02 Sep 2021
#git, #gitlab, #github, #branch
github(or gitlab)을 사용하여, 프로젝트를 시작할때 절차별 사항들을 정리해보자.
1. git 서버에 프로젝트 생성하기
: git 프로젝트 생성방법은 아래 링크에 소개되어있는 절차대로 진행하면 쉽게 생성할 수 있다.(간단하기에 링크없이도 진행할 수 있다)
2. git config
git에 생성한 repository를 다운받기 전,
실행하고자 하는 local pc에 내가 어떤 git 계정인지 세팅해주어야 한다.
(git 계정이 private인 경우, 서버에도 해당 계정을 초대/등록해주어야 함.)
# 1) git global config 정보 확인
git config --list
# 2) git global user.name & email 세팅
git config --global user.name "git 회원가입 시 입력한 이름"
git config --global user.email "git 회원가입 이메일 주소"
3. 로컬 pc에 git서버 clone
내가 누구인지 설정해주었다면, remote서버내 저장되어 있는 repository를 복사해오자.
$ git clone "git 주소" # 이때 git 주소는 repository에서 copy.
4. 프로젝트 관리하기(매번 할 작업)
## 0) pull : remote 서버내 변경 사항 불러오기
$ git pull
## 1) add : 변경 내역 알리기
$ git add test.py # 특정 파일만 알림
$ git add . # 모든 변경 내역 알림
## 2) commit : 로컬 저장소에 변경 내역을 저장
$ git commit -m "이 버전의 변경 내역에 대한 설명"
$ git commit -am "이 버전의 변경 내역에 대한 설명" # add + commit
## 3) push : remote 서버에 변경 내역 올리기
$ git push -u origin master
$ git push # -u 옵션을 이용하면 다음 push때 이전 히스토리를 기억하고 반영
5. Branch 전략
Refernce : git branch & commend
Git 작업시 주요 브랜치는 master(main)와 develop 이며, 이외에도 기능별 브랜치가 존재하지만 지금 나는 이 두개도 벅차다..ㅎ
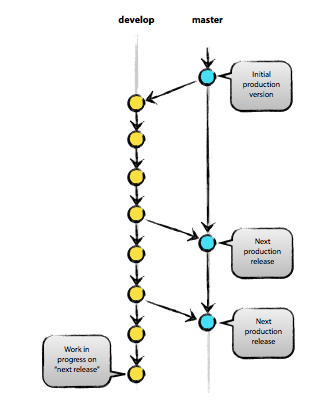
작업 순서는 아래와 같이 생각하면 된다.
@ [작업 시작]
git checkout dev : git master branch –> dev branch 변경
(HEAD가 dev 브랜치를 바라보며 변경사항을 저장)- [branch : dev] 파일 생성 및 분석 작업 진행
- [branch : dev]
add, commit, push
@ [dev에서 작업이 끝나고 “배포할” 코드를 master로 merge할 경우]
git checkout master git dev branch –> master branch 변경
(HEAD가 master 브랜치를 바라보며 변경사항을 저장)- [branch : master]
git merge "dev" : dev branch를 merge
- [branch : master]
gut push : 최종 배포할(merge된) 코드를 git에 업로드
+ branch 주요 commend
## 1) branch 생성 : master branch에서 develop 이라는 새로운 branch를 만들고 갈아탄다.
$ git checkout -b dev
## 2) branch 확인 및 변경 (서버에서 만든 branch가 보이지 않을 땐, pull로 업데이트)
$ git branch # local
$ git branch -r # remote 저장소의 branch 확인
$ git branch -a # local & remote branch 모두 확인
$ git checkout "dev" # master branch로 이동
## 3) 특정 branch(dev)에 push
$ git push # 이미 dev branch에 있다면, 그냥 Push 해도됨.
$ git push -u origin dev # main에 있다면, push할 branch를 명시해줌.
## 4) master branch에 merge
$ git checkout master # master branch로 이동
$ git merge "dev" # merge 하고자 하는 branch명을 써주면 master로 merge 끝!
