08 Aug 2020
: 추천 시스템, 자연어처리등을 하다보면 모든 아이템 또는 각 워드를 컬럼으로 사용해야하는 One-Hot-Encoding을 종종하게 됩니다. 그러나 이때 너무 많은 아이템 또는 단어가 컬럼 변환되며 이과정에서 대부분의 value는 0으로 이루어져 메모리만 크게 차지하는 희소 행렬을 자주 마주하게 됩니다. 이를 해결하기 위해 Sparse matrix의 종류중 하나인 CSR Matrix를 사용할 수 있으나, 문제는 인덱스만으로 이루어져있는 Sparse Matrix 특성상 종종 기존의 matrix에 적용하던 함수를 그대로 사용하면 에러가 발생하는 문제가 있어 이를 다시 어떻게 풀어가며 활용할지 CSR Matrix의 원리와 사용법을 살펴보고자 합니다.
1. CSR Matrix(Compressed Sparse Row) Concept
: CSR Matrix는 단어 그대로, row별로 데이터를 압축하여 값이 존재하는 row별 column값을 출력합니다.
| id |
A |
B |
C |
D |
| 정형돈 |
1 |
3 |
0 |
0 |
| 유재석 |
0 |
5 |
0 |
2 |
| 노홍철 |
0 |
0 |
2 |
0 |
위와 같은 행렬이 존재한다고 할때, sparse matrix의 결과는 아래와 같습니다.
print(csr)
(0, 0) 1
(0, 1) 3
(1, 1) 5
(1, 4) 2
(2, 2) 2
이때 4번째 줄을 해석하는 방법은 1번째 row의 4번째 컬럼에 2이라는 값이 있다고 해석하면 됩니다.
1) CSR Matrix 생성하기-1
: 우선 이미 sparse한 형태의 matrix를 갖고 있다면, 이를 CSR Matrix로 변환하는 것은 csr_matrix()함수를 사용해 쉽게 csr_matrix를 생성할 수 있습니다.
import numpy as np
from scipy.sparse import csr_matrix
x = [[1, 0, 0, 3, 0, 0],
[0, 0, 2, 0, 5, 0],
[0, 0, 0, 0, 1, 2],
[2, 3, 0, 0, 0, 4]]
x = np.asarray(x)
csr = csr_matrix(x)
csr
# <4x6 sparse matrix of type '<class 'numpy.longlong'>'
# with 9 stored elements in Compressed Sparse Row format>
print(csr)
# (0, 0) 1
# (0, 3) 3
# (1, 2) 2
# (1, 4) 5
# (2, 4) 1
# (2, 5) 2
# (3, 0) 2
# (3, 1) 3
# (3, 5) 4
2) CSR Matrix 생성하기-2
: 그러나 이미 희소행렬 자체가 너무 크다면, 이를 array 형태로 생성하는 것 조차 불가능한 경우가 있습니다. 즉 One-Hot-Encoding 자체가 메모리 이슈로 인해 진행되지 않는 상황입니다.
이 경우, OHE과정에서 sparse_output = ture옵션을 활용해 OHE output matrix를 csr sprase matrix로 생성할 수 있습니다.
(특정 row가 2개 이상의 value를 갖고 있는 multi label의 상황을 가정하여 진행하였습니다.)
import pandas as pd
df = pd.DataFrame({'id' : [1,2,3,4,5],
'value' : [['a','b'],
['b','f'],
['c'],
['a', 'c', 'e'],
['e','f']]})


from scipy import sparse
from sklearn.preprocessing import OneHotEncoder, MultiLabelBinarizer
## 1) INSTANTIATE
enc = MultiLabelBinarizer(sparse_output=True)
## 2) FIT & Transform
df_mat = enc.fit_transform(df.value) # label이 들어가는 value를 input으로 fit_transform 시켜줄 것
print(df_mat)
# (0, 0) 1
# (0, 1) 1
# (1, 1) 1
# (1, 4) 1
# (2, 2) 1
# (3, 0) 1
# (3, 2) 1
# (3, 3) 1
# (4, 4) 1
# (4, 3) 1
2. CSR Matrix indexing
csr_matrix는 data, indices, indptr 세가지 구성요소를 갖고있습니다.
data : matrix내에 있는 모든 0이 아닌 value값indices : value가 위치한 columnd의 indexindptr : indptr은 위 indices를 기준으로, 각 row내 value의 indices 시작점과 끝점을 알려준다.
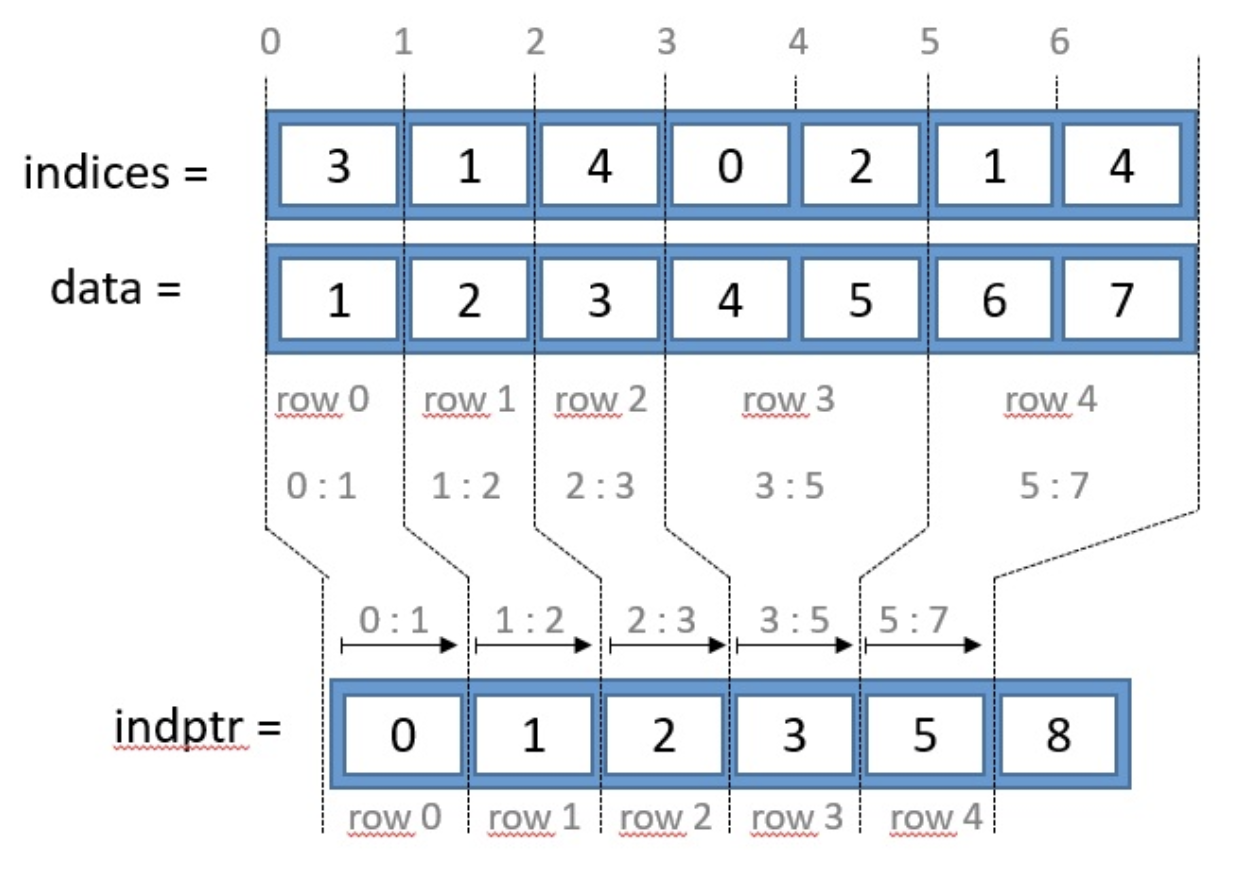
# 1) data
df_mat.data
# array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
# 2) indices
df_mat.indices
# array([0, 1, 1, 4, 2, 0, 2, 3, 4, 3], dtype=int32)
# 3) indptr
df_mat.indptr
# array([ 0, 2, 4, 5, 8, 10], dtype=int32)
위와 같이 생성한 행렬의 indices값을 토대로 0~2번째까지 값은 첫번째 row, 5~8번째 값은 row는 4번째 row에 속하는 값임을 알 수 있습니다.
