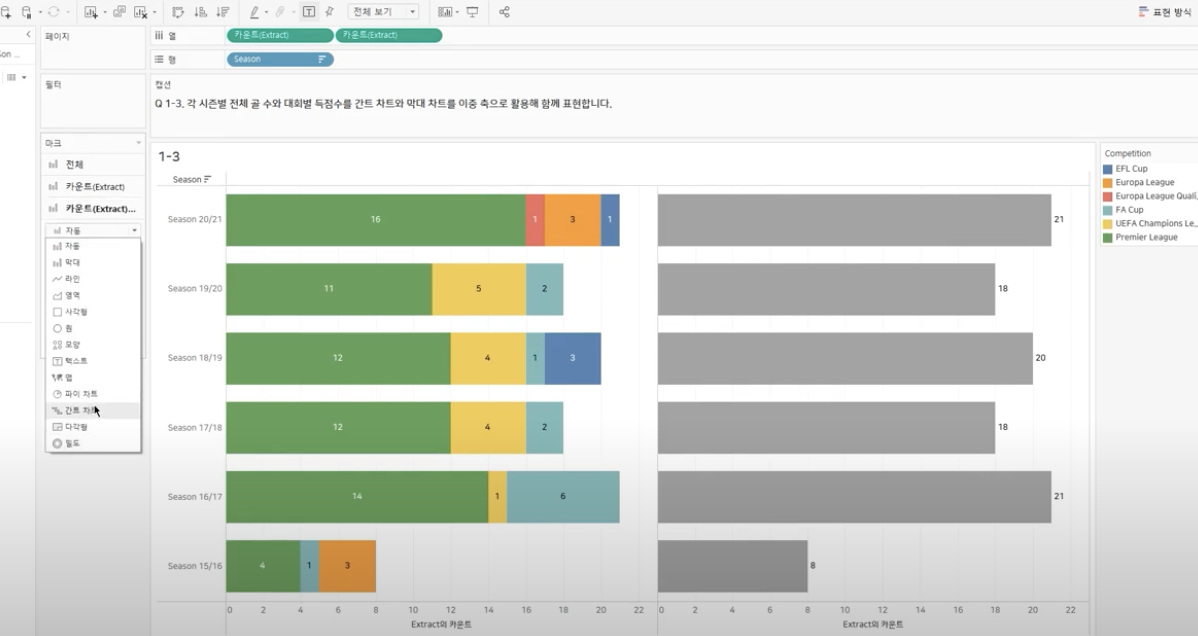
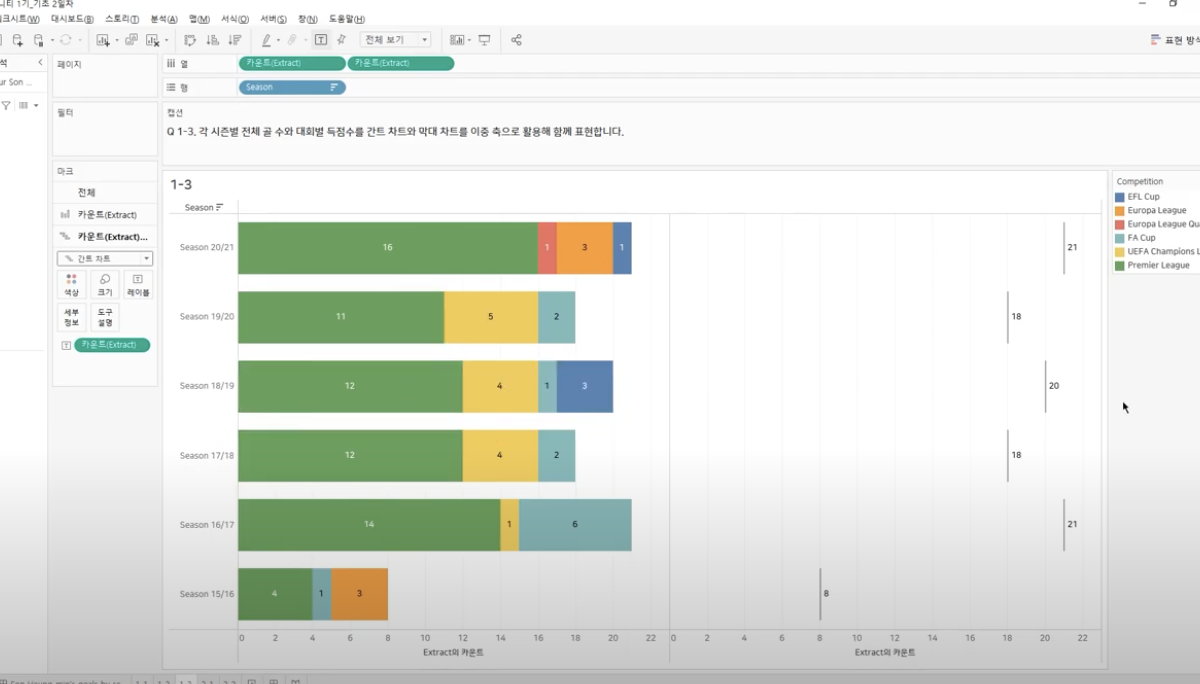
Step_4 : 축 동기화
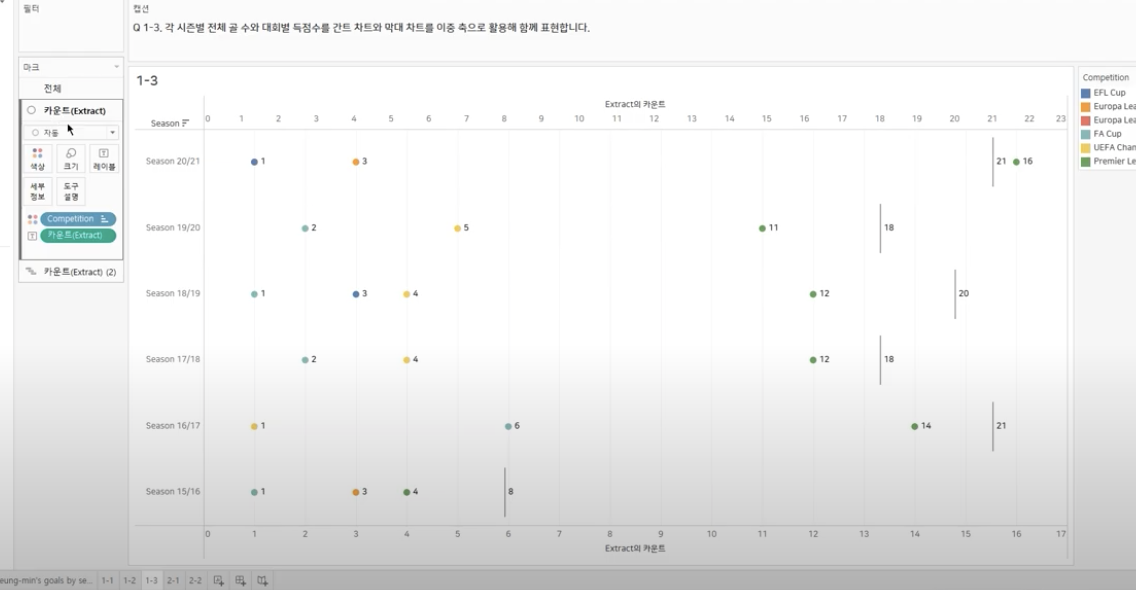
: 하단 -> 마우스 오른쪽 -> “축 동기화” 클릭

Reference
[1] 테블루 손흥민 시즌별 대회별 득점수 시각화 #막대차트 #간트차트 #이중축