28 Sep 2020
Word2vec
: 본 포스팅은, 쉽게 씌어진 word2vec 블로그를 공부하며 정리하기 위해 작성되었습니다.
1. 단어 -> 숫자
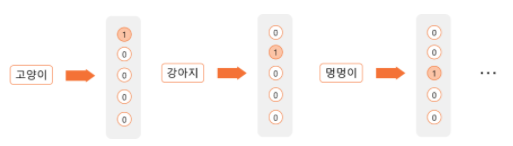
1) one hot encoding
: 각 단어를 하나의 Feature로 활용해, 해당 단어가 속하는 Feature에만 1을 매기며, 나머지는 0으로 채우는 방법
- 장점 : 표현이 쉬움.
- 단점 : 단어와 단어간 관계가 전혀 드러나지 않음
- e.g. ‘강아지’ & ‘멍멍이’ 두 단어는 사실상 유사한 단어이나, 서로 다른 독립적인 feature로 인식됨
=> 단어와 단어간 관계를 벡터 공간상 위치로 표현하기 위한 시도 등장 => *‘word embedding model
2) Embedding test
한국어 Word2Vec
단어를 벡터간 위치값으로 변환시, 덧셈 & 뺄셈이 가능해짐. 위 사이트에서 단어와 단어를 빼거나 더했을 때 벡터간 위치의 변화로 인해 어떻게 의미가 변화하는지 경험해 볼 수 있음(e.g. “한국 - 서울 + 도쿄 = 일본”)
2. Sparse vs Dense Representatios
- feature representation : 대상을 표현 하는 방식으로, 자연어 처리의 경우 특정 ‘텍스트’를 판단하기 위해 해당 단어와 함께 등장하는 단어, 단어의 길이, 단어의 위치, 함께 쓰인 품사 등이 특정 ‘텍스트’를 표현하고 있는 언어적 정보가 될 수 있다. 이같은 속성에는 크게 Sparse representation과 dense representation으로 존재.
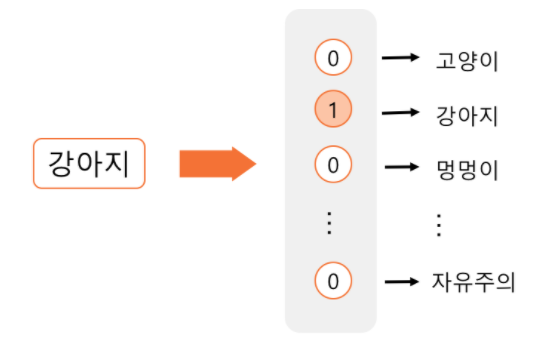
1) Sparse representation
: one hot encoding or dummy variable,
- 단어의 표현 : 표현해야 하는 단어의 수 N개일 때 -> N차원의 벡터 생성 후 해당 단어에만 1표시
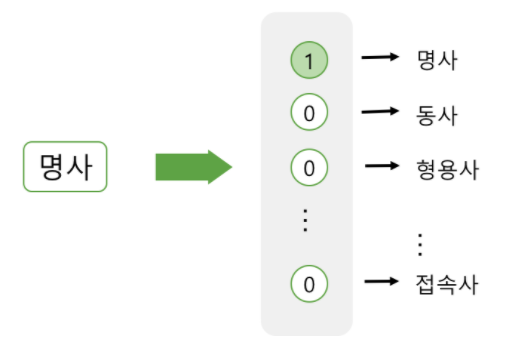
- 품사의 표현 : 모든 품사의 개수 만큼의 차원 생성 -> ‘명사’에 해당하는 벡터의 요소값만 1표시
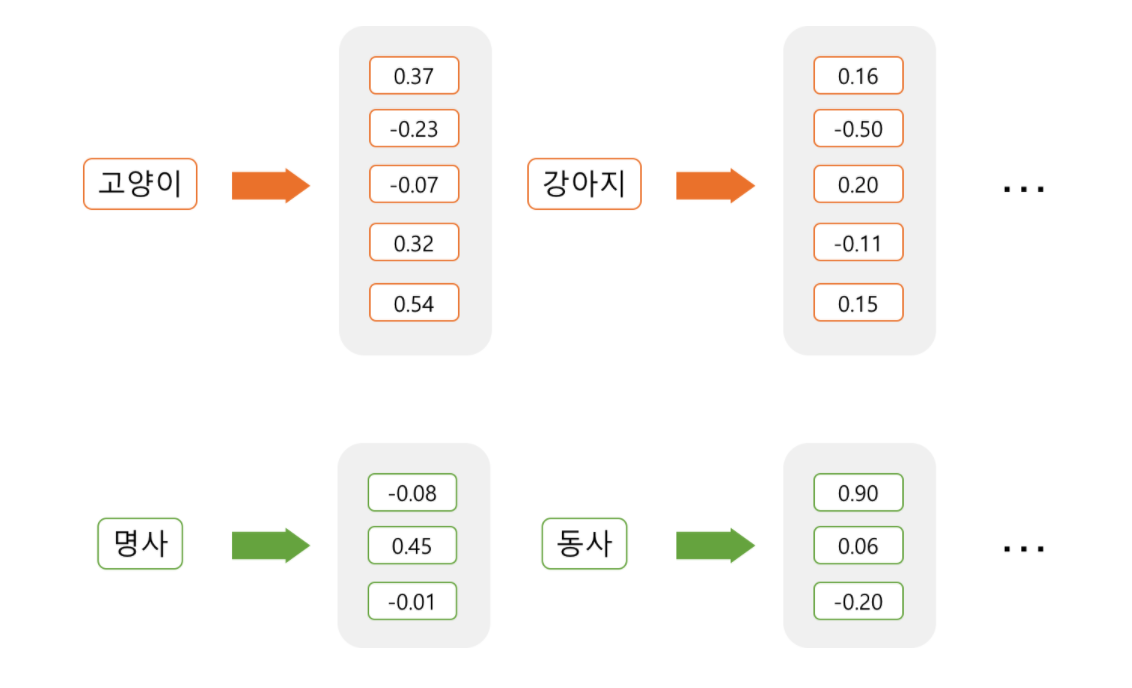
2) Dense representation : Embedding
: 설정한 차원의 개수로 특정 단어를 대응시켜 표현. 이때 각 단어를 주어진 차원에 어떻게 표현할 것인지를 학습. 이렇게 임베딩된 단어는 설정된 각 차원에 값을 갖고 있기에 더이상 sparse하지 않고 모든 열에 값이 채워지며 아래 방식으로 불림.