-
nonzero()
당장 위의 3가지 인덱싱을 이해하더라도 csr_matrix가 잘 이해되지 않는다면 .nonzero()를 사용해 값이 위치한 행과 열의 인덱스를 직관적으로 확인해 볼 수 있습니다.
-
todense()
끝으로, todense() 압축한 csr_matrix를 다시 익숙한 dense matrix로 변환해줍니다.
df_mat.nonzero()
# (array([0, 0, 1, 1, 2, 3, 3, 3, 4, 4], dtype=int32),
# array([0, 1, 1, 4, 2, 0, 2, 3, 4, 3], dtype=int32))
df_mat.todense()
# matrix([[1, 1, 0, 0, 0],
# [0, 1, 0, 0, 1],
# [0, 0, 1, 0, 0],
# [1, 0, 1, 1, 0],
# [0, 0, 0, 1, 1]])
여기까지 csr_matrix의 기본활용방법을 살펴봤습니다. csr_matrix는 큰 데이터를 다뤄야하는 추천 모델, 딥러닝 등 다양한 분야에서 자주 사용됩니다. 때문에 잘 만들어진 패키지 내부를 보면 csr_matrix의 인덱스를 활용해 큰 matrix도 상대적으로 가볍게 변환하여 연산을 진행하는 모습을 종종 볼 수 있었습니다. 다음엔, index를 활용해 만들어진 함수를 살펴보며 활용법을 배워보면 좋을 것 같습니다.
Reference
[1] https://lovit.github.io/nlp/machine%20learning/2018/04/09/sparse_mtarix_handling/
[2] https://bkshin.tistory.com/entry/NLP-7-%ED%9D%AC%EC%86%8C-%ED%96%89%EB%A0%AC-Sparse-Matrix-COO-%ED%98%95%EC%8B%9D-CSR-%ED%98%95%EC%8B%9D
01 Aug 2020
추천 시스템 : Matrix Factorization
(1) 개요
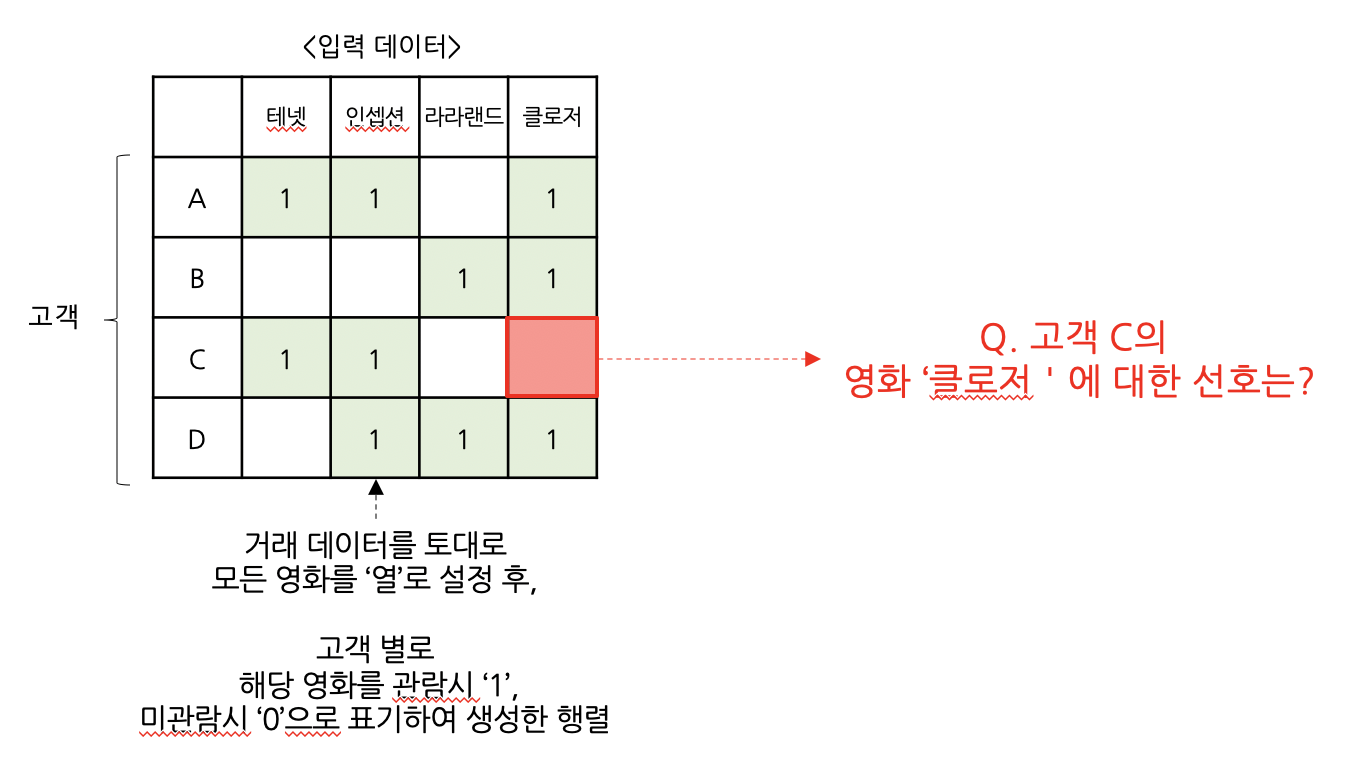
: 유저와 아이템간의 상호작용 데이터(거래 데이터)를 기반으로 ‘잠재요인’을 찾아내고,
찾아낸 잠재요인을 기반으로 유저가 관람하지 않은 아이템에 대해서 평가하는 알고리즘
(2) 목표
: 특정 고객의 과거 관람 이력을 토대로 , 아직 관람하지 않은 신규 영화의 선호 예측
Step ① 유저 잠재 행렬 & 아이템 잠재 행렬 생성
: 주어진 거래데이터(입력 데이터)를 활용해, 유저별로 어떤 장르 취향을 지니고 있는지 & 영화별로는 어떤 장르 특성을 지니고 있는지 학습하고자 합니다.
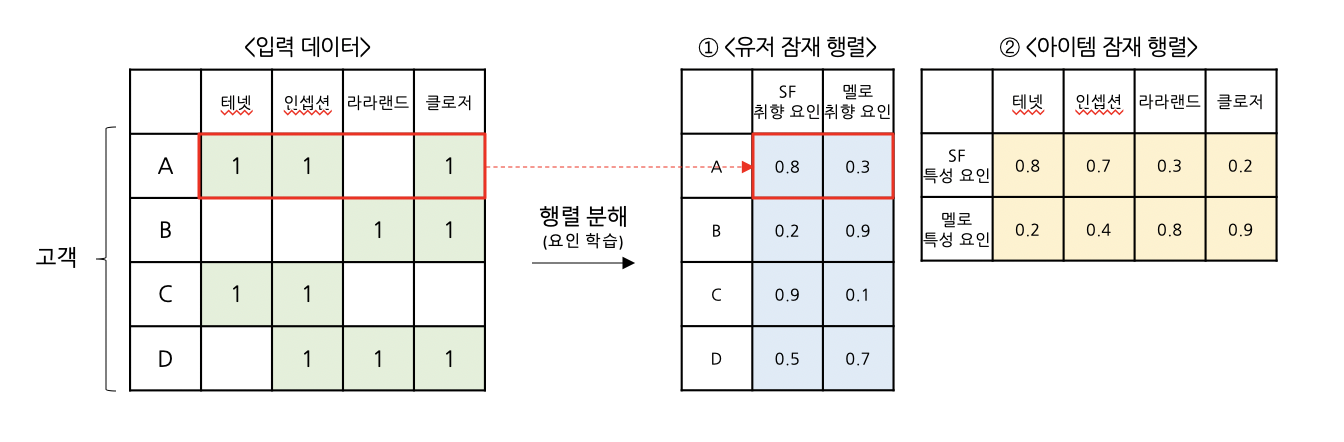
① <유저 잠재="" 행렬="">
: 위 예시에서 ‘SF요인’과 ‘멜로요인’ 두 가지로 학습을 진행해, 고객별로 ‘SF 취향’과 ‘멜로 취향’ 점수를 계산합니다.