Git Branch 이름 변경하기
## 1) [local] branch 이름 변경
$ git branch -m old_branch_name new_branch_name
## 2) [remote] branch 이름 변경
git push origin :old_branch_name
## 3) 변경한 새로운 브런치를 업로드
git push --set-upstream origin new_branch
Reference
[1] git lab 프로젝트 생성하기
[2] git branch & commend
[3] branch Merge하기
[4] Git Branch 이름 변경하기
25 Aug 2021
#하용호, #데이터
데이터로 세상을 해석하기
비즈니스 성장은
- 결과 측정 가능
- 상황의 제어를 내가 가능하게 하는 것
-
- 반복 수행이 가능 할 것
- 위 과정을 가능하게 하는 것 “피드백 루프(feedback loop)”

회사에 데이터 적용하기
과거 확인 -> 현재 개선 -> 미래 예측
1. 과거 확인
- 과거분석 : 지난 매출 / 기존 출시 제품 / 고객 분석
+ problem
: 대부분의 사람들은 현재를 분석하거나, 미래를 예측하는 펜시한 기술에 집중하지만, 대부분의 회사는 과거를 제대로 보는 일조차 하지 않음.
+ 데이터 축적 방식
- 모든 데이터를 다 축적하려는 기업이 많음. 그러나, 완벽한 모든 데이터 구축은 오랜 시간이 걸리며, 불가능함.
- So 해결하고자 하는 주제를 명확히 정하고 이에 필요한 데이터를 모으는 것이 중요

2. 현재 개선
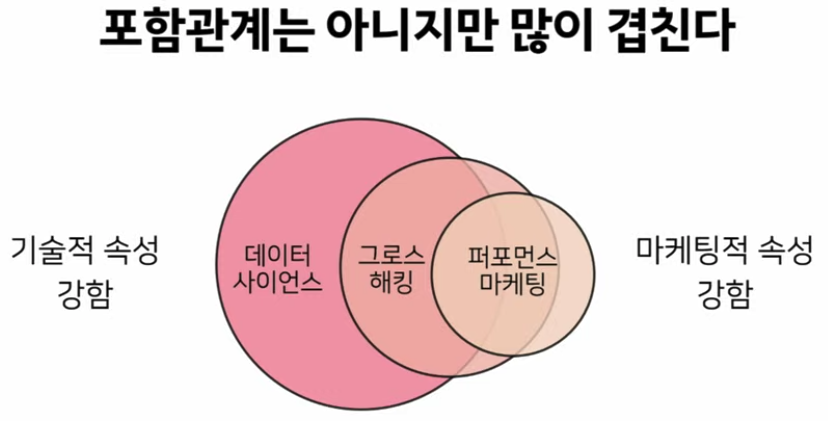
- 현재 개선 : 성장 / 광고 효율 / 유저 획득에 관련된 업무
- 그로스 해킹 & 퍼포먼스 마케팅
-
- problem 회사에서 문제를 정의하는 방식
- “매출을 올리자 or 비용을 줄이자” 식의 포괄적인 문제정의
2-1) OMTM(One Metric That Matters)
- 모두가 집중해야할 하나의 목표(중단기적)를 잡고 문제를 해결해 나갈 것
- 갱신 주기가 빠를 것
- 후행지표가 아닌, 선행지표에 해당하는 KPI를 설정할 것
+ OMTM을 찾는 기술적 방법



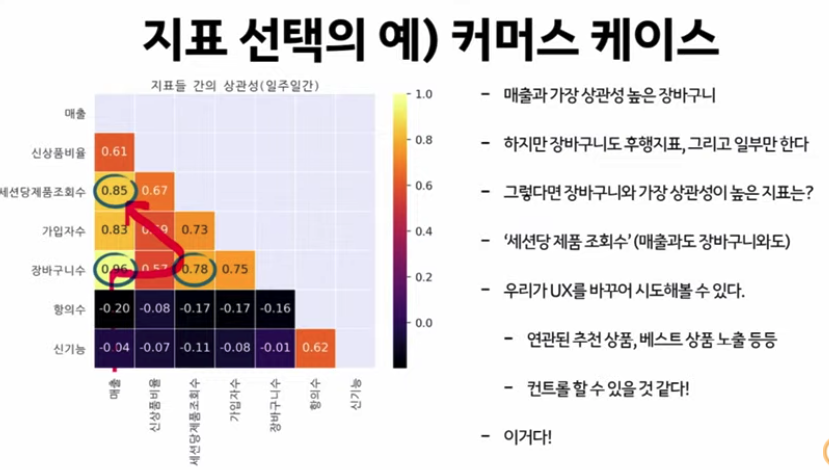
2-2) A|B test
: OMTM을 통해 지표 및 메트릭을 잡았다면, 개선 활동은 어떻게 해야하는가
+ A|B TEST를 위해 확보되어야 할 3가지
- 데이터 : 우리만 가지고 있는 배타적 데이터(ex. 고객 로그 데이터)
- 채널 : 고객에게 가치를 전달할 수단(ex. push 메세지, 광고 배너 등)
- 선택지 : 유저에게 오퍼할 선택의 충분한 양과 질(ex. 상품, 고객 대상, 컨텐츠)

3. 미래 예측

현실

해결책


정리