- 값이 채워져 있음: “Dense”
- 각 차원에 단어의 의미가 분산 됨 : “Distributed”
3. Dense Representation의 장점
(1) 차원이 저주 방지
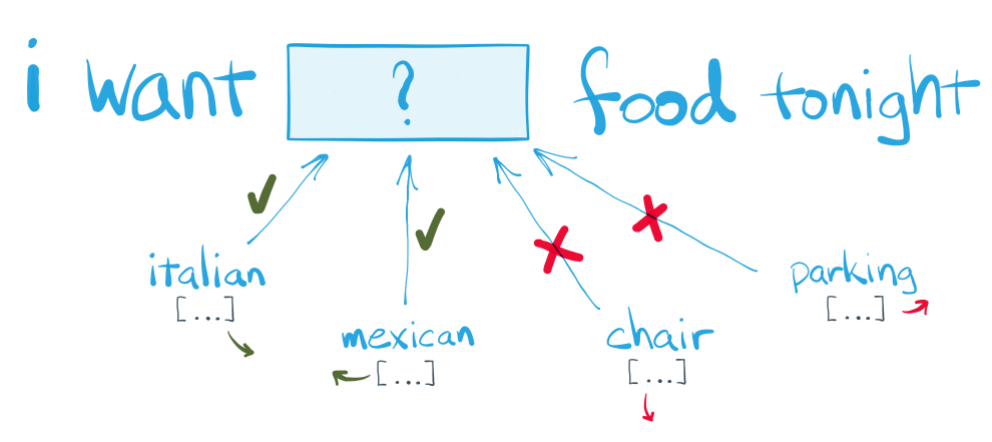
4. word2vec 핵심 아이디어@
: “단어의 주변을 보면 그 단어를 안다.”
 위 문장에서 food와 어울리는 단어는 빈칸에 들어가도 되지만, chair & parking등은 어색함.
-> 비슷한 맥락을 갖는 단어는 비슷한 벡터를 부여
위 문장에서 food와 어울리는 단어는 빈칸에 들어가도 되지만, chair & parking등은 어색함.
-> 비슷한 맥락을 갖는 단어는 비슷한 벡터를 부여
- word2vec -> predictive method 방식
: 맥락으로 단어를 예측 / 단어로 맥락을 예측
- Unsupuervised learning
: 어떤 단어와 어떤 단어가 비슷한지 주어진 문장을 토대로 스스스로 학습
5. Algorithm of word2Vec
1) CBOW(Continuous Bag of Words): 맥락으로 단어 예측
2) Skip-gram(Continuous Bag of Words): 단어로 맥락을 예측
(1) CBOW
: 주변 단어로 타겟 단어를 예측하는 방법으로, 주변 단어를 인풋(X)으로 넣어가며, 파라미터를 학습해 타겟 단어를 벡터방식으로 표현
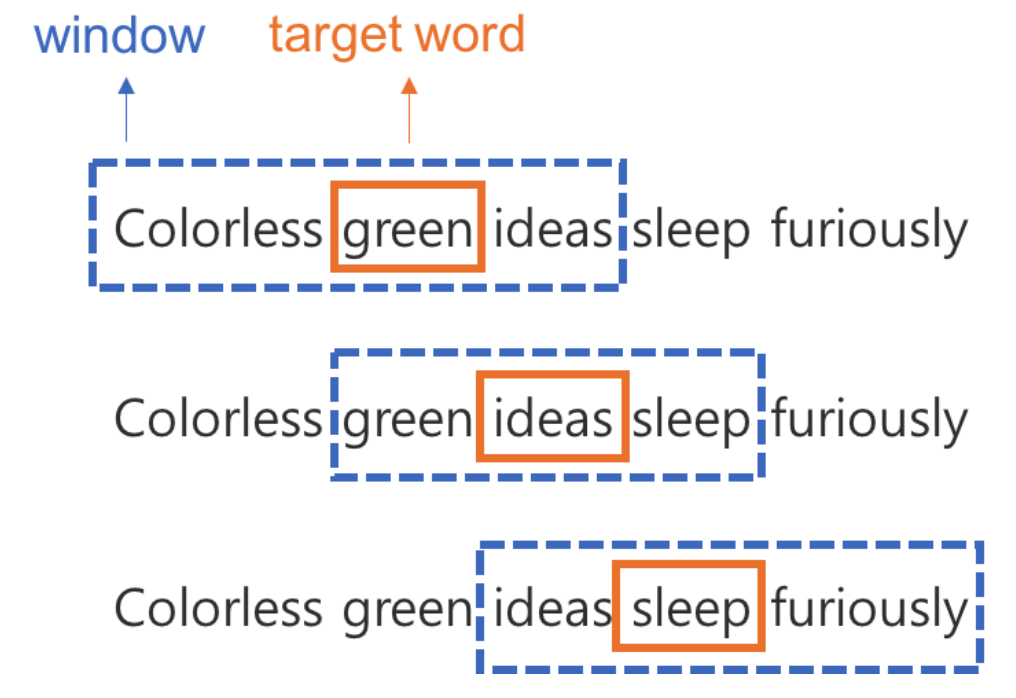
(a) 구성
- Window : 주변 단어, 맥락(Context)
- Window Size : 앞 & 뒤 몇개의 단어를 살펴볼 것인가
- Target word : 타겟 단어 <img src = '/assets/DL/word2vec/word2vec_OHE_7.png' width = '50%'>
(b) 학습 방식
-
- Sliding Window
- window를 옆으로 밀면서, target 단어를 하나씩 바꿔가는 방식으로, 모든 단어에 대해서 학습해 나감
-
- backpropagation & gradient descent
- 딥러닝 방식과 동일하게, 랜덤하게 초기화(random initialization)된 파라미터로 시작하여, 이 파라미터로 예측한 값이 틀릴 경우, 오차를 수정하는 과정을 반복(backpropagation & gradient descent)
(c) 의의
: 주변 단어가 입력값이 될때, 타겟 단어가 서로 다르더라도 주변 단어의 입력값이 서로 유사하다면,
해당 타겟 단어들은 서로 유사한 벡터값을 지정받게 될 것이며, 이는 벡터간 거리가 짧다는 의미가 된다.