e.g. A고객은 [테넷, 인셉션, 클로저] 영화를 관람하였고 그 결과, “A고객은 ‘SF 취향’ 은 0.8로 높으며, '멜로 취향’은 0.3점으로 낮다”고 고객의 선호를 정의할 수 있습니다.
또한, 유저 잠재 행렬을 통해서 고객 A와 고객C가 서로 유사한 취향을 갖고 있다고도 알 수 있습니다.
② <아이템 잠재="" 행렬="">
:영화도 동일한 방식으로, 영화별로 ‘SF 특성’과 ‘멜로 특성’ 점수를 계산하고, 영화의 특성을 정의합니다.
Step ② 예측값 생성
: <유저 잠재="" 행렬=""> & <아이템 잠재="" 행렬="">을 토대로,
“고객의 선호”와 ”아이템의 특성”을 2가지 요인(SF & 멜로)으로 정의 했습니다.
이는 즉,
우리는 고객의 선호를 알고 있고,
동시에 영화의 특성을 알고 있다는 의미입니다.
따라서, 고객이 관람하지 않은 영화라고 하더라도,
계산되어 있는 ‘고객의 선호’와 ‘영화의 특성’을 결합하면,
해당 영화를 고객이 얼마나 선호할지 계산 할 수 있습니다.
이제, 우리가 해결하고자 했던, 고객 C의 영화 ‘클로저’에 대한 선호점수를 계산해봅시다.
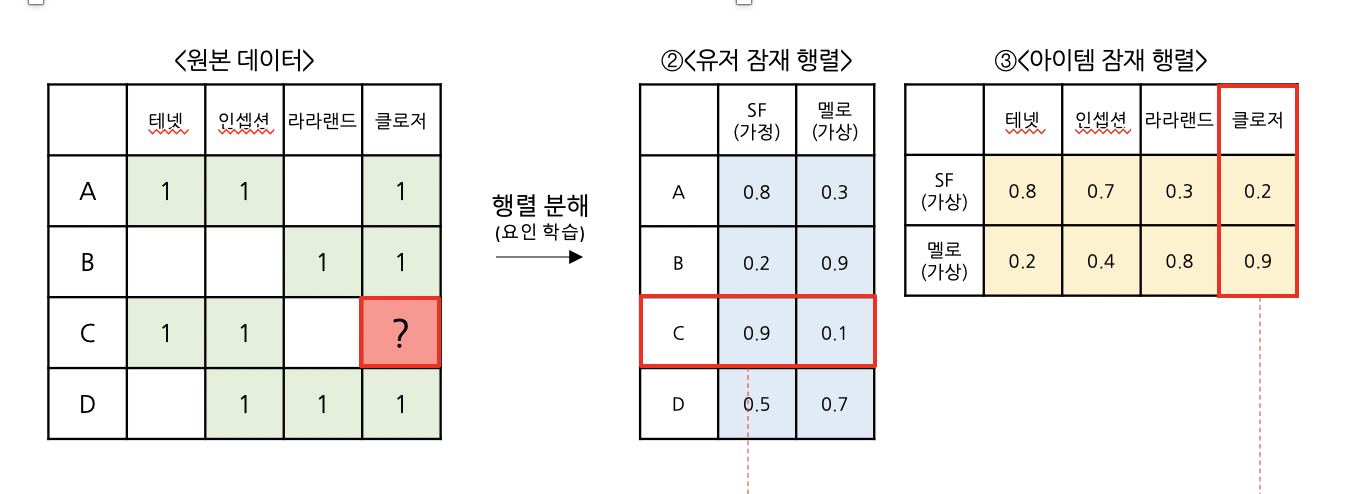
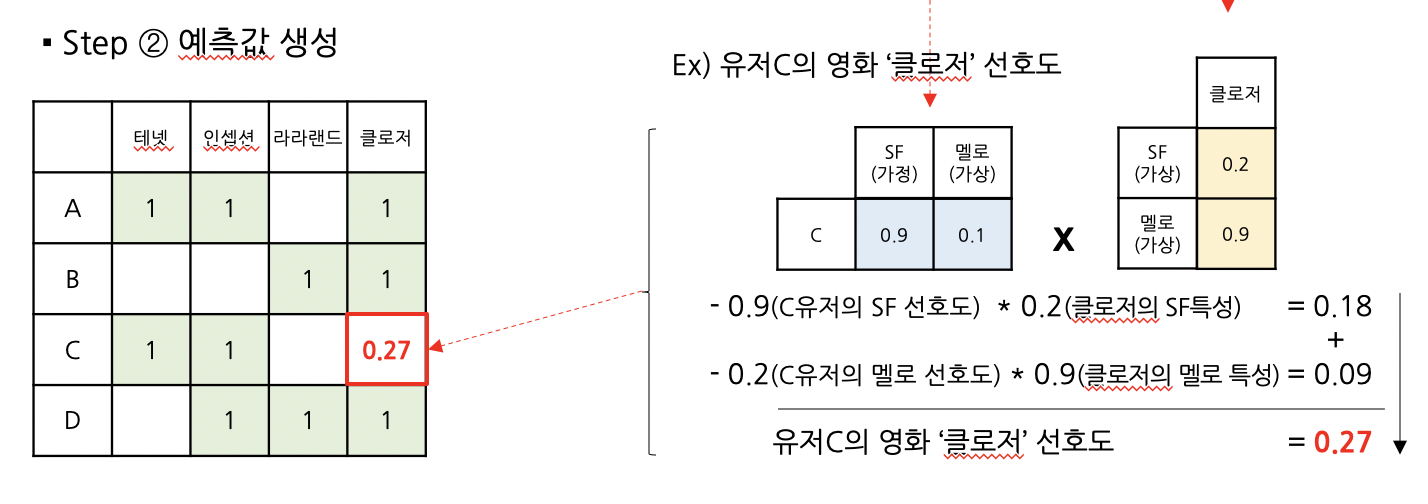 이처럼 고객의 선호값에 영화의 특성값을 곱하면,
고객이 관람하지 않은 영화에 대한 선호를 예측할 수 있습니다.
동일한 방법으로 모든 고객의 취향값에 모든 영화의 특성값을 계산하면,
최종 예측 행렬을 얻을 수 있습니다.