22 Aug 2021
#git, #생활코딩, #본질
1. git 설치
git 설치사이트 : www.git-scm.com
2. git 저장소 관리
# 1) 프로젝트 파일 생성 및 폴더로 진입
mkdir git_prj
cd git_prj
# 2) 현재 디렉토리를 git의 버전 저장소로 만
## 해당 폴더 내에 `.git` 이라는 디렉토리가 함께 생성되며, 해당 폴더 내에 git 관리 정보가 들어있음.
git init
3. 관리할 파일 생성
# 1) 파일 생성 및 수정
vim f1.txt
# 2) git에게 위 파일을 관리하라고 명령 (최초 생성 & 추후 수정할 때 마다)
git add f1.txt
# 3) git이 관리하는 파일 확인하기
git status
4. GIT 버전관리
# 1) Git에 내 정보 등록하기(최초 1회)
git config --global user.name [git에 가입한 아이디]
git config --global user.email [git에 가입한 이메일]
# 2) 버전 저장 하기 : "Commit"
git commit -m '버전 내용 작성'
# 3) 버전 기록 확인하기
git log
5. GIT Stage Area
1) 왜 commit 전에 add를 해야 하는가
- 파일의 버전관리에 있어서 ‘선택적 파일 관리’를 가능하게 해줌
- 협업 과정에서 여러파일을 관리하다 보면, 버전관리에 포함되어야 할 파일과 그렇지 않은 파일이 나뉠 수 있음. (stage에 올릴 파일들을 선택할 수 있음.)
< local(개인PC) --> `git add` --> Stage(=commit 대기 상태) -> git_repository >
6. GIT 변경사항 확인하기(log / diff)
# 1) 로그에서 출력되는 버전간의 차이점 확인하기
git log -p
# 2) 특정 버전간의 차이점을 비교할 때
## (1) commit 아이디 확인하기
## : git log시 commit : 'commit id' 값 확인
## (2) 버전간 차이점 확인하기
git diff 'commit_id_1' 'commit_id_2'
# 3) git add하기 전과 git add 후의 파일 내용 비교
git diff
7. Reset : 과거로 돌아가기
- 1) reset : 이전 버전 id로 돌아가기
- 2) revert : 버전 id의 커밋을 취소한 내용을 새로운 버전으로 만들기..?
# 1) reset
## : 최신 commit 대신, 과거 시점의 특정 커밋을 가장 최신 상태로 되돌리기
## reset은 git_repository에 공유하기 전단계의 파일들일 것!!
git reset --hard 'commit_id_1' # commit_id_2 --> commit_id_1
# 2) revert
git revert 'commit_id_1'
Reference
[1] [생활코딩 : 지옥에서 온 git] 버전관리의 본질
03 Aug 2021
#linux, #file, #permission, #chmod, #chown
1. 문제 상황
: linux에서 사용자 계정과 root 계정을 혼용해서 사용하다보면, 'permission error가 뜨는 경우가 종종 있다. 이때는 타 계정도 해당 폴더 및 파일에 접근하여 필요한 작업을 진행할 수 있도록 파일 권한을 변경해주어야 한다.
.
2. linux 파일 권한 읽기
: 우선 파일 및 폴더의 권한을 읽는 방법 부터 샅펴보자. ls -all명령어를 사용하면 아래와 같이 파일들의 권한과 정보를 확인 할 수 있다.
 "drwxr-xr-x 13 root tand 4096 4 3 0066" 이 정보를 하나씩 확인하면, 아래와 같다.
"drwxr-xr-x 13 root tand 4096 4 3 0066" 이 정보를 하나씩 확인하면, 아래와 같다.