6. Mathmatical meaning of word2Vec
- 문맥(input)을 바로 앞 단어 하나라고 가정(window size = 1)
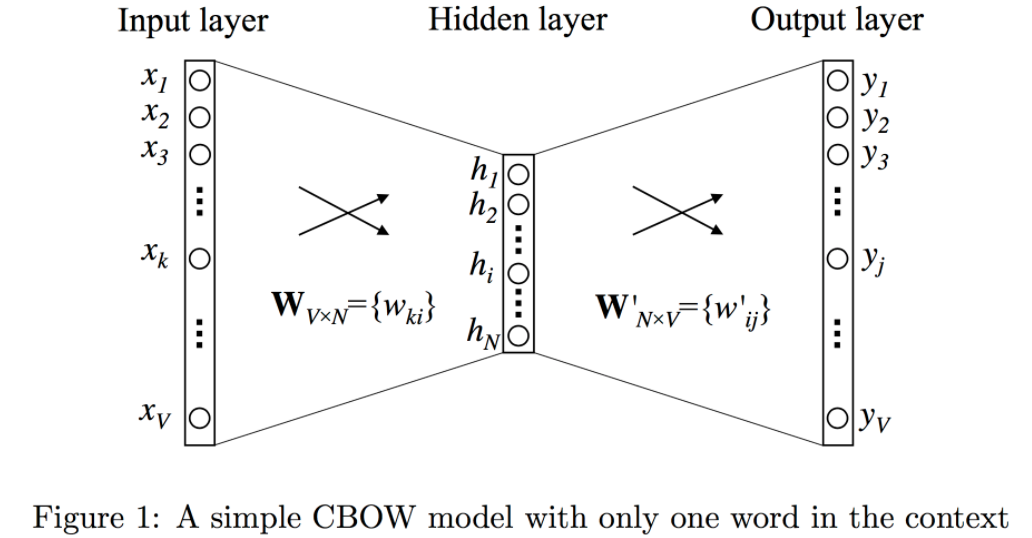
- V : 사전의 크기(vocabulary size) => 단어의 개수
- N : 히든 레이어 크기(hiddn layer size) => 몇차원으로 임베딩할 지의 크기(embedding size)
: OneHotEncoding된 벡터로, 타겟 단어의 앞 단어는 v개의 요소 중 단 하나의 요소만 1, 나머지는 모두 0인 1xV차원의 벡터입니다.
: 위에서 받은 OHE형태의 Input 행렬은 설정된 임의의 크기(N)의 hidden layer로 투영(projection)되기 위해 W행렬($W_{V*N}$)과 곱해집니다.
Step 3 : Hidden layer h = [1xN]
: Input 행렬에 $W_{V*N}$ 곱해져 1xN 차원의 embedding된 행렬입니다.
$x\times W = W^T_{(i,)} = h$
이때, input행렬은 i번째 값을 제외하고 모두 0인 `[1xV]`행렬이기에,
$[x\times W]$는 $W$행렬의 i번째 행과 동일합니다.(학습대상1)
(window size가 2개 이상이면,
각 h행렬값의 평균 벡터가 h가 됩니다)
$h$ = $(h_1 + h_2) \over 2 \times n(window size)$
Step 4 : $W’$(Weight between hidden & output layer) W' = [NxV]
: 임베딩된 행렬을 토대로, 최종 Output값이 무엇인지 출력하기 위한 가중치행렬입니다.(학습대상2)
$W'_{M\times V} \times h = z $
$softmax(z) = \hat{y},$
Step 5 : Output layer y = 1XV
: 출력은 타겟 단어로, 타겟 단어 바로 앞의 단어가 등장했을 때, 다음으로 등장할 수 있는 모든 단어 v개의 점수이며, 여기에 soft-max를 취해 확률값으로 변환됩니다.
$softmax(z) = \hat{y},$
이렇게 구해진 $\hat{y}$벡터를 스코어 벡터라고 부릅니다.
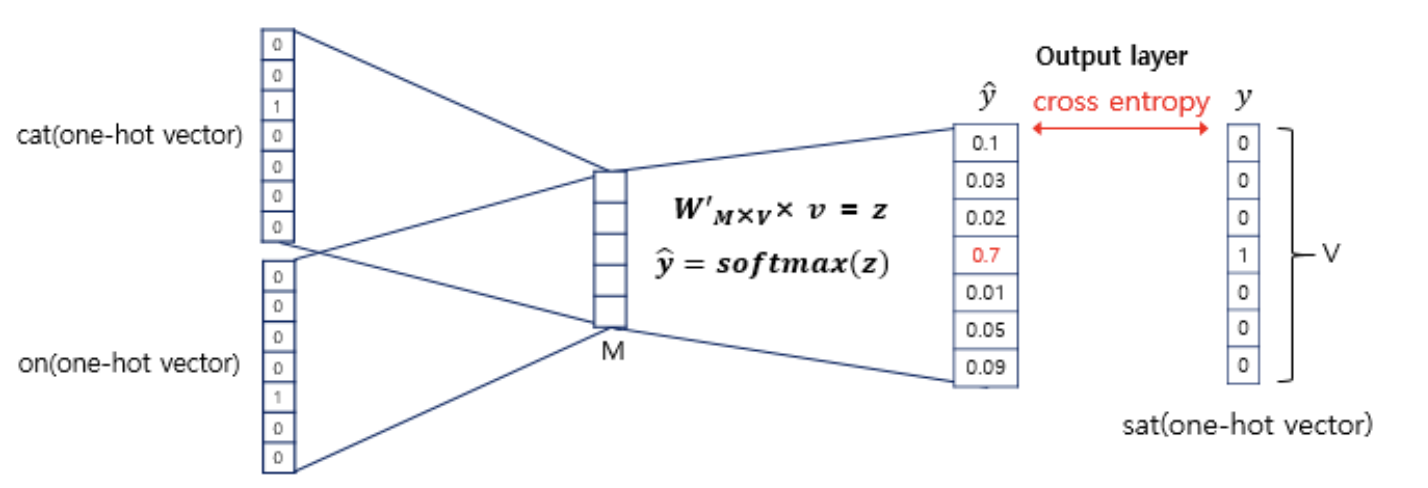 그리고, 계산된 스코어 벡터를 실제 타겟 단어값을 기준으로 OHE된 행렬과 비교하여, 그 차이를 줄이는 방식으로 가중치 행렬($W, W'$)을 학습합니다.
그리고, 계산된 스코어 벡터를 실제 타겟 단어값을 기준으로 OHE된 행렬과 비교하여, 그 차이를 줄이는 방식으로 가중치 행렬($W, W'$)을 학습합니다.
Reference
[1] 쉽게 씌어진 word2vec
[2] 위키독스 : 워드투벡터(Word2Vec)
[3] 한국어 Word2Vec
27 Sep 2020
Deep Neural Networks for YouTube Recommendations
0. Abstract
: 이 글은 딥러닝을 활용한 드라마틱한 성능의 추천 시스템에 대한 논문이다. 해당 방식은 2가지로 나뉘게 되는데, 첫번째는 ‘후보생성 모델(deep candidate generation model)’이며, 두번째는 ‘랭킹 모델(deep ranking model)’이다.