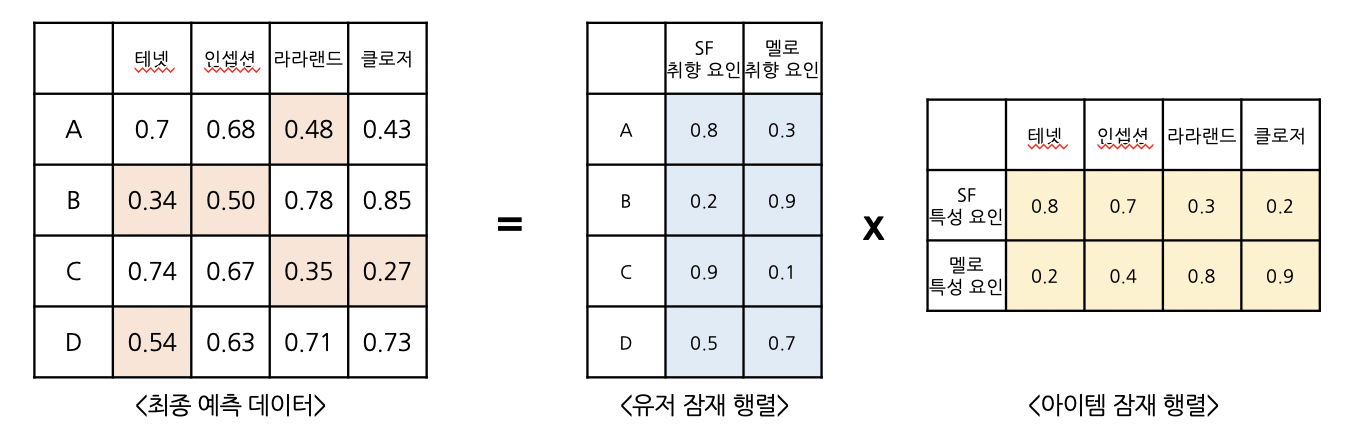
이처럼 고객의 선호값에 영화의 특성값을 곱하면,
고객이 관람하지 않은 영화에 대한 선호를 예측할 수 있습니다.
동일한 방법으로 모든 고객의 취향값에 모든 영화의 특성값을 계산하면,
최종 예측 행렬을 얻을 수 있습니다.
Reference
[1] 추천 시스템 – 잠재 요인 협업 필터링
[2] 갈아먹는 추천 알고리즘 3 Matrix Factorization
25 Jul 2020
Collaborative Filtering for Implicit Feedback Datasets
0. Abstract
: 추천 시스템의 기본 목표는 사용자가 과거에 생성한 암시적인 피드백 정보를 활용하여 개인화된 추천을 제공해주는 것입니다. 그러나, like & dislike가 명확히 표현되어 있지 않은 데이터에 있어서는 사용자가 어떤 아이템을 싫어하는지를 판단하는 것은 쉬운일이 아니게 됩니다.
때문에 이 논문에서 제시하는 방법론은, 다양한 신뢰 수준(confidence level)에서 긍정과 부정적 선호를 다루고자 합니다. 이는 특히 긍정&부정 선호가 명확하지 않은 Implicit Feedback Datasets에서 중요한 모델로 활용됩니다.
1. Introduction
1) Contents Based
: 영화의 장르, 감독, 배우, 흥행도 등을 사용해 유사한 작품군을 생성하고, 이를 기반하여 추천 모델을 구축합니다. 그러나 위와 같은 자세한 데이터 자체를 구축하기가 현실적으로 여렵다는 문제를 갖고 있습니다.
2) CF(Collaborative Filtering)
: 선호가 남아있지 않은 user와 item간의 관계를 파악하기 위해, ‘고객 유사도’와 ‘아이템 유사도’를 계산합니다. 과거 거래내역 또는 평가 데이터를 활용하며, 정확도 또한 앞서 Contents Based보다 뛰어나 가장 많이 활용되는 방법입니다.
3) Implicit Data 특징
: Implicit data는 구매이력, 검색이력, 마우스 클릭 등의 선호가 명확하게 표현되어있지않은 데이터를 말합니다. Implicit data의 주요 특징은 몇가지를 살펴보면 아래와 같습니다.
-
- (1) No Negative feedback
- 구매하지 않은 데이터는, 선호하지 않은 것이지 혹은 해당 아이템의 존재를 알지 못한 것인지 알 수 없음.
-
- (2) Implict feedback is inferently noisy
- 소비내역을 토대로 ‘선호’ 아이템이라고 단정 지을 수 없습니다. 구매 이후에 해당 제품에 대해서 만족하지 못했을 가능성이 존재.
-
- (3) 명시적 수치 = 선호 / 암시적 수치 = 신뢰성
- 암시적 데이터는 명확하게 선호와 비선호를 확인할 수는 없지만, 단순 binary가 아닌, 수치값으로 동일한 데이터를 중복해서 구매 했다면, 이는 높은 신뢰수준에서 선호.
-
- (4) Evaluation
- explicit data는 MSE를 활용해 선호가 존재하는 데이터에 한하여 정확도를 비교할 수 있으나, implicit data에서는 0으로 남아있는 비구매 데이터를 제외하지 않으며 이를 구매하지 않았다고 싫어한다고 이야기 할 수 없어 단순 MSE를 사용하기 어렵.
2. Preliminaries
- users : u, v
- items : i, j
- $r_ui$ : number of times u purchased item(original rating)
3. Previous work
1) Latent factor model
: 대표적 잠재 요인 모델인 SVD모델은 “유저-유저 잠재요인”과 “아이템-아이템 잠재요인” 행렬을 생성하고, 이 두 행렬을 내적하여 예측결과를 제공합니다.
- $x_u$ : user(u) & user factor($x_u$)
- $y_i$ : item(i) & item factor($y_i$)
- $\hat r_{ui} = x^T_u y_i$
SVD object
$min_{xy} \sum (r_{ui} - x^T_u y_i)^2 + \lambda(||x_u||^2 + ||y_i||^2)$
: 명시적 데이터 셋에서는 선호가 남아있는 값에 한하여 MSE를 진행하고, 과적합을 피하기 위해에 정규화항을 두었습니다. 이때 $\lambda$ 는 정규화를 위해 사용되는 파라미터로 SGD(stochastic gradient descent)를 활용해 계산합니다.
4. Our model
(1) Raw observation($r_{ui}$) into two separate magnitudes($p_{ui}, c_{ui}$)
-
- $p_{ui}$ = { 1 $r_{ui}$ > 0 | 0 $r_{ui}$ = 0}
- 유저의 선호를 0과 1로 나타낸 set (preference of user $u$ to item $i$)
ex) 유저($u$)가 아이템($i$) 소비시 $r_{ui}$ > 0 이며, $p_{ui}$ = 1
-
- $c_{ui} = 1 + \alpha r_{ui}$
- implicit 데이터에서 선호를 나타내는 $p_{ui}$만으로는 선호를 확정할 수 없기에 다야한 수준에서 신뢰도를 나타낼 수 있는 지표가 필요하다. 신뢰도의 개념으로 기존 ‘0’이던 값들도 최소한의 신뢰도 수준에서 값을 지닐 수 있게 되며, preference가 존재하는 값은 $\alpha$에 비례해 커지게 된다.($\alpha$ = 40)
(2) ALS object
: 목표는 기존의 MF와 동일하게 user-factor & item-factor의 잠재요인을 찾아내, $p_{ui}$를 계산하는 과정이다. 그러나 이때 아래의 다음 두 가지 차이점이 존재한다.
(1) 다양한 신뢰수준($c_{ui}$ 설명(계산)하기
(2) 관찰되지 않은 모든 데이터 쌍($u,i$)에 대해서 optimization을 진행
$min_{xy} \sum_{u,i} c_{ui}(p_{ui} - x^T_u y_i)^2 + \lambda(\sum||x_u||^2 + \sum||y_i||^2)$
: item or user factor가 고정되면 cost function은 quadratic 방정식이되어 global minimum을 계산할 수 있게 된다.(Alternating-Least-Squares optimization process)
-
step 1
: 아이템 latent factor 행렬을 고정하고, 사용자의 latent factor를 계산합니다.
위 loss funcition에서 $y_i$를 상수로 취급한 다음 미분을 진행하면 되며, 미분 결과 유저 행렬 $x_u$는 다음과 같이 산출됩니다.
