(Prep) Standardize vs Normalize vs Regularize
30 Nov 2020 Preprocess: 데이터 전처리 단계에서 변수별 스케일이 서로 다르기에 이를 조정하기 위한 sclaling과정을 자주 거치게 된다. 위 3가지 방법은 데이터를 학습이 용이한 형태로 변형한다는 유사점을 갖고 있지만, 각 방법마다 상황에 맞게 사용하기 위해서 차이점을 구분해보자.
1. Rescale
1) Normalization
(1) min-max Normalization[0~1]
- - 목표 : 데이터의 상대적 크기에 대한 영향력을 줄이기
- Normalization은 변수의 스케일(scaling)을 [0,1]로 재조정한다.
- 특히 변수 1개 보다, 여러개의 변수가 서로 비교되어야 할 때, 특정 변수의 단위가 너무 커 상대적 영향력이 과대 평가되는 것을 방지하기 위해 사용됨.
- 단, 각 변수내에 이상치가 없다는 가정하에 사용하는 것이 적절하다.
from sklearn.preprocessing import MinMaxScaler
scaler = MInMaxScaler()
df[:] = scaler.fit_transform(df[:])
df[:] = scaler.fit_transform(df['col_1']) # 하나의 열에 한하여 Normalization을 진행하고 싶은 경우,
(2) Mean Normalization[-1~1]
- - 목표 : 데이터가 평균보다 큰지 작은지 표현(이상치에 영향을 받을 가능성 존재)
- 영화 선호 평가(rating)처럼 데이터의 값이 {1,2,3,4,5}와 같은 경우, 평균값을 기점으로 평균이하에는 음의 수치를, 이상에는 양의 수치를 주고 적용하고 싶은 경우 Mean Normalization이 더 적절하다.
2) Standardization(표준화)
- - 목표 : 데이터가 평균으로부터 떨어진 정도를 표현
- Standardization(표준화)는 ‘전처리’ 단계에서 변수의 평균을 0으로 조정하고 개별 단위 분산으로 값을 재조정(scaling)하기 위해 자주 사용된다. 표준화를 거쳐 +/-1.96(또는2)를 넘는 데이터 제거할 수 있음.
from scipy import stats
df['col_std'] = stats.zscore(df['col_raw'])
df = df[df['col_std'].between(-2,2)] # outlier detection
+ 위 방법들은 독립적이지 않고, 아래와 같이 두 방법을 모두 거쳐 사용하기도 한다.
- (1) Standardization(표준화)으로 outlier 제거하기
- (2) Normalization(정규화)으로 scale의 상대적 크기 영향력을 줄여 분석에 투입
2. Regularization
: 위에서 언급한 Normalization & Standardization은 스케일링의 개념만을 갖고 있다면, Regularization은 ‘Overfitting’의 문제를 해결하기 위해 등장한다. 모델에 추가적인 loss Function(손실 함수)을 추가함으로써, 모델의 파라미터가 더 작은 값으로 수렴하게 되어(중요하지 않은 변수의 영향력 축소) 과적합을 현저하게 낮추는 효과를 갖는다.
import numpy as np
from sklearn import preprocessing
X = np.asarray([
[-1,0,1],
[0,1,2]],
dtype=np.float) # Float is needed.
# Before-normalization.
print(X)
# Output,
# [[-1. 0. 1.]
# [ 0. 1. 2.]]
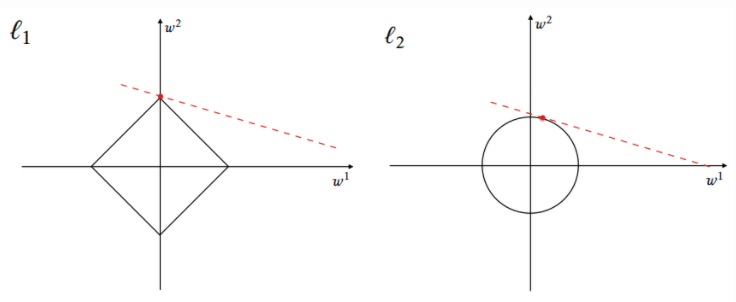
1) L1-Norm : Lasso
- 목표 : 절대값 함수는 0에서 미분이 불가하기에, Sparse한 모델을 트레이닝할때, 불필요한 변수의 파라미터를 완전히 0으로 만들 수 있어 차원을 줄이는데 유용합니다.
X_normalized_l1 = preprocessing.normalize(X, norm='l1')
print(X_normalized_l1)
# [[-0.5 0. 0.5]
# [ 0. 0.3 0.67]]
# Absolute value of all elements/features.
X_abs = np.abs(X_normalized_l1)
print(X_abs)
# [[0.5 0. 0.5]
# [0 0.3 0.67]]
# Sum over the rows.
X_sum_abs = np.sum(X_abs, axis=1)
print(X_sum_abs)
# Output,
# [ 1. 1.]
# Yay! Each row sums to 1 after being normalized.
- 목표 : 반면 L2는 변수의 파라미터를 완전히 0으로 만들지 않기에, 주어진 조건이 명확하지 않거나 부족한 ill-posed problem에서 더 자주 선호됩니다.
# l2-normalize the samples (rows).
X_normalized = preprocessing.normalize(X, norm='l2')
# After normalization.
print(X_normalized)
# Output,
# [[-0.70710678 0. 0.70710678]
# [ 0. 0.4472136 0.89442719]]
# Square all the elements/features.
X_squared = X_normalized ** 2
print(X_squared)
# Output,
# [[ 0.5 0. 0.5]
# [ 0. 0.2 0.8]]
# Sum over the rows.
X_sum_squared = np.sum(X_squared, axis=1)
print(X_sum_squared)
# Output,
# [ 1. 1.]
# Yay! Each row sums to 1 after being normalized.
Reference
[1] Differences between Normalization, Standardization and Regularization [2] 데이터 표준화(Standardization), 정규화(Normalization) 차이점