(필자는 현재 주어진 컨텐츠에 대해서 누가 높은 레이팅을 줄 것인지만 다루고 있기에 두가지 모델중 랭킹 모델에 관련된 컨텐츠만을 읽었다…)
1. Introduction
: youtube는 세계에서 가장 큰 영상 플렛폼으로, 개인화된 영상을 제공해 주는데 있어 아래와 같은 3가지 주요 쟁점을 갖고 있다.
-
- (1) Scale
- 적당히 적은 규모에서 잘 작동하던 증명된 추천 알고리즘들도, youtube의 거대한 스케일의 데이터에서는 성능이 나오지 못했다. 이 때문에 매우 특별하게 분산된 학습 알고리즘 및 효율적인 서비스 시스템은 필수적이었다.
-
- (2) Freshness
- YouTube는 매초 수십시간의 영상이 새롭게 업데이트되기에, 각 유저의 최근 행동에 따라 새로운 컨텐츠도 벨런스 맞게 추천해줄 수 있어야 했다.
-
- (3) Noise
- 사용자의 행동을 예측하는 것은 관측되지 않은 외부 요인들에 대한 sparsity와 variety 때문에 근본적인 어려움을 갖고 있다. 때문에
2. System Overview
: 전반적인 시스템은 두가지 neural Networks으로 구성된다.
4. Ranking
: ranking 모델의 주요 목표는 데이터를 specialize & calibrate(눈금을 매기다) 시키는 것입니다.
랭킹 모델을 통해서 우리는 후보 생성 모델을 통해 걸러진 몇백개의 영상에 대해서 유저와 사용자간 더 많은 특징들에 주목했습니다. 랭킹 모델은 또한 서로 다른 후보의 출처들은 각 점수를 직접 비교할 수 없기에 이를 앙상블하는 것에도 중요하게 생각했습니다.
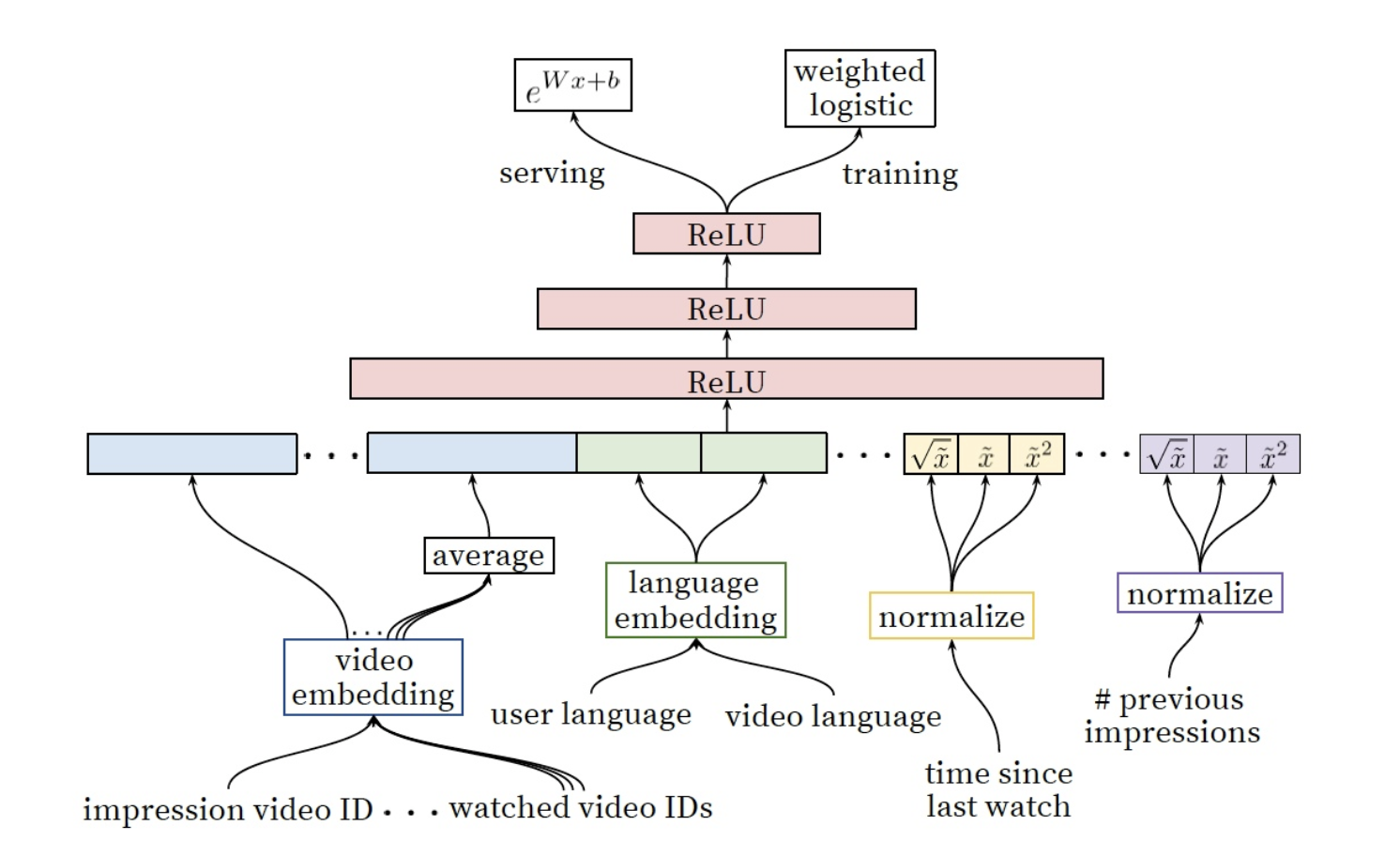
4-1) Feature Representation
: 우리의 Feature들은 전통적인 categorical & continuos/ordinal변수 분류법들과는 차별적인 방식을 지닙니다.
- categorical : binary(e.g. 로그인 여부) or millions of multi class(e.g. 검색 기록)
- single value => univalent (e.g. 비디오 구분값)
- set of values => multivalent (e.g. 유저가 시청한 N개의 비디오 ID값들의 목록)
우리는 또한 변수가 아이템을 묘사하는 것인지 또는 사용자/context(‘query’)를 묘사하는지에 따라 구분했습니다.
(1) Feature Engineering
: 비록 딥러닝이 수많은 변수를 수동으로 핸들링 하지 않아도 되는 장점을 지니고 있으나, 우리가 갖고 있는 데이터를 그대로 input으로 넣어 feedforward neural network를 진행하기엔 무리가 있었다.