$x_u = (Y^TC^uY + \lambda I)^{-1}Y^TC^up(u)$
다음 초기 랜덤하게 설정된 유저 행렬을 위에서 계산된 값으로 업데이트 해줍니다.
-
step 2
: 다음으로 사용자 행렬($x_u$)을 고정하고 아이템의 latent factor를 계산합니다.
$y_i = (X^TC^iX + \lambda I)^{-1}X^TC^ip(i)$
마찬가지로 랜덤하게 설정된 아이템 행렬을 업데이트 시켜줍니다.
-
step 3
: 위의 과정을 통해 최적의 user & item 행렬을 찾아내며 보통 이때의 loop 횟수는 10~15회 정도로 설정됩니다.
ALS 결과 업데이트 된 $x_u, y_i$를 곱해 고객 u의 아이템 i에 대한 선호 $\hat p_{ui}$를 계산 할 수 있게 됩니다.
$\hat p_{ui} = x_u^T y_i$
[github link : ALS_test_code Link](https://github.com/TaeHwanYoun/taehwanyoun.github.io/blob/master/test_code/ALS%20Implementation.ipynb)
Reference
[1] Yifan Hu et al. Collaborative Filtering for Implicit Feedback
[2] 갈아먹는 추 알고리즘 [4] Alternating Least Squares
25 Jul 2020
: Latent Factor Based Collaborative Filtering은 행렬 분해(Matrix Facotrization)에 기반한 알고리즘으로,
사용자 행렬과 아이템 행렬을 각각 잠재요인 기준으로 생성한 후 이를 다시 내적하여 사용자가 아직 선호를 나타내지 않은 아이템에 대해서도 선호를 예측
Basic Concept
1. 행렬 분해
: 행렬 분해는 주어진 사용자-아이템 행렬을 ‘사용자-잠재요인’행렬 , ‘아이템-잠재요인’ 행렬로 분해.
여기서 우리가 설정하게 되는 ‘잠재요인’이란, ‘영화’를 분류하는데 있어서 액션/로맨스/코미디 등과같이 서로 다른 ‘장르’라고 대략적으로 생각.
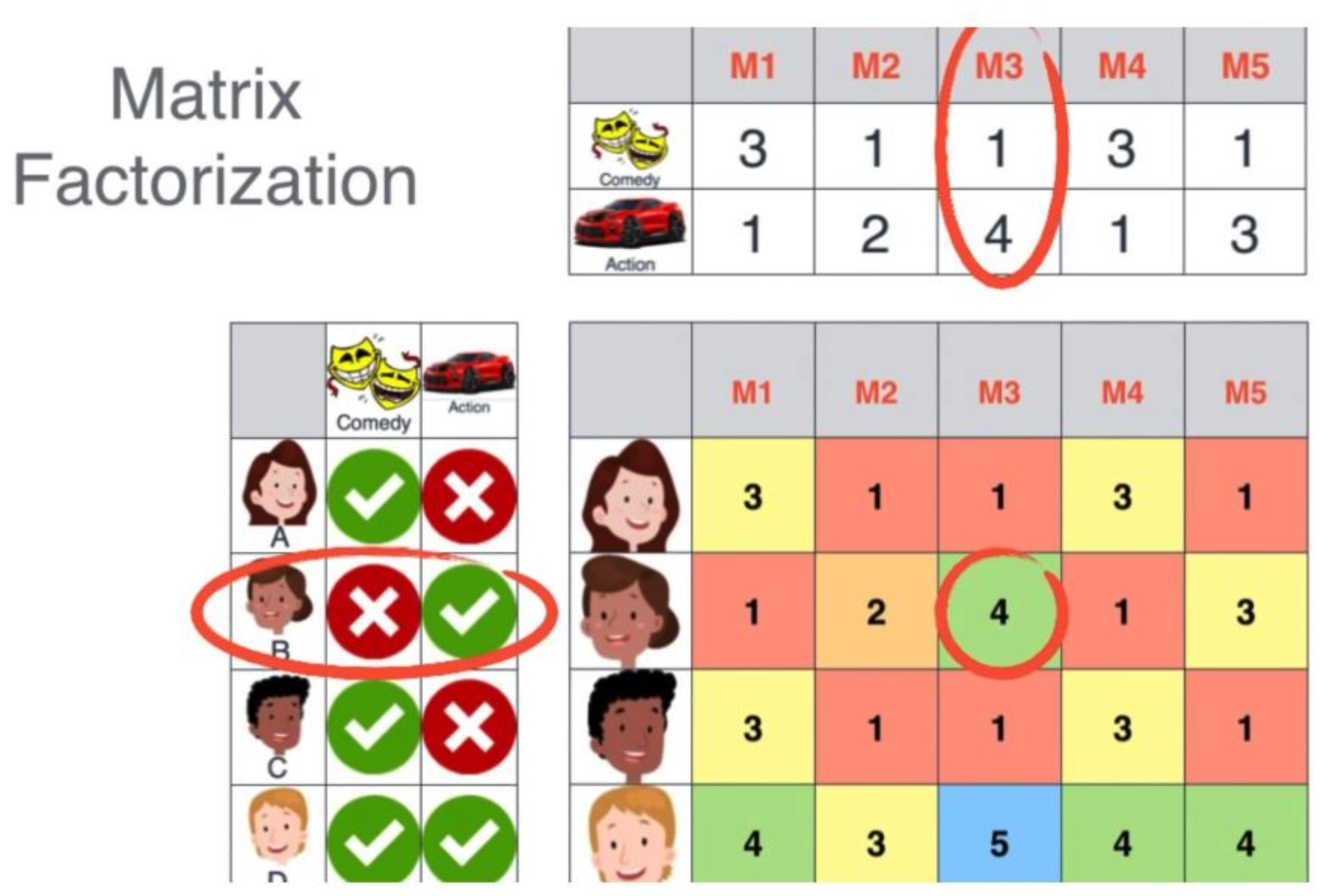
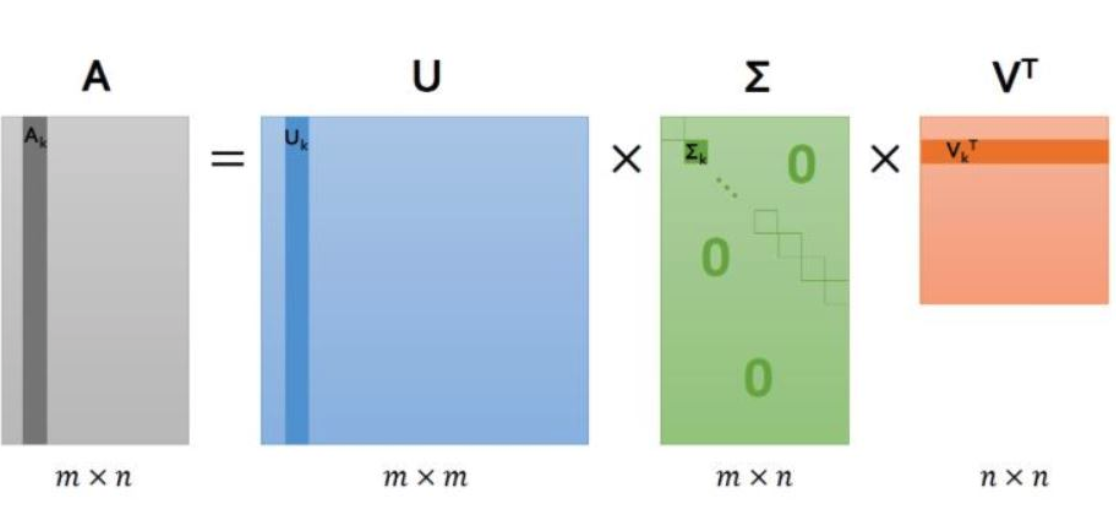
- $U$ (사용자-잠재요인) : 사용자별 어떤 장르(잠재요인) 선호를 갖고 있는지 분해
- $\sum$ (잠재요인)
- $V^T$ (아이템-잠재요인) : 영화별 어떤 장르(잠재요인) 성격을 갖고 있는지 분해
2. 행렬 결합
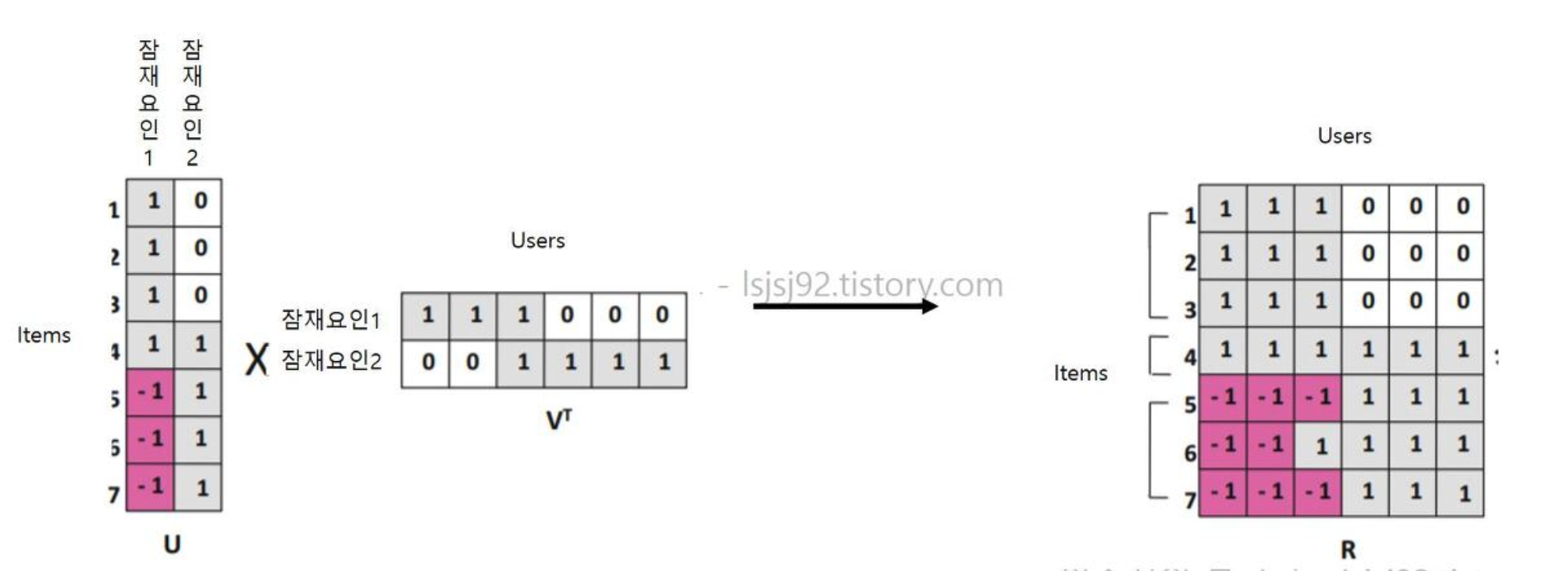 앞선 분해된 행렬을 다시 내적으로 곱해주면,
초기 '사용자-아이템'과 유사한 원본행렬이 생성되면서,
기존에 관람(평가)하지 않았던 아이템에 대해서도 점주를 매길 수 있게 됩니다.