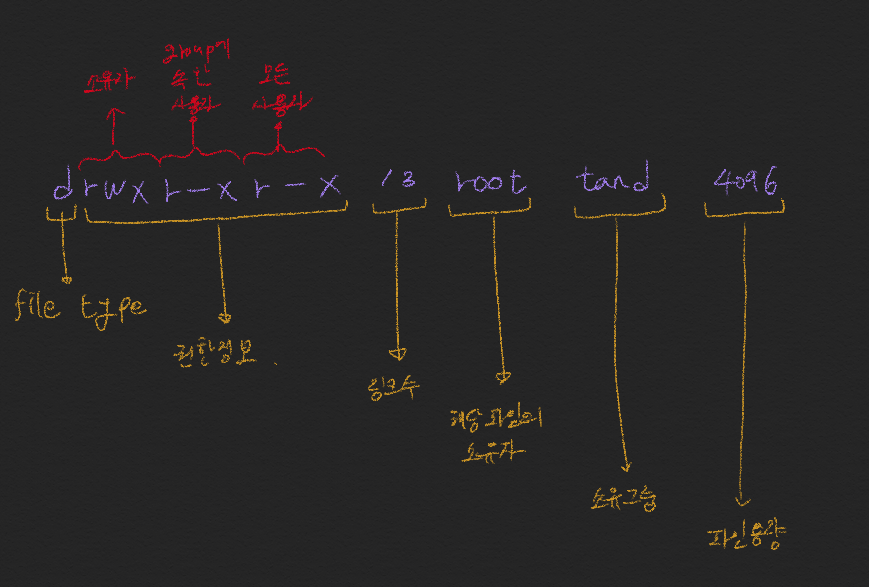
* file type
* permission 종류
r(읽기): 파일의 읽기 권한 (4)w(쓰기): 파일의 쓰기 권한 (2)x(실행): 파일의 실행 권한 (1)
3. chmod : linux 파일 권한 변경하기
chmod (옵션) [변경할 권한 값] [변경할 파일]
: 파일 소유자는 chmod 명령어를 사용해, 그룹 또는 사용자 전체에게 해당 파일의 권한을 변경해 줄 수 있다.
권한값을 지정할 때, 권한을 계산하는 방식은 각 권한에 따른 수치를 더하는 방식이다.
이때 파일이 디렉토리인 경우, -R (대문자) 옵션을 사용해 하위 폴더까지 권한을 변경하면 된다.
* 수행할 연산
+ : 권한 추가- : 권한 제거= : 권한 부여(지정) -> 기존의 권한 속성이 사라짐
* 사용자
u : user, 소유자g : group, 그룹o : other, 일반 사용자a : all, 모든 사용자
(1) 권한값을 이용해, 모든 사용자의 권한을 각각 지정하는 경우
# ex) 소유자 : rwx, 그룹 : r-x, 전체사용자 : r--
chmod 751 test.txt
# ex) 소유자 : rwx, 그룹 : r-x, 전체사용자 : r--, 하위 디렉터리 폴더 모두 변경시
chmod -R 751 file_nm
(2) 권한을 변경할 사용자를 지정하여 권한을 각각 지정하는 경우
# ex) 그룹에게 쓰기 기능을 추가
chmod -R g+w directory_nm
# ex) 모든 사용자에게 읽기,쓰기 권한을 부여
chmod -R a=rw directory_nm
4. chown : linux 파일 소유권을 변경
chown (옵션) [변경할 유저명 또는 그룹명] [변경할 파일]
: chmod는 권한을 변경했다면, chown은 파일 및 디렉토리의 소유권을 바꾸는 명령어다.
# ex_1) test.txt 파일에 대해 소유자를 user1로 바꾼다.
chown user_1 test.txt
# ex_2) test.txt 파일에 대해 그룹명을 members1로 바꾼다.
chown :members1 test.txt
# test.txt 파일에 대해 소유자 및 그룹명을 root로 바꾼다.
chown root test.txt
# test.txt 파일에 대해 소유자는 user1, 그룹명은 user2로 바꾼다.
chown user1:user2 test.txt
Reference
[1] 리눅스 권한(permisson) 설정(chmod,chown)(1)
[2] linux 파일, 폴더 권한 변경
30 Jun 2021
: 일부 반복적인 작업 과정에서 1개의 Process만을 사용함에 따라, 작업시간이 오래걸리는 문제를 해결하기 위해 MultiProcessing에 대해서 공부해보고자한다.
1. Multi-Processing vs Multi-Thread
(1) Thread?? Processing??