가장 중요한 문제는 Temporal sequence of user actions에 대한 표현과 이를 어떻게 스코어로 연결짓는 것인가였다.
[e.g. of Temporal sequence of user action]
- channel : 해당 채널에서 얼마나 많은 영상을 사용자가 시청했는가(like 구독 여부)
- the last time the user watched on this topic : 해당 이슈에 대해서 언제 마지막으로 시청했는가
- candidate generation : 어떤 소스들이 이 영상을 후보군에 포함시키는데 일조하였는지
- frequency of past video impression : 과거 시청 빈도를 통해 이탈(churn)예
=> 위의 사항들이 고려된 feature engineering이 필요함
(2) Embedding Categorical Features
: sparse한 categorical feature를 neural network에 적합한 dense형태로 변화하기 위해 Embedding을 활용.
Embedded unique ID space(‘vocabulary’)
- number of Dimension : 각 고유 ID 공간은 별도의 학습된 임베딩 공간을 갖으며, 이때 공간의 차원수는 유니크한 고유 값(number of unique)수의 로그에 대략 비례하여 증가하는 차원수를 갖는다.(e.g. 1000개의 유니크한 단어가 존재할 시, log1000을 차원수로 설정)
- Top N : 매우 큰 ID space를 줄이기 위해, 클릭수를 기준으로 Top N개의 단어 id만 사용
- 사전에서 찾을 수 없는 단어는 0으로 임베딩 처리
- 다중값 범주형 임베딩(multivalent)은 네트워크에 들어가기전에 평균값 처리
- 동일한 ID space 공간내의 카테고리 변수는 동일한 embedding공간에 놓인다.
e.g. 독특한 특징을 지닌 영상의 Id들은 단일 글로벌 임베딩(video ID of the imporessio, last video ID watched by the user, video ID that ‘seeded’ the recommendation)
- 동일한 임베딩을 공유하더라도, 각각의 feature는 네트워크에 들어갈 때 독립적으로 들어가, 레이가 각 feature들에 특화되어 학습할 수 있도록 한다.
- 임베딩을 공유하는 것은 모델의 일반화(generalization)를 위해 중요하며, 학습 속도를 향상시키고 더 많은 메모리를 절약할 수 있다.(32차원에 임베딩된 100만 id고유값은 2048개의 fully connected layer보다 7배 이상 많은 파라미터를 갖는다.)
(3) Normalizing Continuous Features
: 신경망은 input값의 분포와 스케일 문제에 민감하기로 악명이 높은 반면, 대안적 접근법인 의사결정나무(decision trees)는 개별 feature의 스케일 문제에 둔감하다.
우리는 적절한 평준화(Normalization)가 연속변수의 수렴에 있어서 굉장히 중요하다는 걸 알게 되었다.
f분포를 갖고 있는 연속변수 $x$는 누적 분포를 활용해 value의 스케일에 따라 0~1사이 동등한 분포를 갖는 $\tilde{x}$로 변환된다.
더불어 원본인 $\tilde{x}$에 $\tilde{x^2}$ or $\sqrt{\tilde{x}}$등을 적용해 더욱 강력한 네트워크를 만들기도 하였으며, 이때 제곱항을 적용하는 것이 오프라인 성능을 향상시키기도 하였다.
[ALS_test_code Link](https://github.com/TaeHwanYoun/taehwanyoun.github.io/blob/master/test_code/ALS%20Implementation.ipynb)
Reference
[1] Yifan Hu et al. Collaborative Filtering for Implicit Feedback
[2] 갈아먹는 추 알고리즘 [4] Alternating Least Squares
08 Sep 2020
: 로그 데이터를 다루다보면, 사용자가 언제 접속하는지, 얼마나 또는 얼마만에 접속하는지 등 시간에 관한 변수를 생성해야 하는 경우가 많다. 그러나 앱/사이트 별로 수집되는 time 변수의 format이 매번 다른 경우가 많기에 이를 핸들링해야하는 상황이 자주 생기게 되기에, time변수를 핸들링하는 방법들에게 대해서 정리해보고자 한다.
: datetime 또는 strptime 함수를 사용하여, 인자로 해당 String의 format을 넣어주면 datetime으로 바꿀 수 있다.
from datetime import *
# 1) datetime
date_time_str = "20120213"
date_time_obj = datetime(year=int(date_time_str[0:4]),
month=int(date_time_str[4:6]),
day=int(date_time_str[6:8]))
print(type(date_time_obj)) # <class 'datetime.datetime'>
# 2) strptime function
## yyyymmdd -> datetime
date_time_str = "20120213"
date_time_obj = datetime.strptime(date_time_str, '%Y%m%d')
## yy/mm/dd -> datetime
date_time_str = '18/09/24'
date_time_obj = datetime.strptime(date_time_str, '%y/%m/%d')
print(type(date_time_obj)) # <class 'datetime.datetime'>
## yy.mm.dd -> datetime
date_time_str = '18.09.24'
date_time_obj = datetime.strptime(date_time_str, '%y.%m.%d')
print(type(date_time_obj)) # <class 'datetime.datetime'>
## yyyy.mm.dd str -> datetime
## : 4글자 형태의 연도는 %Y 대문자로 format 지정
date_time_str = '2018.09.24'
date_time_obj = datetime.strptime(date_time_str, '%Y.%m.%d')
print(date_time_obj) # 2018-09-24 00:00:00
2. Calculate dateTime
:datetime type은 timedelta 함수를 활용해 날짜를 변경할 수 있다.
date_time_obj = datetime.strptime('18.09.24', '%y.%m.%d')
date_time_obj = date_time_obj - timedelta(days=10)
print(date_time_obj)
date_time_obj = date_time_obj + timedelta(minutes=80)
print(date_time_obj)
# 2018-09-14 00:00:00
# 2018-09-14 01:20:00
3. Get Y/M/D H/M/S Weekday
:datetime type에서 원하는 날짜 정보만을 출력하는 방법
# datetime
date_time_str = "20120213 180930"
date_time_obj = datetime.strptime(date_time_str, '%Y%m%d %H%M%S')
# Date : Y/M/D
print('Date : {}'.format(date_time_obj.date()))
print('Year : {}'.format(date_time_obj.year))
print('Month : {}'.format(date_time_obj.month))
print('Day : {}'.format(date_time_obj.day))
# Date : 2012-02-13
# Year : 2012
# Month : 2
# Day : 13
# Time : H/M/S
print('Time : {}'.format(date_time_obj.time()))
print('Hour : {}'.format(date_time_obj.hour))
print('Minute : {}'.format(date_time_obj.minute))
print('Second : {}'.format(date_time_obj.second))
# Time : 18:09:30
# Hour : 18
# Minute : 9
# Second : 30
# weekday
print('Weekday : {}'.format(date_time_obj.weekday()))
print('Weekday by string: {}'.format(date_time_obj.strftime('%A')))
# Weekday : 0
# Weekday by string: Monday
: date 객체의 정보를 ‘YYYY-MM-DD’ 형태의 문자열로 반환하며,
월을 12개월의 월이 아닌, 누적 주의 수로 표현 가능하다.