앞선 분해된 행렬을 다시 내적으로 곱해주면,
초기 '사용자-아이템'과 유사한 원본행렬이 생성되면서,
기존에 관람(평가)하지 않았던 아이템에 대해서도 점주를 매길 수 있게 됩니다.

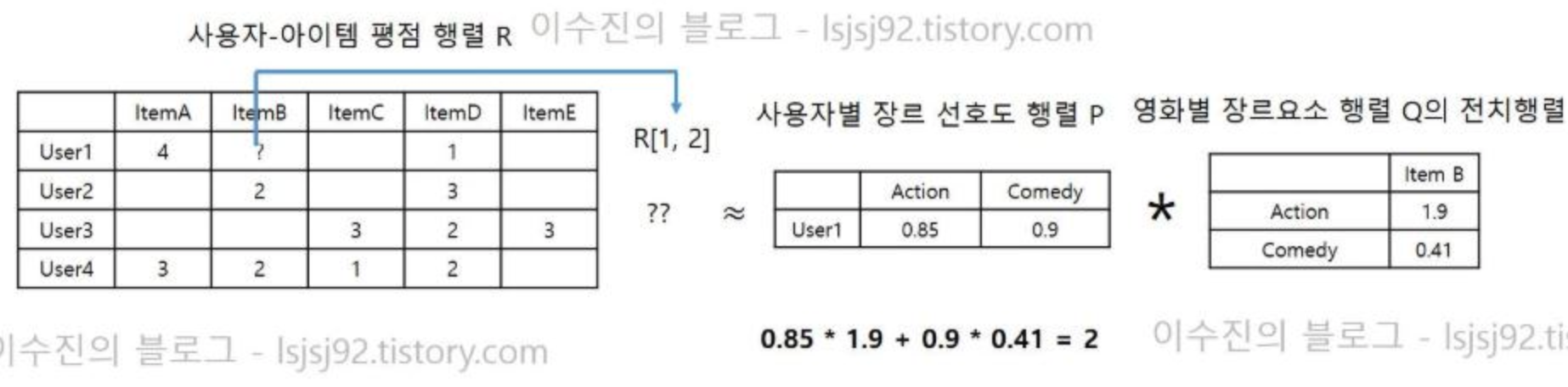
2. 구현하기
from sklearn.decomposition import TruncatedSVD
from scipy.sparse.linalg import svds
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
피봇 테이블을 이용해, 영화명이 컬럼으로 들어가 있는 데이터 프레임 생성한다.
# Data Import
# src : https://www.kaggle.com/sengzhaotoo/movielens-small
rating_data = pd.read_csv('./datas/movie_lens/ratings.csv')
movie_data = pd.read_csv('./datas/movie_lens/movies.csv')
# preprocess
rating_data.drop('timestamp', axis = 1, inplace = True)
movie_data.drop('genres', axis = 1, inplace = True)
user_movie_data = pd.merge(rating_data, movie_data, on = 'movieId')
user_movie_rating = user_movie_data.pivot_table('rating', index = 'userId', columns='title').fillna(0)
우선, 영화간 유사도를 계산하여 특정 영화를 입력할 때, 해당 영화와 유사한 영화를 추출해내는 모델을 만들어 보자. 영화간 유사도를 계산하기 위해, 사용자 기준이었던 행렬을 영화중심으로 변환해준다.
- input : item
- output : similar item
1) 유사 영화 추천
# 영화-사용자 행렬 생성
movie_user_rating = user_movie_rating.values.T # 영화 - 사용자 행렬
(1) 행렬 분해 & 결합
영화 기준의 행렬을 TruncatedSVD 함수를 행렬분해를 진행하였다.
일반 SVD의 결과는 원본 행렬과 동일한 shape을 갖춰야 하지만, TruncatedSVD는 행렬곱의 결과를 시그마 행렬의 특이값 가운데 상위 n개만으로 압축해서 출력해준다. 이로 인해 정보량의 손실이 발생하기는 하지만, 거의 유사한 행렬을 얻으면서 메모리를 절약할 수 있다.
(결과 행렬은 0이 거의 존재하지 않는 Dense Matrix이기에 영화간 유사도만을 계산하기 위한 행렬에 굳이 사용자의 모든 선호를 출력해주는 컬럼을 유지할 필요가 없지 않았을까 한다.)