: MultiProcessing에 앞서서, 우선 Thread와 Processor에 대한 정의와 차이부터 살펴보자. 컴공 지식에 대해서는 잘 모르기에, 내가 알 수 있는 깊이에서 둘 간의 차이점을 살펴보자.
| |
Thread |
Processe |
| 정의 |
프로세스내에서 실제로 작업을 수행하는 주체 |
실행 중인 프로그램 |
| |
모든 프로세스에는 한개 이상의 스레드(thread)가 존재하여 작업을 진행함. |
사용자가 작성한 프로그램이 운영체제에 의해 메모리 공간을 할당받아 실행 중인 것. |
| |
하나의 프로세스에 2개 이상의 스레드(thread)를 갖는 것을 multi-Thread process라고함. |
프로세스는 프로그램에 사용되는 ‘데이터’, ‘메모리 등의 자원’, ‘스레드’로 구성됨. |
| 메모리 공유 |
메모리를 공유하여, 각 cpu가 서로의 상태를 공유할 수 있음. |
메모리를 공유하지 않음 |
| Interrupt &kill |
Interrupt & kill 불가능 |
메모리를 공유하여, 각 cpu가 서로의 상태를 공유할 수 있음. |
| Thread의 장점 |
1) 프로세스보다 생성 및 종료시간, 쓰레드간 전환시간이 짧다. |
|
| |
2) 프로세스의 메모리, 자원등을 공유하기에, 커널의 도움 없이 상호통신이 가능하다. |
|
여기까지 살펴보았을 때, 우리의 목표는 하나의 파이썬이라는 프로세스(프로그램)에서 여러개의 쓰레드를 띄워 필요한 작업을 병렬로 처리하면 될 것으로 보인다.
(2) GIL(Global Interpreter Lock)
: 그러나 슬프게도(?) 파이썬에서는 여러개의 쓰레드를 사용하는 Multi-Thread를 지원하지 않는다.
파이썬은 global변수로 하나의 인터프리터가 실행된다. 만약 쓰레드가 동시에 작동한다면, global변수를 함께 공유하게 될 것이고, 특정 스레드가 global변수를 변경할시, 동일한 변수에 접근해있던 다른 쓰레드는 엉망이 되어버릴 것이기에 한번에 하나의 Thread만이 인터프리너 내부의 global변수에 접근할 수 있도록 해놓았다.(GIL)(하나의 thread만이 접근가능한 일부 틀릴 수 있음.)
따라서 파이썬에서는 Multi Thread를 사용하더라도, Lock으로 인하여 한번에 하나의 Thread만 실행되기에, 되려 Multi core CPU라고 하더라도 실행시간이 효과가 없거나 되려 늘어나버릴 수 있다.
그렇다고 Multi-Thread를 사용할 수 없는 것은 아니다. GIL이 적용도니느 것은 CPU동작에 한해서이며, 쓰레드가 CPU동작을 마치고 I/O작업을 실행하는 동안에는 다른 쓰레드가 CP동작을 동시에 실행 할 수 있다. 따라서 CPU동작이 많지 않고 I/O동작이 더 많은 프로그램에서는 Multi-Thread를 사용하여 큰 효과를 볼 수 있다. (다만 나는 어떤 작업이 CPU가 적고 I/O가 많은지 구별하지 못한다…)
2. Multi-Processing
: 앞선 이유로 Multi-Thread 사용은 제한되지만, multiprocessing패키지를 사용하면, 프로세스 자체를 복수로 생성하여 보유하고 있는 CPU를 병렬로 사용할 수 있다. multiprocessing는 아래 두가지 방식으로 사용 가능하며, 각 수행해야 하는 테스크에 따라 적합한 방식이 달라진다.
- multiprocessing : Pool
- multiprocessing : Process
1) Pool
: Pool은 FIFO(first in, first out) 방식으로 업무를 사용가능한 Processor에게 분배한다. map-reduce방식과 유사하게 작업을 각기 다른 프로세서에게 맵(map)하고, 각 결과를 다시 수집한후(reduce) 결과를 list or array형태로 출력한다. pool은 각 프로세스가 맡은 모든 작업이 끝날 때까지 기다린후 결과를 수집하여 반환하며, 메모리 측면에서 pool은 프로세스에 할당된 작업은 메모리에 올라가지만 실행되지 않은 작업은 메모리에 올라가지 않는다.