date_time_now = datetime.now()
print('ISO format : {}'.format(date_time_now.isoformat())) # iso format을 사용하면, 월요일을 1부터 시작한 값으로 반환해준다
print('ISO Weekday : {}'.format(date_time_now.isoweekday())) #
print('ISO calender : {}'.format(date_time_now.isocalendar())) # (YYYY, num_week, weekday)
# ISO format : 2020-09-20T19:02:11.213896
# ISO Weekday : 7
# ISO calender : (2020, 38, 7)
5. Apply dateTime type to Columns
: 컬럼에 dateTime type을 적용하는 방법을 살펴보자
# 1) column type to 'datetime65[ns]' (시,분,초)
## "20120213" -> 2012-02-13 00-00-00
df['date'] = pd.to_datetime(df['date'], format='%Y%m%d')
# 2) column type to 'date'(날짜)
## "20120213" -> 2012-02-13
df['date'] = pd.to_datetime(df['date'], format='%Y%m%d').dt.date
Reference
[1]https://www.programiz.com/python-programming/datetime/strftime
[2] https://devanix.tistory.com/306
28 Aug 2020
: 모델의 성능을 평가하다보면, 종종 RMSE와 MSE를 함께 사용하는 경우를 볼 수 있습니다. 둘다 오차의 크기를 재기위한 방법인데, 서로 어떤 차이가 있고 함께 사용했을 때 어떤 장점이 있는지 비교해보고자 합니다.
1. RMSE(Root Mean Square Error)
: RMSE(평균 제곱근 오차)는 회귀 문제의 성능 지표로 주로 활용된다.
$RMSE = \sqrt{ \frac{1}{m} \sum_{i=1}^m(h(x^i) -y^i)^2}$
2. MAE(Mean Absolute Error)
: 평균적인 오차의 크기를 나타내는 값으로, 이때 오차의 방향성은 고려하지 않는다.
$MAE = \frac{1}{m} \sum_{i=1}^m|h(x^i) -y^i|$
3. RMSE vs MAE
: 얼핏 보면 두 지표 모두, 예측값과 실제값 사이의 오차의 거리를 측정하기 위한 지표로 큰 차이가 보이지 않는다. 그렇다면 굳이 두 지표를 함께 쓴느 이유는 무엇일까.
RMSE는 평균값을 계산하기 앞서, 오차에 제곱항을 씌워주기에 상대적으로 오차가 큰 값들을 더욱 크게 만드는 효과가 있다. 이점 때문에 모델 성능 평가에 있어서 RMSE를 사용할 시 작은 오차는 작게, 큰 오차는 크게 여길 수 있다는 특징이 있다.
나아가 RMSE는 항상 MAE보다 크거나 같으며, RMSE가 MAE와 같다면 모든 예측값과 실제값사이의 오차의 크기가 동일하다는 이야기가 되며,
MAE 대비 RMSE가 상대적으로 큰 값을 갖는다면, 이는 상당히 큰 오차값들이 존재함을 의미한다.
Reference
[1] Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE)
[2] https://mjdeeplearning.tistory.com/30
22 Aug 2020
아무도 아닌
아무도 아닌, 을 사람들은 자꾸 아무것도 아닌, 으로 읽는다.
上行
시골에서 살면 좀 나을까 싶어서 알아보러 내려온 거거든. 나, 도시에서 사는 건 이제 싫다. 육 개월 단위로 계약서 써가며 일해봤냐. 사람을 말린다. 옴짝달싹 못하겠어. 마땅하지 않은 일이 생겨도 직장에서 한마디 할 수 있기를 하나. 눈치만 보게 되고 보람도 없다. 계약서 갱신할 날이 다가오면 가슴만 이렇게 뛴다. 다 때려치우고 이런 곳에서 한적하게 살아볼까 싶었는데 만만치 않네. 시골에서도 뭐가 있어야 산다잖냐. 내가 참, 뭐가 없는 놈이구나, 이런 생각만들고, 괜히 왔다.
-27p-
노부인이 내 얼굴을 바짝 들여다보고 말했다.
자고 가.
밥 줄게.
누군가 도와줬으면 해서 둘러보았지만 오제도 오제의 어머니도 짐을 확인하느라고 바빴다. 뭐라 대답해야 할지 몰라 서 있다가 다음에 와서 자고 갈게요, 라고 말했다. 몇 겹으로 왜곡된 안경 속에서 노부인의 눈이 슬프게 일그러졌다.
다음에 오냐.
네.
정말로 오냐.
네.
나 죽기 전에 정말로 올테냐.
…..
오긴 뭘오냐 니가, 라고 토라진 듯 중얼거리는 노부인 앞에서 안하느니만 못한 말이자 약속도 안니 약속을 해버린 나는 얼굴을 붉혔다.
-33p-
나는 잠자코 조수석에 앉은 채로 월식을 생각했다. 한 번도 그걸 본 적이 없었다. 보자고 굳게 마음을 먹어도 언제나 잊었다. 이번에야말로, 라고 나는 다짐했으나 막상 그 시간이 되면 내가 어디서 무엇을 하고 있을지, 나도 알 수 없었다.
-35p-
양의 미래
호재의 곁에서 나는 몇 번인가 내 아버지 이야기를 했다. 묵묵히 어머니를 돌보는 아버지. 남성성이 완전히 사라진 듯한 모습으로, 아버지라기보다는 할머니 같은 모습으로 집안 살림을 하는 왜소한 체구의 아버지.
어머니가이제 죽었으면 좋겠어.
아버지도.
이런 이야기를 내가 했을가. 내가 정말로 했을까. 둘 가운데 어느 이야기를 했고 어느 것을 하지 않았는지는 확실하지 않다. 둘 다를 하지는 않았어도 둘 가운데 하나는 했을 것이다. 평생 아이를 만들지 않을 거라고 내가 말했을 때 호재는 왜냐고 묻지 않았으니까.