# 행렬 분해
SVD = TruncatedSVD(n_components=12)
matrix = SVD.fit_transform(movie_user_rating)
matrix.shape # 9064 x 12
(2) 상관계수 계산
# 상관계수 계산
corr = np.corrcoef(matrix)
corr.shape # (9064 * 9064)
# Matrix index에 영화명 연결
movie_title = user_movie_rating.columns
movie_title_list = list(movie_title)
# 유사 영화 출력
movie_name = "Guardians of the Galaxy (2014)"
coffey_hands = movie_title_list.index(movie_name)
corr_coffey_hands = corr[coffey_hands]
list(movie_title[(corr_coffey_hands >= 0.9)])[:50]
2) 사용자 개인 추천
위에서 영화간 유사도 통해 유사한 아이템을 확인해 보았으나, 실제 개인화 추천모델이라면 사용자를 input값으로 넣었을 때, 사용자에게 적합한 아이템 리스트가 output으로 출력되는 형태가 좀더 자연스러울 것이다. 그렇기에 이번엔 사용자 사용자 개인을 기준으로한 matrx 활용해보자.
- input : user_id
- output : item
# 사용자-영화 행렬
user_movie_rating.head()
이때 각 사용자별 사용자 평점을 빼주는 작업은 사용자 별 평점을 주는 정도가 다름을 반영하기 위함이다. 누군가는 굉장히 재미있게 본 영화도 3점을 주는 반면 누군가는 5점을 주는 등 개인의 선호가 다르기에 이를 개인화 시켜주기 위해 평균을 빼준다.(평점 데이터가 아닌, 단순 관람 데이터인 경우 필요치 않음)
matrix = df_user_movie_ratings.as_matrix() # matrix는 pivot_table 값을 numpy matrix로 만든 것
user_ratings_mean = np.mean(matrix, axis = 1)# user_ratings_mean은 사용자의 평균 평점
matrix_user_mean = matrix - user_ratings_mean.reshape(-1, 1) # R_user_mean : 사용자-영화에 대해 사용자 평균 평점을 뺀 것.
(1) 행렬 분해
TruncatedSVD함수와는 달리, scipy패키지에서 제공해주는 svds함수는 Output으로 분해된 3개의 행렬을 그대로 출력해준다.
#scipy에서 제공해주는 svd.
# U 행렬, sigma 행렬, V 전치 행렬을 반환.
U, sigma, Vt = svds(matrix_user_mean, k = 12)
print(U.shape)
print(sigma.shape)
print(Vt.shape)
#(671, 12)
#(12,)
#(12, 9066)
# 이때 sigma 행렬은 현재 1차원 행렬로 되어있기에, 0을 포함한 대각행렬로 만들어줌
sigma = np.diag(sigma)
sigma.shape
(2) 행렬 결합
위 행렬을 내적하는 과정에서, TruncatedSVD와 달리 모든 컬럼을 그대로 출력해주기에 메모리 이슈에 주의해야 한다.
# U, Sigma, Vt의 내적을 수행하면, 다시 원본 행렬로 복원이 된다.
# 거기에 + 사용자 평균 rating을 적용한다.
svd_user_predicted_ratings = np.dot(np.dot(U, sigma), Vt) + user_ratings_mean.reshape(-1, 1)
# 생성된 matrix를 데이터 프레임 형태로 변환
df_svd_preds = pd.DataFrame(svd_user_predicted_ratings, columns = df_user_movie_ratings.columns)
df_svd_preds.head()
def recommend_movies(df_svd_preds, user_id, ori_movies_df, ori_ratings_df, num_recommendations=5):
#현재는 index로 적용이 되어있으므로 user_id - 1을 해야함.
user_row_number = user_id - 1
# 최종적으로 만든 pred_df에서 사용자 index에 따라 영화 데이터 정렬 -> 영화 평점이 높은 순으로 정렬 됌
sorted_user_predictions = df_svd_preds.iloc[user_row_number].sort_values(ascending=False)
# 원본 평점 데이터에서 user id에 해당하는 데이터를 뽑아낸다.
user_data = ori_ratings_df[ori_ratings_df.userId == user_id]
# 위에서 뽑은 user_data와 원본 영화 데이터를 합친다.
user_history = user_data.merge(ori_movies_df, on = 'movieId').sort_values(['rating'], ascending=False)
# 원본 영화 데이터에서 사용자가 본 영화 데이터를 제외한 데이터를 추출
recommendations = ori_movies_df[~ori_movies_df['movieId'].isin(user_history['movieId'])]
# 사용자의 영화 평점이 높은 순으로 정렬된 데이터와 위 recommendations을 합친다.
recommendations = recommendations.merge( pd.DataFrame(sorted_user_predictions).reset_index(), on = 'movieId')
# 컬럼 이름 바꾸고 정렬해서 return
recommendations = recommendations.rename(columns = {user_row_number: 'Predictions'}).sort_values('Predictions', ascending = False).iloc[:num_recommendations, :]
return user_history, recommendations
already_rated, predictions = recommend_movies(df_svd_preds, 330, df_movies, df_ratings, 10)
Reference
[1] https://dc7303.github.io/python/2019/08/06/python-memory/
[2] https://yeomko.tistory.com/5?category=805638
[3] https://scvgoe.github.io/2017-02-01-%ED%98%91%EC%97%85-%ED%95%84%ED%84%B0%EB%A7%81-%EC%B6%94%EC%B2%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C-(Collaborative-Filtering-Recommendation-System)/
- 본 포스트는 이수진님의 블로그를 참조하며 공부하기 위해 작성하였습니다.
24 Jul 2020
1. 추천 알고리즘 종류
1) Contents Based Filtering
: 유저 및 아이템의 정보를 기반해 추천해주는 방식으로, 유저(또는 아이템)의 나이, 성별 등을 토대로 유사한 유저를 찾고 해당 유저의 관람 이력을 추천해준다. 이때 유사도를 확인하기 위해 코사인 유사도, 자카드 유사도등을 활용할 수 있다.
2) Collaborative Filtering
: 실제 행동을 기반으로 추천하는 모델로, 컨텐츠 베이스보다 높은 성능을 보인다.
그러나 행동 데이터가 축적되기전에는 정확도가 떨어진다는 “cold-start” 문제를 갖고 있다.
- 최근접 이웃 기반(nearest neighbor based collaborative filtering)
- 잠재요인 협업 필터링 (latent factor based collaborative filtering) - SVD
※ Deep Learning을 활용한 방식이 최근 핫하지만, 여기선 기초적인 추천시스템 내용의 정리를 위해 배제하였다.
<데이터 종류>
Explict Data
- 평점등 선호와 비선호가 명확하게 구분
- 아직 평점을 매기지 않은 데이터는 활용불가
Impolicit Data
- 선호와 비선호 구분없이 행동의 빈도수만 기록
- 모든 데이터를 사용하여 분석 가능
—
2. Contents Based Filtering
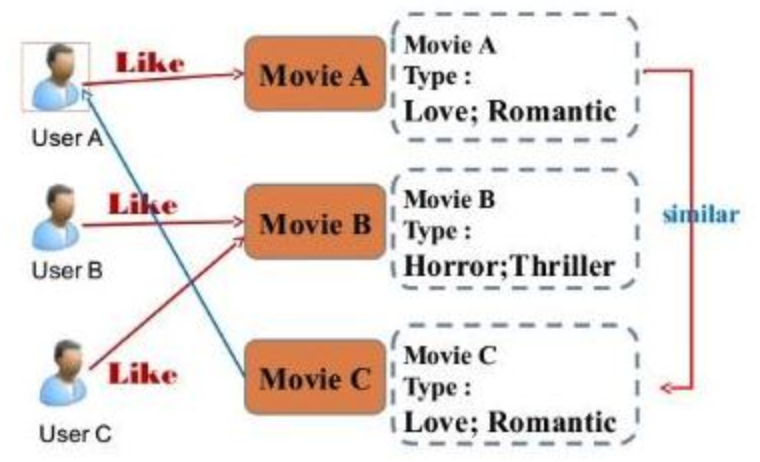
: 위 그림 처럼 예를들어 ‘장르’라는 변수를 활용해 비슷한 영화를 묶고, 동일한 장르내에서 유사한 영화를 추천해줄 수 있다.