- 작동 방식 : 각 프로세스가 맡은 모든 작업이 끝날 때까지 기다린후 결과를 수집하여 반환
- output type : list or array
- memory :프로세스에 할당된 작업만 메모리에 올라가며(stored in), 그외의 작업은 메모리에서 제외됨(stored out)
2) Process
: 반면 프로세스에 모든 프로세스를 메모리를 올려두고, 작업들을 FIFO 방식으로 스케쥴링한다.
- output type : list or array
- memory :모든 프로세스가 메모리에 올라감
3. [Pool vs Process] 무엇을 써야할까?
multiprocessing.pool : 병렬로 작업해야하는 작업량이 많으나 ‘I/O operation’이 작을 때multiprocessing.process: 병렬로 진행해야 하는 작업량이 적고, 각 작업이 한번만 진행되면 되는 상황
1) Task Number
: pool은 실행중인 작업만을 memory에 올려 두기에 task가 많아도 메모리를 모두 차지하지 않는다. 반면 Process는 실행해야하는 모든 작업을 한번에 memory에 올려두기에 작업량이 많으면 메모리 문제를 발생시킬 수 있다.
2) I/O operation
: pool은 각 process들을 FIFO 방식으로 CPU core에 할당하고, 할당된 process는 순자적으로 실행된다. 따라서 이때 시간이 길게 소요되는 I/O Operation이 있다면, Pool은 I/O operation이 끝날 때 까지 기다리며 process들의 스케쥴을 잡지 않게된다. 이는 결국 큰 시간 소요로 이어지게 된다. 반면 process class는 I/O operation 실행을 잠시 중지하며, 다른 process의 스케쥴을 잡기에 I/O 작업이 길어도 비효율적으로 시간을 소모하지 않는다.
4. Multi-Processing Code
import numpy as np
import multiprocessing
import time
# 전체 작업량
task = list(range(100000000))
0) single core
start_time = time.time()
output = 0
gen = (i for i in task)
for i in gen :
output += i
print("---%s second ---"% (time.time() - start_time))
# ---9.102992296218872 second ---
1) multiprocess.pool
# 1. 작업 분할 및 process 개수 지정
## 1) 코어 개수 생성
n_process = 4 #calc_n_procs_core(task)
## 2) 작업분항(job_list) 생성
job_list = np.array_split(task, n_process)
# 2. multiprocess
## 1) 실행할 작업 함수
def list_sum(target_lst) :
output = 0
gen = (i for i in target_lst)
for i in gen :
output += i
return output
## 2) multiprocess.pool 객체 생성
start_time = time.time()
if __name__ == '__main__' :
lst_tmp = []
# multiprocess
pool = multiprocessing.Pool(processes = n_process)
lst_pool = pool.map(list_sum, job_list)
pool.close()
pool.join()
print(sum(lst_pool))
print("---%s second ---"% (time.time() - start_time
# 4999999950000000
# ---7.931491851806641 second ---
2) multiprocess.Prcoess
# 1. 작업 분할 및 process 개수 지정
## 1) 코어 개수 생성
# n_process = 4 #calc_n_procs_core(task)
## 2) 작업분항(job_list) 생성
job_list = np.array_split(task, n_process)
# 2. multiprocess
## 1) 각 프로세스에서 반환한 Output을 list형태로 묶어주기 위해서 manager 메서드 사용
manager = multiprocessing.Manager()
fin_list = manager.list()
## 2) 실행할 작업 함수
def list_sum(target_lst) :
output = 0
gen = (i for i in target_lst)
for i in gen :
output += i
fin_list.append(output)
return output
## 3) multiprocess.process 객체 생성
def multiProcess_main() :
procs = []
for _job in job_list :
lst_tmp = []
# multiprocess
proc = multiprocessing.Process(target = list_sum, args = (_job,))
procs.append(proc)
proc.start() # 프로세스 시작
for proc in procs :
proc.join() # 프로세스 종료
start_time = time.time()
if __name__ == '__main__' :
multiProcess_main()
print(sum(list(fin_list)))
print("---%s second ---"% (time.time() - start_time))
#4999999950000000
#---6.672454118728638 second ---
Reference
1. Multi-Processing vs Multi-Thread
[1] Thread란?
[2] Thread와 MultiProcessing 차이점
2 & 3 . Multi-Processing
[1] Python Multiprocessing: Pool vs Process – Comparative Analysis
4. Multi-Processing Code
[1] [Python] 병렬처리(Multiprocessing)를 통한 연산속도 개선