-46p-
화단엔 늘 고양이가 몇 마리 있었다. 고양이들은 사라졌다가 다시 나타나고는 하며 밥을 먹고 갔다. 화단에서 밥을 먹고 자란 암컷들은 새끼를 배면 화단으로 돌아왔다. 어미 고양이와 새끼들. 그들이 바꿔가며 어디론가 갔다가 돌아오곤 하는 동안 호재의 우산은 그대로 관목 위에 펼쳐져 있었다. 낡은 우산살 위로 우산 천이 말려 올라간 모습으로 말이다.
-48p-
…마침내 중간 선반에서 바짝 마른 걸레로 덮인 망치를 찾아냈다. 그걸 쥐고 그 벽 앞에 섰다. 습기와 곰팡이가 덩굴무늬처럼 번진 벽 귀퉁이를 바라보았다. 그러고 있는 와중에도 벽 너머에서 불어오는 바람이 느껴졌다. 그가 모를 뿐 터널은 있다. 봐. 바람이 분다. 터널을 관통하는 바람이 이렇게. 나는 그걸 확인할 수 있었다. 망치를 들어서 몇 번 휘두르면 가능했다. 어쩌면 계란 껍데기를 뚫는 것처럼 쉬울 수도 있었다. 그리고 바로 그때문에 나는 그렇게 할 수 없었다.
터널이 있는 것과 터널이 없는 것.
…
나는 그걸 알 수 없었고 아마 앞으로도 알 수 없을 것이다. 나는 그냥 망치를 쥔 채로 벽 앞에 서 있다가 내 도시락이 놓인 박스 곁으로 돌아갔다.
-58p-
가난하고 돌보아줄 인연 없는 늙은 자로서 병들어 죽어가는 것처럼 비참한 일이 있을, 생각한다. 저자는 이런 죽음을 두고 여태껏 인류가 발명한 어느 무기도 그런 형태의 자연사만큼 사람을 강력하게 비참하게 만드는 것은 없었다고 말하고 있었다. 때문에 그는 늙어 죽는 것을 소망한 것이 아니고 길 가다 우연하게, 느닷없이 죽고 싶다고 써두었다. 나는 그의 문장 곁에 그렇다, 라고 적은 뒤 연필 끝으로 종이를 꾹꾹 누르고 있다가 이렇게 덧붙였다.
-60p-
상류엔 맹금류
그러나 어느 엉뚱한 순간, 예컨대 텔레비전을 보다가 어떤 장면에서 그가 웃고 내가 웃지 않을 때, 그가 모는 차의 조수석에앉서 부쩍부쩍 다가오는 도로를 바라볼 때, 어째서 이 사람인가를 골똘히 생각한다.
어쩌서 제희가 아닌가.
그럴 땐 버려졌다는 생각에 외로워진다. 제희와 제희네. 무뚝뚝해보이고 다소간 지쳤지만, 상냥한 사람들에게.
명실
그녀에게는 갓난아기의 도톰한 발을 쥐고 엄지로 발바닥을 문지르며 감탄한 기억이 있었다. 굳은살이라고는 조금도 없는 말랑한 살에 관한 기억이었다. 직립과 보행을 아직 경험하지 않은 인간의 발. 누구나 이런 발을 가지고 태어나는데…. 일단 일어서서 걸음을 걸음을 배우게 되면 달라지지. 완전히 다른 조직인 것처럼 발바닥도 뒤꿈치도 딱딱해져… 그게 너무 서글프다고 생각하며 그 작은 발을 한참 만닌 기억이 있었다.
-95p-
그녀가 가진 것은 파편들이었다. 문장이라기보다는 목소리였고 모으려고 할수록 멀어지고 흩어지는 메아리들이었다. 실리의 이야기들은 책이 되지 못했다.
-99p-
실리는 늘 다루곤 하는 사물에 특별한 애착을 품었고 종종 그런 사물들에 정서가 있다고 우겼다. …. 혹시나 그런 장소에서 물건을 잃어버리는 일이 생기면 낯선 곳에서 그 물건이 무엇을 느낄지, 그래 정말 무엇을 느낄지, 그 조그만 사물이 난데없이 그 자리에 홀로 남아 얼마나 애가 타고 허탈할지, 그런 것을 다 속상해하고는 했다. 본인이 혼자가 되는 것을 두려워했기 때문이지, 하고 그녀는 생각했다. 실리는 외로움을 많이 타는 사람이었으므로 무언가를 혼자 남겨두는 것에 예민한게 반응했다.
-103p-
그건 꼭 …. 죽은 사람들에 관한 이야기 같다고 그녀가 말하자 실리는 그런가, 라고 대답했다. 죽은 사람이 죽은 사람을 기다리는 이야기. 실리는 그걸 완성하지 못하고 죽었다. 그를 언제 까지고 벌판에 내버려둔 채로 죽고 말았다. 실리의 화자는 내내 벌판에 있는 것이다. 마리코가 ….알아보지 못하고 지나갈까봐 앉지도 못하고 서서.
-105p-
그게 필요했다. 모든 것이 사라져가는 이때.
어둠을 수평선으로 나누는 불빛 같은 것. 저기 그게 있다는 지표 같은 것이.
그 아름다운 것이 필요했다.
그녀는 노트에 만년필을 대고 잉크가 흐르기를 기다렸다. 제목을 적고 쉼표를 그리고 이름을 적었다.
겨울이 얼마 남지 않았다고 그녀는 생각했다.
-111p-
누가
노인이 오 년 동안 머물렀던 방은 벽지도 바닥재도 그대로였다. 바싹 마른 벽에 둥글게 자국이 남아 있었고 그녀는 바로 그 자리에 노인이 머리를 대고 앉았을 거라고 생각했다. 노랗다못해 붉은색을 띤 기름 얼룩. 거기에 머리를 대고 노인은 도대체 뭘 보았을까.
…
그런데 이상하기도 하지. 나는 정당하게 세를 내고 이 집으로 들어왔을 뿐인데 노인을 내쫓았다가는 기분이 든다….. 여기서 나가서 노인은 아마 더 좋지 않은 곳으로 갔을 것이다… 잘 모르면서 그녀는 생각했다. 다른 가능성도 있을 수 있었지만 다른 어떤 가능성보다도 그것이 그녀에게는 더 리얼하게 여겨졌으므로 그게 유일한 가능성인 것처럼 생각되었다. 그렇다고 하더라도… 그게 내 탓인가. 내가 내쫓았나. 그녀는 이불을 발로 차며 돌아누웠다. 노인은 방을 유지할 능력이 없엇을뿐이고 내게는 있었을 뿐. 그냥 그것뿐. 만사가 그뿐.