3. Collaborative Filtering
3-1. Neighborhood CF Model
: 주어진 평점 데이터를 가지고 서로 비슷한 유저 혹은 아이템 찾기
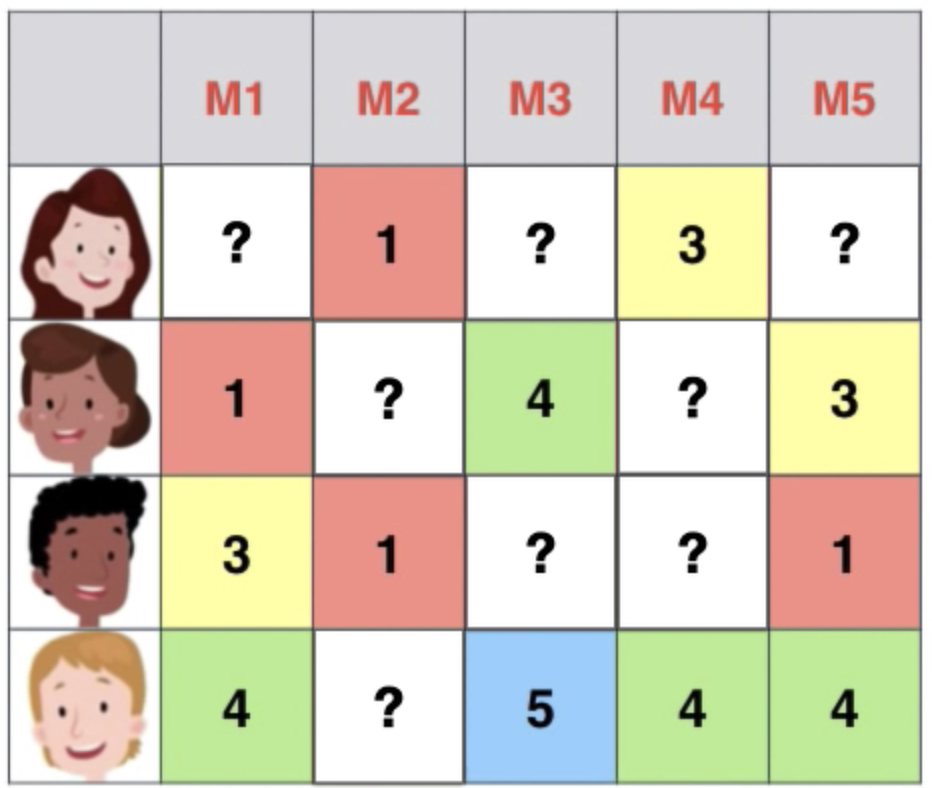
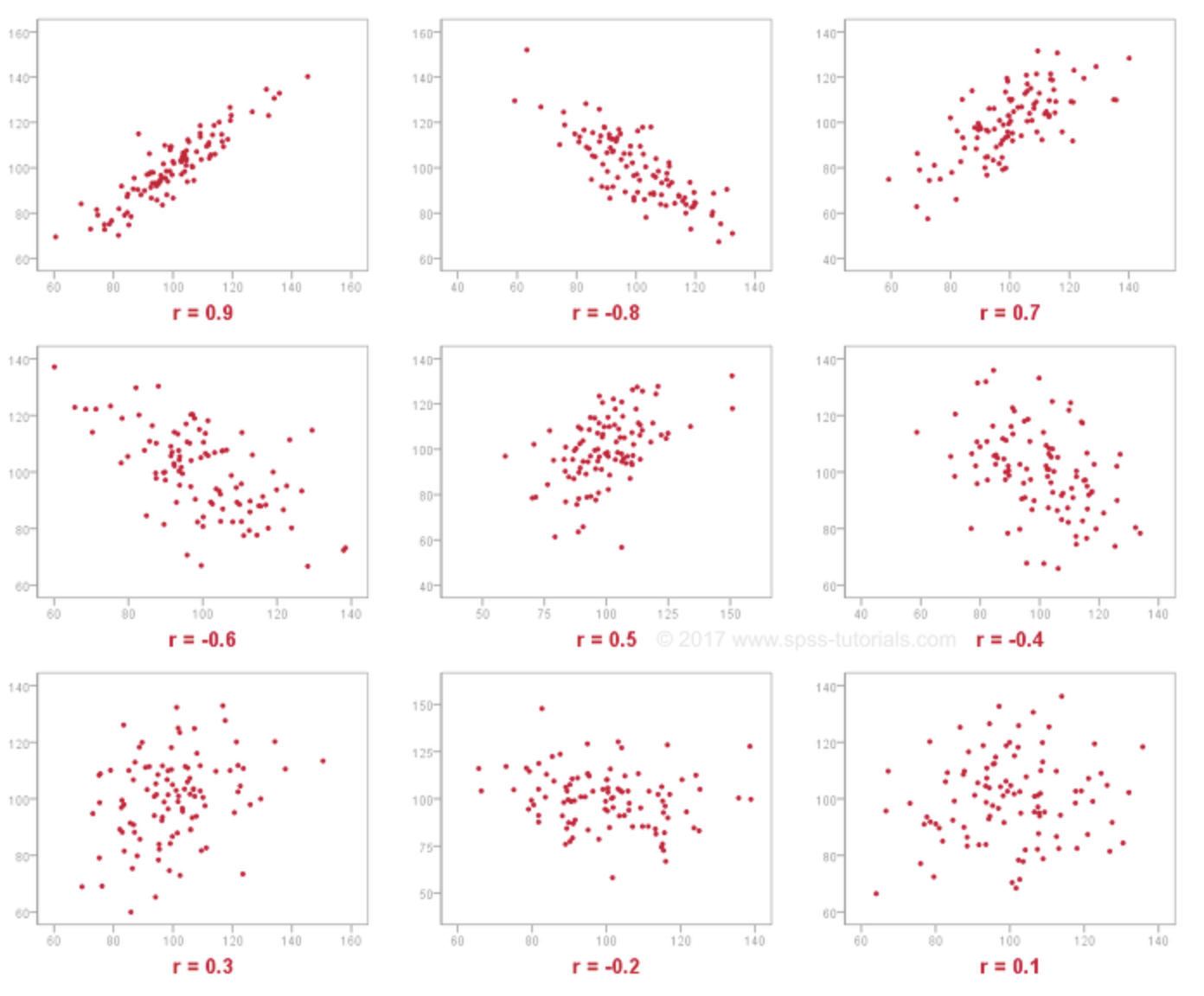
- pearson correlation : 1에 가까울 수록 유사한 선호
- ‘User-oriented Neighborhood’ & ‘Item-oriendted Negiborhood’
- 양/음의 관계를 계산하기에 선호와 비선호가 구분되어 있는 Explicit Dataset에 적합
3-2. latent factor based CF Model(feat.SVD)
잠재요인 협업 필터링
: 주어진 사용자 평점(또는 관람) 데이터를 잠재요인을 기준으로 ‘사용자 정보 행렬’과 ‘아이템 정보 행렬’로 분해하여 각각의 행렬을 사용해 사용자간 유사도와 아이템간 유사도를 계산할 수 있다. 또한 두 행렬을 다시 내적하여 이전에 사용자가 선호를 남기지 않은 항목에 대해서도 예측값을 제공해 줄 수있다.
- U(‘사용자-잠재요인’) & Sigma(잠재요인) & vT(‘아이템-잠재요인’)
Reference
[1] https://dc7303.github.io/python/2019/08/06/python-memory/
[2] https://yeomko.tistory.com/6?category=805638