-127p-
그제는 건너 자리의 상담원이었던 선배의 계약이 해지되었다.
정말로 진심으로 곤란하고 미안하고 당신의 고통에 공감한다는 것처럼 말했지. 안 그랬더라면 좋았을 것이다. 안 그러니까. 안 그러니까 안그랬더라면 좋았을 건데. 그는 그러지 않았지 . 재수없는 새끼 … 고객 같은 놈… 선배가 고개를 숙이고 자기 자리로 돌아갔을 때 그녀는 그 선배의 자리에서 자기 자리까지 남은 거리를 생각하지 않을 수강 없었고 안됐다고 생각했다. 안됐다….거기까지. 그 너머는 벼랑이니까.
누구도 가본적 없는
안장은 어디에 있을까. 세상이 아이에게서 통째로 들어낸 것, 멋대로 떼어내 자취 없이 감춰버린 것. 이제 시작이겠지, 하고 나는 생각했지… 이렇게 시작되어서 앞으로도 이 아이는 지독한 일들을 겪게 되겠지. 상처투성이가 될 것이다. 거듭 상처를 받아가며 차츰 무심하고 침착한 어른이 되어갈 것이다. 그런 생각을 했지….
그 밖에 내가 뭘 더 부탁한 게 있어? 그 거 챙기라고 … 가방에 넣으라고 말하지 않았나? 그거 잊지 말라고 .. 그냥 그거 하나 … 당신은 괜찮지 걱정이 없지 내가 다 하니까… 당신은 잘 먹고 잘 자고…어디서든 …호텔에서든 비행기에서든…어떻게 그럴 수가 있지? 어떻게 그렇게 비위가 좋냐 그렇게 멀쩡하게 괜찮을 거라고? 당신은 어떻게 그렇게 쉬워 모든게…
그는 문득 입을 다물고 고개를 돌려 그녀를 바라보았다. 그녀가 서글픈 얼굴로 그를 보고 있었다. 그는 다시 울화가 치밀어 고개를 저었다. 그 얼굴. 지긋지긋하다고 말하는 대신, 그렇게 보지 말라고 그는 말했다. 그런 식으로 보지 마. 사람 빤히 관찰하지 마. 너는 아무 잘못 없는데 내가 때리기라도 한 것처럼 그렇게.
웃는 남자
나는 이해한다는 말을 신뢰하지 않는 인간이었다. 이해한다는 말은 복잡한 맥락을 무시한 채 편리하고도 단순하게 그것을, 혹은 너를 바라보고 있다는 무신경한 자백 같은 것이라고 나는 생가가하고 있었다. 나 역시 남들처럼 습관적으로 아니면 다른 마땅한 말을 찾지 못해 그 말을 할 때가 있었고 그러고 나면 낭패해 고개를 숙이곤 했다.
그런데 그 밤에 그가 내 등을 두드리며 너를 이해할 수 있다고 말했을 때 나는 진심으로 놀랐고 그 말에 고리를 걸듯 매달렸다. 이 사람이 나를 이해할 수 있다면 나도 해볼 수 있지 않을까. 저날의 나를 내가 이해해 볼 수 있지 않을까. 그것을 할 수 있으려면 무엇부터 하면 좋을까.내가 이제 무엇이 되는 게 좋을까.
단순해 지자.
가급적 단순 한 것이 되자고 나는 생각했다.
-165p-
디디는 부드러웠지 . 껴안고 있으면 한없이 부드러워서 나도 모르게 있는 힘껏 안아버릴 때도 있었어. 이 사람을 행복하게 해주고 싶다고 나는 생각했다. 처음으로 내가 아닌 다른 사람을 행복하게 만들고 싶다고 생각했고, 그 행복으로 나 역시 행복해질 수 있다고 생각했다.
-171p-
디디는 제때 나를 발견하려고 내가 도착할 무렵엔 자주 고개를 들어야 했을 것이다. 한 줄을 읽고 고개를 들어 비탈을 바라보고. 더 행복해지자, 담배와 소변 냄새가 나는 가파른 계단을 올라가며 나는 다짐하고는 했다. 행복하다. 이것을 더 가지자. 더 행복해지자. 다른 것은 아무것도 샏ㅇ각하지 말고 그것 한 가지를 생각하자. 그런 생각을 하며 마지막 계단에 이르면 디디가 햇빛에 빨갛게 익은 얼굴을 하고 마중나와 있었다.
-176p-
디디를 먹어치운 거리. 디디의 목을 부러뜨리고 머리를 터뜨린 거리. 거기엔 의미도 희망도 없어. 죽은 것이나 다름없다. 그러나 여기는 다른가. 내가 지금 머물고 있는 곳, 여기 무엇이 있나. 벌거벗은 벽이 있고 내가 있고 의자가 있고 내 잡동사니가 있다. …..
내가 여기 틀어박혔다는 것을 아는 이 누구인가.
아무도 나를 구하러 오지 않을 것이다.
아무도 나를 구하러 오지 않을 것이므로 나는 내 발로 걸어나가야 할 것이다.
오랫동안 나는 그것을 생각해왔다.
-185p-
복경
다시는 그렇게, 그 남자와 그의 누나처럼 초췌하게 그렇게, 되고 싶지 않다. 살려내고 싶어도 살릴 수 없는 사람이 죽음을 앞두고 고통으로 괴로워하는데 진통조차 해줄 수 없는 형편이라면 그 마음은 뭐가 되겠습니까. 짐슴 아니겠습니까. 짐승이 되어버린 것과 같지 않겠습니까. 그래서 나는 돈을 벌어. 그 짐승이 되지 않으려고 돈을 법니다.
-194p-
도게자.
이렇게 인간이 인간의 발 앞에 무릎을 꿇고 머리를 숙이는 자세를 도게자라고 해. 사람들은 이걸 사과하는 자세라고 알고 있지만 이것은 사과하는 자세가 아니다. 이것은 그 자체야. 이 자세가 보여주는 그 자체.
매장에서 난리치는 사람들은 사과를 바라는 게 아니야. 사과가 필요하다면 죄송합니다 고객님, 으로 충분하잖아? 그런데 그렇게 해도 만족하지 않지. 더 난리지.
실은 이게 필요하니까. 필요하고 바라는 것은 이 자세 자체. 어디나 그래 자기야. 모두 이것을 바란다. 꿇으라면 꿇는 존재가 있는 세계. 압도적인 우위로 인간을 내려다볼 수 있는 인간으로서의 경험. 모두가 이것을 바라니까 이것은 필요해 모두에게. 그러니까 나한테도 그게 필요해. 그게 왜 나빠?
-201p-